KubeCon Europe、2日目のキーノートはSpotifyの失敗事例とIBMのRazeeがポイント
KubeCon Europeの2日目の注目ポイントは、Spotifyの失敗談とIBMの社内ツールRazeeだ。
2019年7月10日 6:48
KubeCon Europe、2日目のキーノートは前日と同様にVMwareのBryan Liles氏のMCで始まった。この日のテーマは「Kubernetes is a Platform for Creating Platforms」ということで、アプリケーションをクラウドネイティブに実行するためのプラットフォームであるKubernetesを、よりインフラストラクチャー寄りの目線で捉えてみようということになった。そこで最初に紹介されたのはSpotifyのユースケースだ。
失敗を活かすSpotifyの事例

タイトルだけで大体内容がわかるSpotifyのプレゼンテーション
タイトルを意訳すると「Spotifyは偶然にも本番環境のKubernetesクラスターを削除してしまったにもかかわらず、ユーザーに支障を与えなかったのはなぜか?」と言ったところだろう。登壇したのはSpotifyのインフラストラクチャーチームのエンジニア、David Xia氏だ。

プレゼンテーションを行うSpotifyのXia氏
結論から言えば、Spotifyのインフラチームとアプリケーションを開発するフィーチャーチームはそれぞれのちょっとしたミスから3つのゾーンに分けて実装していたKubernetesクラスターを、インフラであるGCPから削除してしまったが、エンドユーザーには直接の影響を与えずに復旧することができたという話だ。
KubeConを主催するCNCFは、どうやらキーノートで失敗談を披露するのが好きなようで、2018年のKubeCon EuropeでもイギリスのインターネットバンクのひとつであるMonzo Bankのユースケースが紹介されている。
Monzo Bankの失敗談:KubeConで失敗を紹介したMonzo Bankのキーノート
Spotifyが3つのゾーンに存在するKubernetesクラスターの2つまでを削除してしまっても、エンドユーザーに影響を与えなかった理由の一つは、仮想マシンベースのレガシーなアプリケーションセットがまだ稼働しており、全面的にKubernetes化されていなかったこと。これが最大の要因だろう。

3つのクラスターゾーンのうち2つまでが削除されてしまった
またKubernetesの構成ファイルと、そのインフラストラクチャーを構成するサーバー構成管理ツールであるTerraformに跨る管理情報の整合性、パーミッションの管理などインフラストラクチャーだけではなく、アプリケーションにも関連する様々な要因を十分に理解した上でも、こういう重大なミスが起こってしまうという例となった。この辺りに、Kubernetesの持つ複雑さを従来の仮想マシンベースの構成情報とマッチングする難しさが表れているように思える。

Spotifyの教訓
以前、日本のエンタープライズの取材で「『Infrastructure as code』は便利だが、ゼロから構成を立ち上げるというのはほぼなく、現存するサーバー群に対して何か変更を加えたいことがほとんど。しかし従来のツールは、構成ファイルに書かれたことを忠実に実行するだけで、今動いているシステムとの差分を取って、有るものはそのままに、ないものを生成するという機能がない。結果、欲しいものを全部漏れなく毎回ちゃんと書かないと作ってくれない」というコメントを聞いたことがある。Spotifyのケースも正にその失敗例で、エンジニアがプッシュしたTerraformの構成ファイルに、たまたまAsiaゾーンの構成情報がなかったために、稼働しているサーバーを削除してしまったというものだ。ツールの機能から言えば全く正しい動作であり、ツールベンダーやパブリッククラウドベンダー(この場合はGCP)が責められるべきことではない。

インフラのコード化のポイント
しかしKubernetesであっても結局は稼働するための物理サーバーは必要になるし、パブリッククラウドでもオンプレミスのデータセンターでも「いかに構成情報を正しく管理してミスを防ぐか」という部分に関しては、多くの企業がまだ苦労していることだろう。Spotifyのケースは、レガシーなシステムを並列で持つ、常にバックアップを怠らない、障害時のシミュレーションを実行するという極々普通の内容であり、最先端のインターネット企業であってもやるべきことはあまり変わらないという意味で参考になったと思われる。

最も重要なのは失敗しても責めるのではなく学びと捉えること
Xia氏が最後に紹介したのは、今回の失敗を通じてチームのフィロソフィーが確かになったという部分だろう。「失敗してもそれを責めずに、学ぶことができる機会を作ってくれたと同僚に言われたことが嬉しかった」というコメントがそれを表している。日本の企業にありがちな失敗の先にあるのは「犯人探しと罰則」という発想ではなく、転んでも次にはもっとうまく転ぶ、立ち上がる時間を短くするための練習に転換するという点は、日本にとっての良い教訓かもしれない。
David Xia氏のプレゼンテーション動画:How Spotify Accidentally Deleted All its Kube Clusters with No User Impact - David Xia
Oracle
次に登壇したのは、OracleのVP、Bob Quillin氏だ。Oracleはスポンサーとしてこのセッションを行ったわけだが、Open、Sustainable、InclusiveというこれまであまりOracleの口から出てこなかった単語がサマリーとして出てきたと言う辺りに、Oracleであってもオープンソース的な流れを無視できないといったところだろうか。細かい点だが、WebLogicをKubernetes上で動かすOperatorをOracleが公開しているということが紹介された。

Oracleのまとめ
Oracle WebLogic Server Kubernetes Operator
Conde Nastの事例
次に登壇したのは、Conde Nast InternationalのKatie Gamanji氏だ。ファッション雑誌をメインにしたコンテンツビジネスがメインの企業で、先ほどのSpotifyが失敗例だとすると、Conde Nastは完全に成功例として紹介されていた。
主にAWSをインフラとしてグローバル、特にロシアと中国からのアクセスをこなすために、ヨーロッパ、中国、日本、メキシコ、アイルランドにそれぞれKubernetesクラスターを実装して、2億5500万/月のユニークユーザーからのアクセスさばいていると紹介。中国に関しては、中国国内のクラウドプロバイダーを利用しているようだ。

中国とロシアからのアクセスが多いことを紹介
そしてシステムとしてはKubernetesを中心に、Helm、Calico、Traefik、Fluentd、Kibanaなど、オープンソースプロダクトだけを使用して開発を行っているという。フロントエンドとなるCDNはFastlyで、KubernetesのIngress ControllerはTraefik、CI/CDについてもコンテナレジストリーはRed Hatが買収したCoreOSのQuay、パッケージマネージャーはHelm、CIはCircleCIという構成だ。
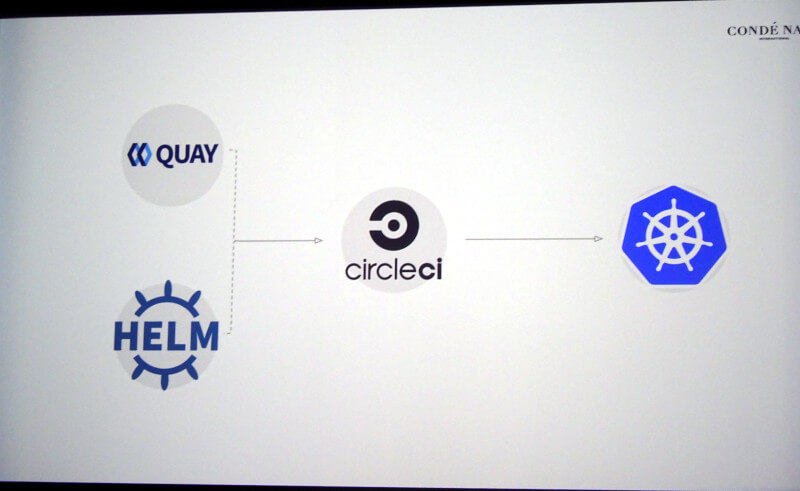
CI/CD環境の構成
しかしなにより驚いたのは、この約13分のプレゼンテーションが全くカンニングペーパーなしに行われたことだろう。通常のプレゼンテーションであれば、ステージ脇のモニターにスライドと話す文章がスクリプトとして流れているものだが、Gamanji氏の場合はスライドだけでスクリプトはなし、つまりスライドの内容を完璧に把握してステージに立っているということになる。この後、会場でGamanji氏に直接確認したところ、スクリプトなしは「別に不思議なことではないわ」という回答だった。1年前にConde Nastに参加したというGamanji氏だが、他の企業がヘッドハントしたがるのではないかと予想したくなる堂々としたプレゼンテーションだった。

プレゼンテーションを行うGamanji氏
Katie Gamanji氏のプレゼンテーション動画:A Journey to a Centralized, Globally Distributed Platform ? Katie Gamanji
IBMが自ら作り活用するツールRazee
次に登壇したのは、IBMのJason McGee氏だ。CTOでIBM Cloud PlatformのVPということで、IBMのクラウド戦略を握るキーパーソンである。McGee氏はIBM自身がKubernetesを使ってIBMのKubernetes-as-a-ServiceであるIKSを運用しているが、その運用において2つの問題があるということを紹介。最初の問題は、エンジニア同士のコミュニケーションだ。これは開発者と同じプラットフォームを使うと言う発想で全てがSlackで行われているという。そして2つ目の問題が、大量のサーバーの運用管理、特に更新については新しいツールが必要であると解説した。

IBMのJason McGee氏
そこで紹介されたのが、IBMが社内で使うRazeeというツールだ。特徴として、更新をクラスター側にプッシュするのではなく、あらかじめ設定したルールをクラスターが自動的に参照し、更新を実行するプル型であることだ。それ以外にもルールベース/ラベルベースであること、LaunchDarklyを用いてフィーチャーごとに更新を実行できること、複数のクラスターを跨ってインベントリー管理ができることなどを説明した。
参考:IBMが公開したオープンソースソフトウェア、Razee
この後、Googleのエンジニアによる従来から難しいと言われているKubernetesで永続ボリュームを扱う際の注意点などに関するセッションが続き、2日目のキーノートセッションは終わった。
Spotifyの失敗談とConde Nastの成功談、そしてIBMのRazeeなどが目立ったポイントだったが、Oracleが積極的にKubeConのサポートをし始めたという事実が、IT業界としては良い兆候ということだろうか。
また会期の初日はCNCFのホストするプロジェクトにおけるIntroセッションが集められていたのに対して、Deep Diveと称するより詳細な解説が多数行われたのが目立った2日目のKubeConであった。
- この記事のキーワード
この記事をシェアしてください
関連記事
Kubernetes Forum@ソウル開催。複数のK8sを統合するFederation APIに注目
2020年3月25日 6:00
KubeCon China:恒例の失敗談トークはスナップショットの実装について
2019年8月27日 6:00
KubeConでStripeのエンジニアが語ったインフラ移行の現実
2019年1月24日 6:00
KubeCon China:中国ベンダーが大量に登壇した3日目のキーノート
2019年9月10日 6:00
KubeConにKelsey Hightower氏登壇、コンテナからサーバーレスへ移行するデモを実演
2019年1月29日 6:00
中国企業が目立ったKubeCon Chinaの2日目のキーノート
2018年12月27日 6:00
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
