はじめに
前回は、ハイプ・サイクルに登場するキーワードの中から汎用人工知能や深層強化学習、転移学習、説明可能なAIなどを取り上げました。人間の脳のニューロンとシナプス、それをモデルとしたニューラルネットワーク、頭が良くなっていく仕組みとして誤差逆伝播などディープラーニングの基礎も解説したので、”いまさら聞けない”という方も楽しめたと思います。今回はハイプ・サイクルに登場する新しめのキーワードの中からアダプティブな機械学習、自己教師あり学習などを解説します。
アダプティブな機械学習
(Adaptive Machien Learning)
ハイプ・サイクルの2019年と2020年の黎明期にアダプティブ(適応型)な機械学習が登場しています。これは、これまでの機械学習とどこが違うのでしょうか。
第3回で解説したように、機械学習は学習プロセス(トレーニング)と推論プロセス(判定や予測、意思決定)の2つのパイプラインで実用化されます。学習プロセスでは大量データを使ってバッチでトレーニングを行い、実用に耐えるレベルに到達させます。そして合格点を得た学習済のモデルを判定や予測、意思決定などの目的に利用するのが推論プロセスです。
このプロセスを深層ニューラルネットワークを使うことで高い実行能力が発揮されて急激に脚光を浴びたのですが、実運用に当たっては、環境(データ)が変化した場合に学習プロセスからやり直しになる不便さが浮き彫りになってきました。当社が取り組んでいる異常検知で説明しましょう。最初に、ある製品の正常・異常をトレーニングして実運用に適用するのですが、設備の経年変化で当初想定してなかった異常が発生する場合があります。また、製品のマイナーチェンジのたびに現場で再トレーニングを行うのは大変です。
そこで求められたのがアダプティブな機械学習です。教師あり学習や教師なし学習ではなく、自ら自律的に学べる強化学習を使い、バッチではなくインストリーム分析(ISA)でオンライン学習します。少量のデータで微調整しながら適応し、AIの学習コストや運用コストを削減して永続的に利用できる理想のAIがアダプティブML(AML)なのです。
教師あり学習と教師なし学習
教師あり学習(Supervised Learning)と教師なし学習(Unsupervised Learning)についてもおさらいしておきましょう。図1は花の画像を分類する手法として、教師あり学習の分類(Classification)と教師なし学習のクラスタリング(Clustering)を比較した例です。
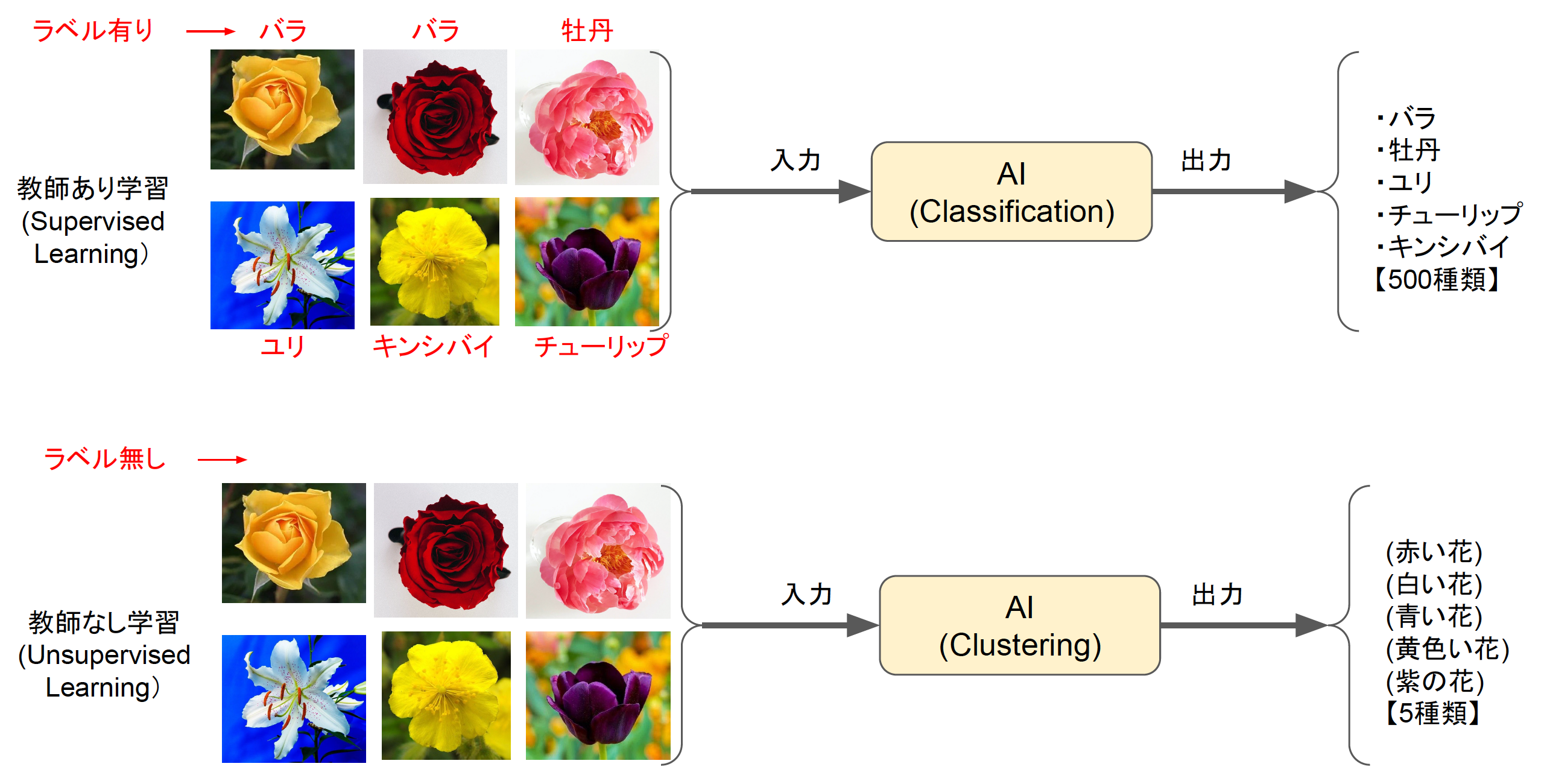
図1:教師あり学習と教師なし学習
教師あり学習は、画像にラベルを付けてから学習する手法で、ここでは花の名前500種類を出力としてトレーニングしています。AIは学習によって500種類の花を見分けられるようになりますが、人が「バラだと思うけど牡丹にも似ているなぁ」と思案するように「バラ85%、牡丹14%、ラナンキュラス1%」というようにスコアを付けて推論します。
うっかりするのですが、出力にない花が解答に選ばれることがありません。例えばシャクナゲを正解に含めずにトレーニングした場合は、シャクナゲの画像を似たような花(バラや牡丹)とスコア低めで判断することになります。何を出力(目的変数)としてトレーニングするかは重要です。例えば花の種類ではなく、花の色を分類するAIを作る場合は花の色を出力とし、赤や黄色といった色をラベルとしてトレーニングします。
一方、教師なし学習はラベルを付ける必要がありません。出力に目的変数(バラや赤いなど分類したいターゲット)を指定することもなく、ただ分類したい数だけを指定します。例えば「花を5つの色に分ける」という命題で処理すると、読み込んだ画像を5種類の色にグルーピングします。人間が分類結果を見ると赤い花の集団、白い花の集団などと見えますが、目的変数はないのでグループに色の名前が付いているわけではありません。意図した色に分類してくれるとは限りませんが、予想外の結果が得られて気付かされることもあります(表)。
表:師あり学習と教師なし学習(分類の例)
| 学習方法 | アルゴリズム | 目的変数 | 特徴 |
| 教師あり | 分類(Classification) | 有り | ・精度が高い ・目的に合った分類ができる |
| 教師なし | クラスタリング(Clustering) | 無し (分類数のみ指定) | ・学習データが不要 ・ラベル付けが不要 ・学習の手間が不要 ・予想外の結果が得られる |
この2つをどのように使い分けるのかを、今度はeコマースの例で説明しましょう。例えばアパレルサイトでは、トップス/ジャケット/パンツ/スカートというようなカテゴリーで商品が検索できます。これに、こだわり検索条件として、無地/ボーダー/花柄/チェックなどの柄や、ホワイト/レッド/ブルーなどの色も指定できればさらに便利になります。しかし、膨大な商品全てにこうした細かい分類をるのは大変です。そこで写真を見て柄や色を自動タグ付けしてくれるAIが求められるのです。このようなタグ付けAIは、検索条件にしたい柄や色を目的変数として学習するので「教師あり学習」になります。
一方、eコマースの顧客を嗜好や購買パターンが似ているグループごとに分類することを顧客セグメンテーションと言います。購買情報をもとに好きなブランド、柄、色、価格帯などの属性で顧客を分類できれば、顧客が興味ありそうなキャンペーンや新商品などの案内を送るターゲティングメールの効果が増します。このような顧客セグメンテーションAIは、ショップが一人ひとりにラベルを付けてトレーニングするわけではないので「教師なし学習」になります。
半教師あり学習(Semi-supervised Learning)
教師あり学習では、大量データにラベルを付け、バッチでトレーニングを行います。これをパッシブ機械学習(Passive Machine Learning)とも呼びます。このやり方の課題は、大量データにラベルを付けるアノテーション作業が大変な点です。また、作業負担の軽減だけでなく、物理的に既知のデータが少なく大部分のデータが未知であるという状況もよくあります。そこで登場したのが半教師あり学習(Semi-Supervised Learning)です。これは一部にだけラベルが付いている状態から、残りのデータにシステムが自動的にラベルを付けて学習するアプローチです。
ラベル無しデータにラベルを付ける処理の基本原理を説明します。例えば犬と猫の画像が10000枚あって、500枚にのみラベルが付いているとしましょう。バッチ処理の1回目で9500枚の未知データの中から既知(500枚)の画像に最も似ている(ベクトル空間の近い)ものを100枚選んで自動でラベルを付けます(合計600枚のラベルが付く)。2回目も同様にラベル付き600枚に似ている画像に100枚ラベルを付けます。この処理を25回繰り返すと3000枚の画像にラベルが付くことになりますね。半教師あり学習は、いかに未知のデータを正しくラベル付けするかがポイントで、自己学習(Self-Training)や共訓練(Co-Training)、PNU Learningなどいろいろな手法があります。
アクティブラーニング(Active Learning)
半教師あり学習は、最初に少量のラベル付きデータを用意することで、残りのラベル無しデータを一定のアルゴリズムで自動的にラベル付けをする方法です。いわばアノテーション(ラベル付け)の自動化を中心にしたもので、最初のラベル付け以外は人間が介在しません。
アクティブラーニングもラベル付きデータとラベル無しデータがある点は一緒ですが、こちらはラベル付け作業はあくまでも人間が行います。自動ラベル付けではなく自動データ抽出、すなわちラベル付け効果の高いデータだけを抽出(Query)するアルゴリズムがポイントです。全てのデータを人間がアノテーションするのがPassive Learningなので、それに対比してActive Learningという名前なのです。
同じ抽出するにしても、ランダムサンプリングだと学習に不向きなデータも混じります。アクティブラーニングは「これとこれが学習に向いてるよ」というデータを選んで渡してくれるわけです。図2のように、選んでもらったデータをアノテーションし、そのデータで学習したAIモデルを本番運用に使用します。そして、本番運用で発生する大量のラベル無しデータをプールし、それを再びQueryしてアノテーションするというサイクルを繰り返し、AIモデルの精度を運用しながら高めて行きます。
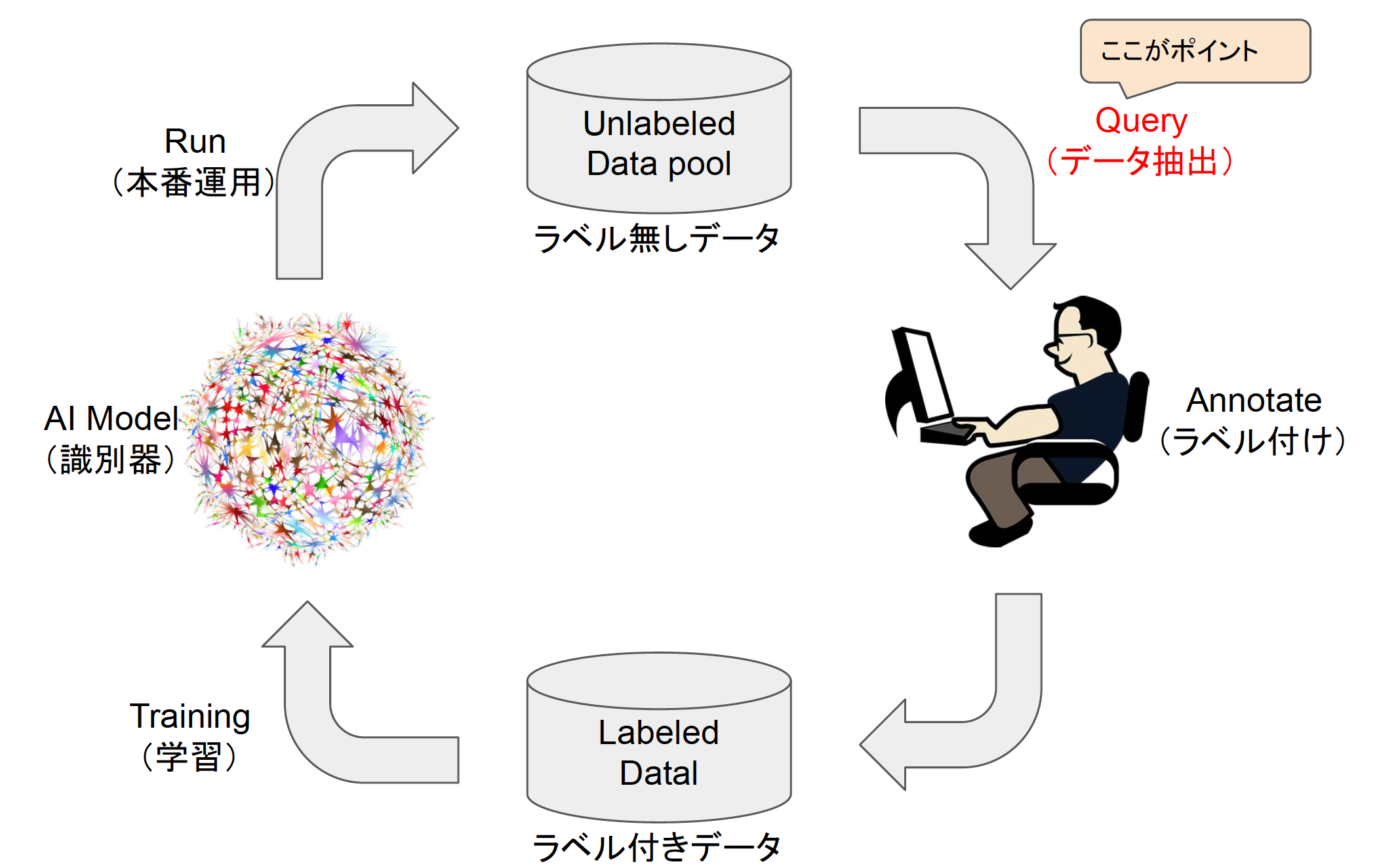
図2:アクティブラーニング
自己教師あり学習(Self-supervised Learning)
自己教師あり学習(SSL)は、早い段階から自然言語処理(Natural Language Processing)の分野で活躍しています。人間の会話では単語が抜け落ちたり、文法が正しくなくても、だいたい何が言いたいか通じます。これは人間の脳が、抜け落ちている単語を予測して補填しているからです。同じように自己教師あり学習を使って「こういう場合はこういう単語が出現する確率が高い」といった予測学習をするわけです。
例えばGoogleは2018年にBERTという言語処理モデルを発表し、文脈を読む能力を格段にアップさせました。学習データの単語の一部を別の単語に置き換えて元の単語を推測させたり、2つの関連ある文章のうち1つを別の文章に置き換えて文章の関連性をスコアするなどして、文脈を理解する力や曖昧な文章を読み解く力を学習したのです。BERTは2019年にGoogleの検索エンジンに導入され、2021年にはAIスピーカーのGoogleアシスタント(英語)にも取り入れられています。
画像処理でも、自己教師あり学習で不足部分を推定するトレーニングを行うことはできます。シンプルな例としては、画像を3D回転、色付け、深度補完などをして特徴点を学習したり、画像データの一部をマスクした上でそこに何があるか予測したり、画像を分割して個々の分割画像が元画像のどこに位置するか当てるなどです。
画像処理(Computer Vision)分野への適用は、変数が離散的な自然言語処理に比べて欠落した部分が連続分布の変数であるため、難易度が高いとされていました。しかし、現代ではさまざまな手法が次から次へと現れ、とてもホットな技術分野になっています。
半教師あり学習も自己教師あり学習も、ラベル付きデータが十分用意できない環境でも学習できる手法です。ただし、半教師あり学習は少量のラベル付きデータが必要ですが、自己教師あり学習はデータの基礎構造の不足を補う予測学習であり、教師データが必須ではありません。
ゲームでいえば、半教師あり学習が似たものを次々と一味にしてゆくロールプレイングゲームなのに対し、自己教師あり学習は今年9月に終了する長寿クイズ番組「アタック25」です。若い人はこの番組を知らないかもしれないので説明しておくと、勝ち抜いた人が最後に挑戦する旅行チャレンジVTRクイズで、25枚のうち勝ち取ったパネルにだけ映る映像を見て何が写っているか当てます。このとき、挑戦者の脳は写っている映像だけでなく、伏せられたパネル部分を経験や常識で補完して見ています。自己教師あり学習は、このようにAIに常識や経験を与えて不足している情報を推測できる能力を授ける予測学習なのです。
おわりに
AIはさまざまな分野で実用化されつつあり、それによって要求されるレベルも高度になってきています。最初は教師あり学習で高い推論精度を出すのに汲々としていたのに、説明可能なAI(XAI)やアダプティブな機械学習(AML)、自己教師あり学習(SSL)など、運用を楽にするために必要な技術が次々と登場しています。これらの新しい技術を取り入れていかないと競争に打ち勝てない状況になっていますので、留まらずに積極的にキャッチアップして行きましょう。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
