KCPSの運用で直面した仮想化基盤拡大に伴う課題とその対策
KCPSの運用で直面した仮想化基盤拡大に伴う課題とその対策
対してKDDIのセッションは、まじめに自社が保有するサーバー群やスイッチなどのネットワーク機器から発生するアラームをどうやって処理するべきか? を解説するものであった。

担当したのはKDDIの森田氏
セッションを行った森田亙昭氏は2003年にKDDIに入社、2011年から運用チームとして監視業務をスタートし、2012年からはKCPS(KDDI Cloud Platform Service)の専任として従事しており、運用の苦労を知り尽くしているエンジニアだ。
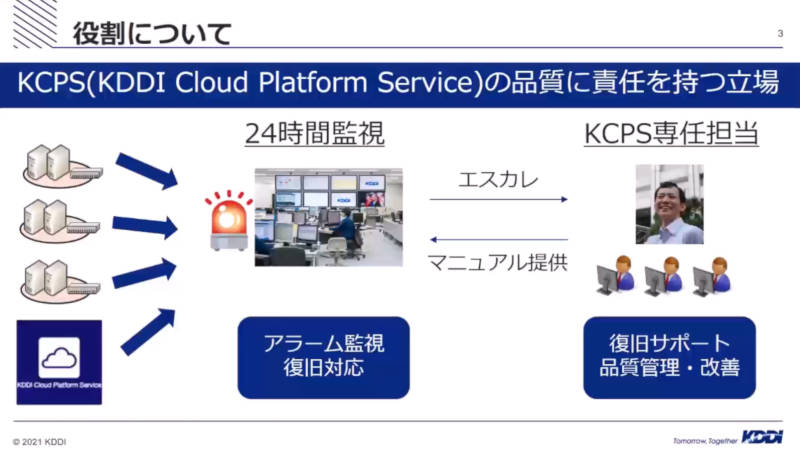
運用監視チームのバックエンドとして品質を管理する役割
ここではデータセンターの機器が増加に伴い複数の世代の機器を運用する必要が出てきたこと、そしてそれに従って故障もアラームも増えてきたことを解説した。
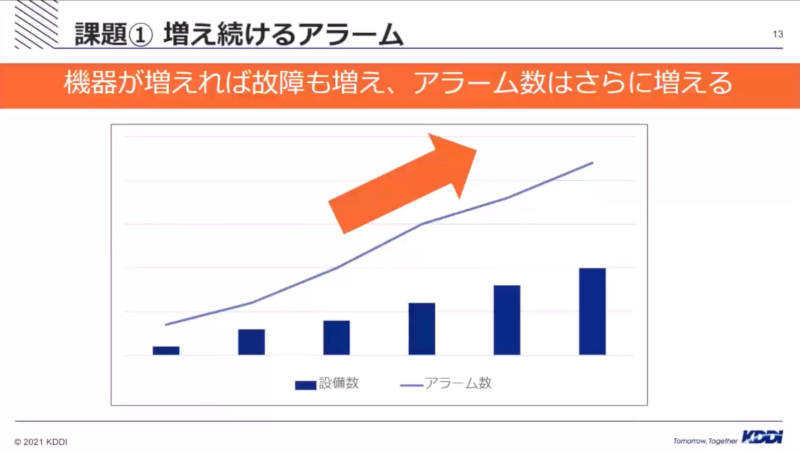
需要に従って機器が増加しアラームも増加
アラームに対するマニュアルを作成する部門としては、発生するアラームを削減することで運用チームの稼働を下げたいという思いもあったが、実際には追いついていなかったことを紹介した。
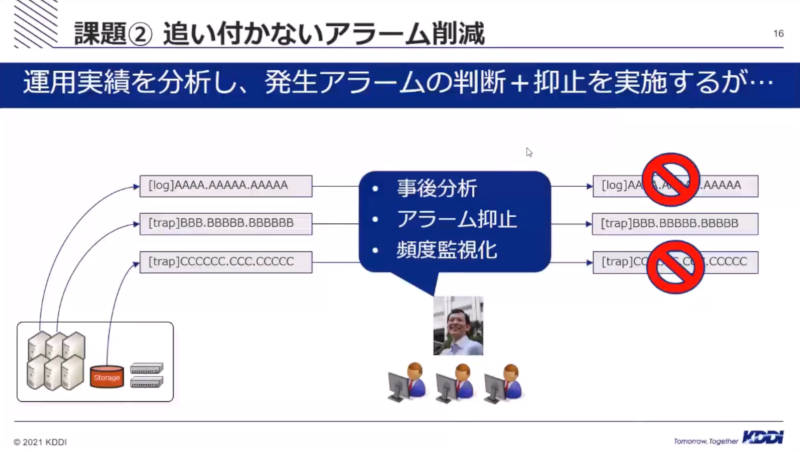
追いつかないアラーム処理
結果として故障対応やアラーム対応に追われることで、KCPSが目指してきた高品質を保つことが難しくなってきたという課題について、より詳細な分析が必要となったという。

課題の整理
業務分析を行ったことにより、アラームの大半が人手による対応が不要なものだったことがわかったとして、本当に必要なアラームだけをオペレータに通達するべきだということがわかったという。
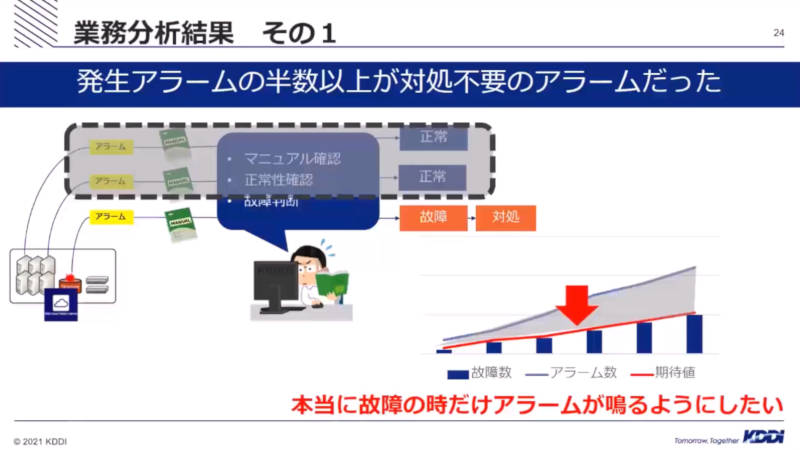
対応不要なアラームを削除したい
そのために、これまでオペレータが判断していた部分を監視機能の中に組み込むことを決めたと説明した。
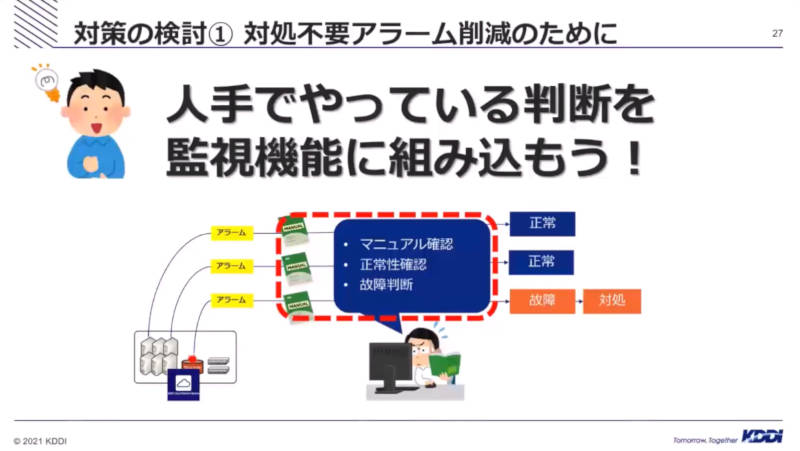
判断する機能を監視機能に組み込む
これまでマニュアルで判断していた正常かどうかの機能は「正常性監視」機能として実装され、マニュアルの作業が自動化されたことを解説した。
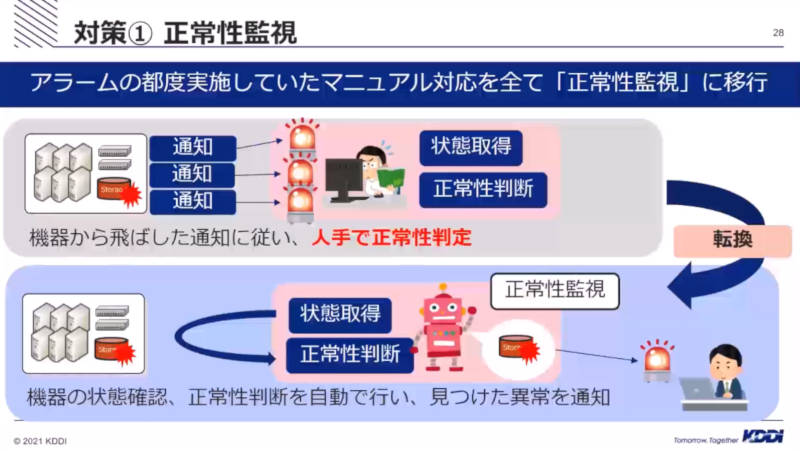
人手による判断を正常性監視機能に移行
また冗長化された機器においては、たとえ1台が故障したとしても冗長化によって運用を続けることは可能であるという発想で、機器の冗長度を判断する仕組を組み込んだことを説明した。
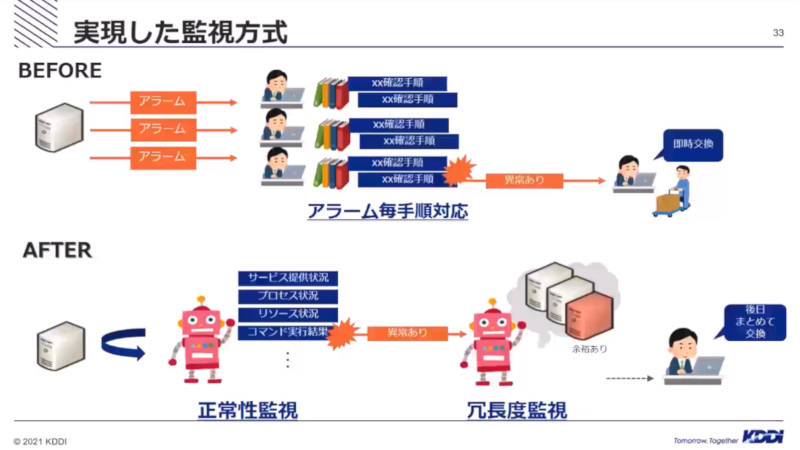
冗長性の高い機器はまとめて交換する方法に移行
結果としてアラーム数と対応時間がそれぞれ90%減、70%減となったことを紹介して、KCPSにおけるアラーム対応の品質を保ったことを解説した。

アラーム数、対応時間ともに大幅に削減された
また単発で発生するアラームではなく継続して発生するアラームから故障を検知するための仕組として統計監視を導入し、時系列や頻度を意識したアラーム検知を行えるように改善したと言う。
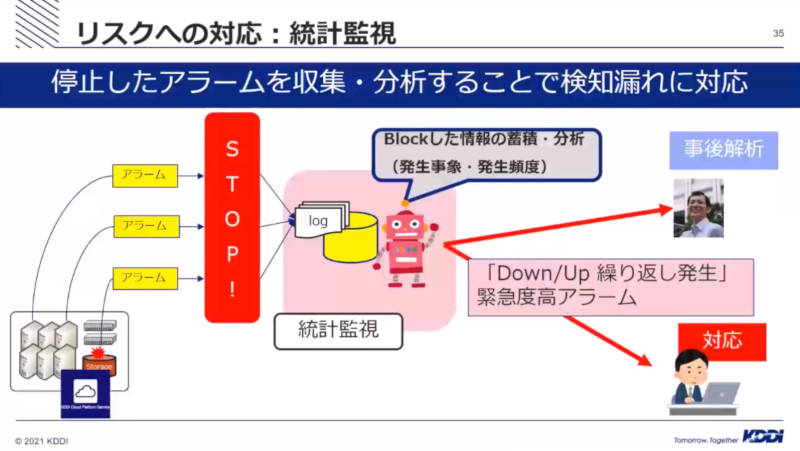
統計監視を使って頻発するアラームを検知
最後にまとめとして、人手に頼っていたアラーム監視から正常性を検知する仕組みに移行したこと、冗長度を意識した監視を導入したこと、これによって冗長度が高い機器はまとめて交換するなどの効率化がなされたこと、頻度を意識したアラーム分析によって見落とされがちだった故障なども検知できるようになったことを説明した。
NTT東日本の事例はあくまでも新人研修の域を出ない内容だったが、KDDIのアラーム監視システムは人手による作業を分析することで無駄を省き、さらに統計データから異常を検知するという一歩踏み込んだ内容となった。実際には運用担当者が行っていたアラーム判断の部分をシステム化する時の実装方法(ルールベース、マトリックスなど)まで踏み込んで欲しかったというのは欲張りなリクエストかもしれないが、KCPSの今後の進展に注目していきたい。
関連記事
CI/CD Conference 2023から、アルファドライブ/ニューズピックスのSREがAWS CDKを活用したCI/CD改善を解説
2023年6月6日 16:54
【CNDW2024】障害特定が超爆速に! セブン&アイ・ネットメディアが実現したObservabilityの威力
1月23日 6:00
Observability Conference 2022、オブザーバビリティから組織、ルールを見直した事例を紹介
2022年6月29日 6:00
クラウドネイティブの真髄であるサーバーレスがキーノートに登場
2018年4月5日 6:00
CODT2021、組織変革でスクラム開発を加速したKDDIのセッションを紹介
2021年11月26日 5:50
SODACON Global 2021、トヨタが「一緒に走り続ける」と宣言したコネクテッドカーのインフラ
2021年12月14日 6:00
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
RustとWASMで開発されKubernetesで実装されたデータストリームシステムFluvioを紹介
2022年12月23日 6:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
