KubeCon EU 2022からバッチシステムをKubernetesで実装するVolcanoを紹介
KubeCon EU2022から、Kubernetes上でバッチジョブを実行するVolcanoを解説するセッションを紹介する。
2022年9月15日 6:00
KubeCon+CloudNativeCon EU 2022から、Kubernetesの上でのバッチ処理を実装するオープンソースソフトウェア、Volcanoを解説するセッションを紹介する。これはVolcanoの開発をリードするHuawei CloudのアーキテクトであるKlaus Ma氏が行ったもので、リアルではなくバーチャル、つまり予め録画した動画を配信したセッションとなった。Huaweiは今回もダイアモンドスポンサーとしてカンファレンスには多額の予算を費やしているが、今回は中国本土からの参加者がほぼいなかったことを考えると中国国内で使われているオープンソースプロジェクトに欧米からのコントリビューターを増やしたいという意図があったのだろう。
クラウドネイティブなシステムと言えば、ステートレスでオンライン&リアルタイムなアプリケーションやそれを支えるシステムが注目されているが、機械学習やビッグデータにはバッチで大量のデータを学習するプロセスは欠かせない。Apache Sparkなどのオープンソースプロジェクトで実装されることが多いビッグデータシステムだが、その中のバッチジョブのスケジューリングの部分をKubernetesの上に実装したのがVolcanoということになる。
セッションの動画:Volcano: Intro & Deep Dive
スライドのリンク(PDF):https://static.sched.com/hosted_files/kccnceu2022/bd/KubeCon_EU_2022_Volcano_Intro-v2.0.pdf

セッションはスライドと音声だけという質実剛健な感じ
最初にMa氏は過去を振り返り、高速なCPUと並列化によるHPC(High Performance Computing)と呼ばれていた領域が、複数の安価なサーバーを並列処理させるクラスター構成によってビッグデータそして人工知能のための機械学習に変化していく流れを説明した。

HPCからビッグデータ、機械学習の流れの先にKubernetesでの実装がある
ここではユーザーのエコシステムが分断化されること、ソフトウェアスタックが専用のものになってしまうことで知見が活かされないこと、そして大量のデータを処理する際の効率の悪さからクラウドネイティブなシステムへの移行が促進されたと説明した。この表では2017年にKube-Batchが登場した後に2019年にHuaweiが開発していたVolcanoをオープンソースとして公開、2020年にはCNCFのサンドボックスプロジェクトとして認定され、2022年4月にインキュベーションプロジェクトとして格上げされたことがわかる。

バッチシステムをK8sに実装する際の課題を説明
このスライドではバッチシステムをKubernetes上に実装する際の課題について解説を行っている。ステートレスなアプリケーションのスケーラビリティを実現するために複数のPodを並列実行するKubernetesにとって、バッチシステムのジョブやキュー、スケジューリングといった特性、また複数のアプリケーションが定義された順番に実行されることでデータ処理が進むという発想が難しい部分だろう。またGPUやNUMAなどのデータ処理に特化したハードウェアを効率的に利用することは、Kubernetesのスケジューラーにとっては難しい。
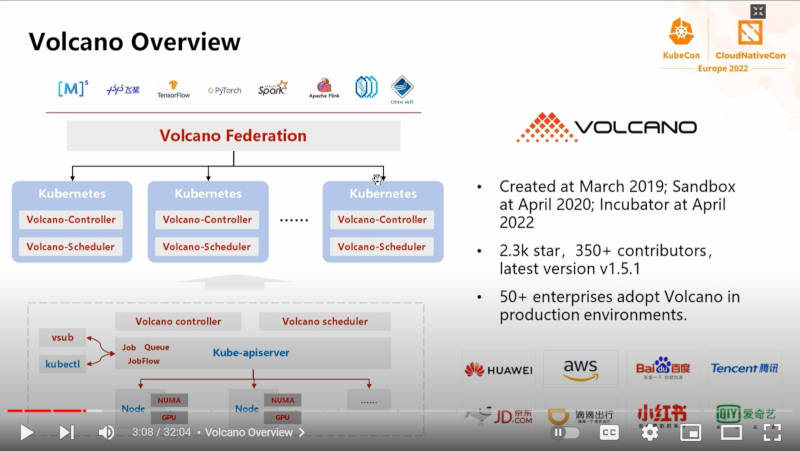
Volcanoの概要
このスライドではKubernetes上にVolcano-ControllerとVolcano-Schedulerが上位のSparkなどのジョブをクラスター上にスケジュールする仕組みが解説されている。また350名以上のコントリビューター、50以上のエンタープライズがVolcanoを本番システムで利用していると説明されたが、実際にロゴで示されているのは、AWSを除けば中国企業のBaidu、Tencent、JD.comなどのインターネット企業であることがわかる。
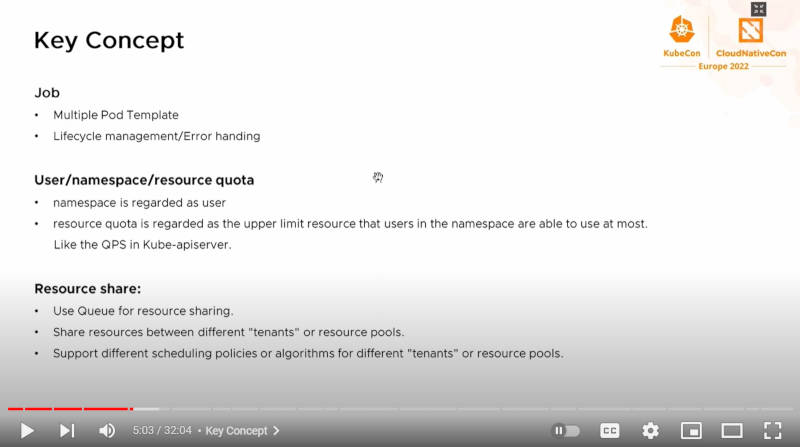
バッチシステムに必須なコンセプトの解説
ここからVolcanoが持つ基本的なコンセプト、特にジョブやユーザー、キューなどについて解説が行われた。ジョブは複数のPodを実行するためのテンプレートとして定義され、ユーザーにはそれぞれ固有のネームスペースを持たせることでネームスペースがそのままユーザーと見なされると説明した。キューはリソースを共有するための仕組みとして使うとして、同じネームスペースに属する複数のPod(ジョブ)がスケジューリングのポリシーに従って実行されると説明した。
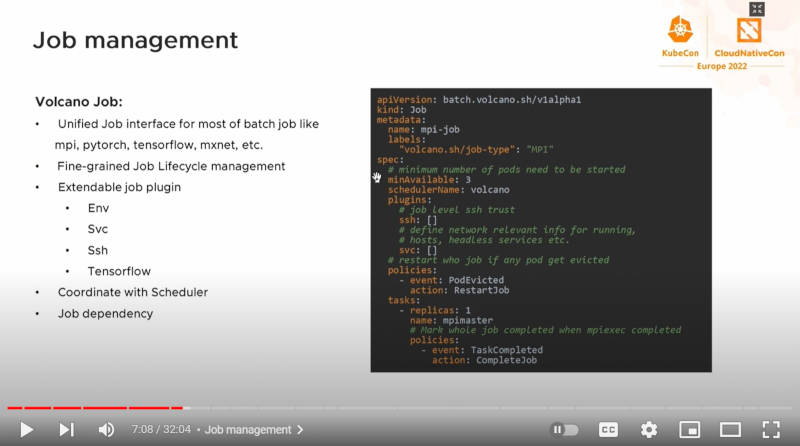
ジョブの管理を解説
このスライドでは、YAMLファイルの例を挙げてジョブの記述について説明を行った。このスライドでジョブのライフサイクル管理とあるのは、いわゆるアプリケーションのライフサイクル(バージョンアップなど)という観点ではなく、ジョブがどのように起動されて終了するのか? という意味のライフサイクル管理ということだろう。
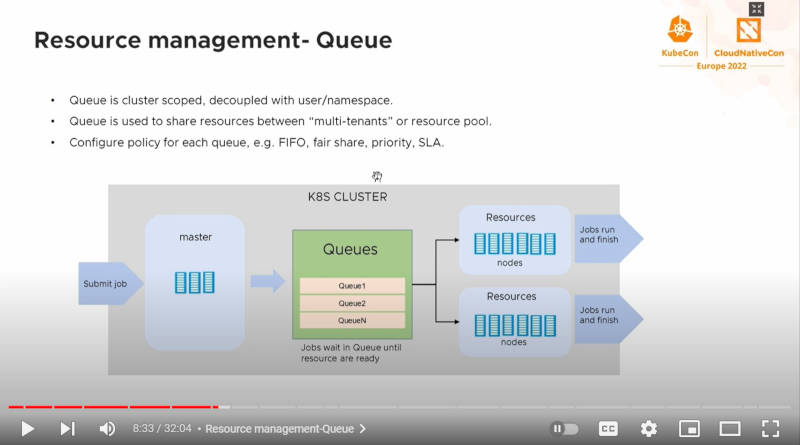
キューの解説
続いてキューに関する解説が行われた。キューはPodに対するスケジューリングのためのポリシーやアルゴリズムを使いながらPodを実行するための仕組みだ。ここではユーザーやネームスペースとは別のコンセプトであると説明されている。つまりそれぞれのネームスペースを持つ複数のPodが同じキューの中でスケジューリングされることもあり得ることになる。これはバッチジョブをどのような優先順位で実行したいのか?というアプリケーションデベロッパーの意図を実現するためのメカニズムであると言える。
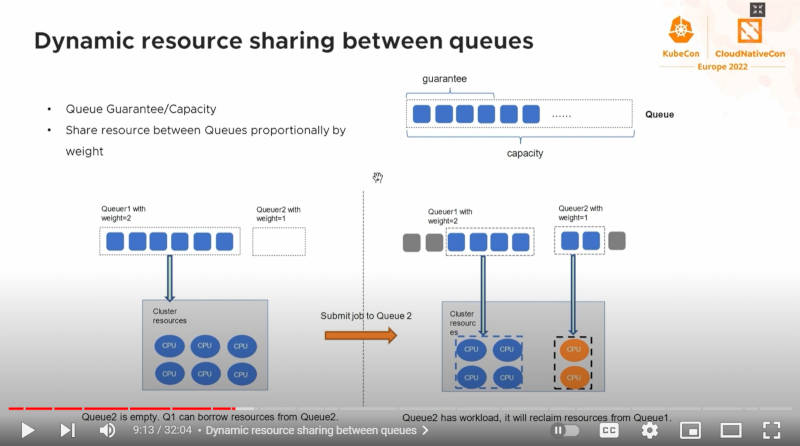
優先度が異なるキューのスケジューリングを解説
このスライドでは優先度(Weight=1 or 2)が異なるキューに複数のPodがスケジューリングされた際にどのようにPodが実行されるかを解説している。より高いWeightを持つキューに存在するPodは優先的に実行され、Weightの低いキューのPodはCPUなどが空いた場合に実行されることを示している。
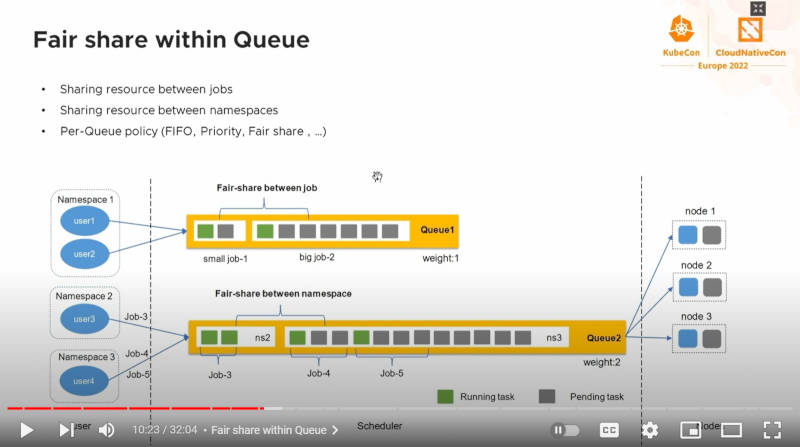
キュー間のリソース共有の仕組み
このスライドでは、キューの中に存在するPodの数に関わらず公平にスケジューリングがされる部分を解説している。同じネームスペースに属する2つのユーザーからそれぞれジョブが投入されたとしても、公平にCPUなどの割り当てが行われること、異なるネームスペースからのジョブについても同様に優先順位に従ってノードにPodがスケジューリングされることを示している。
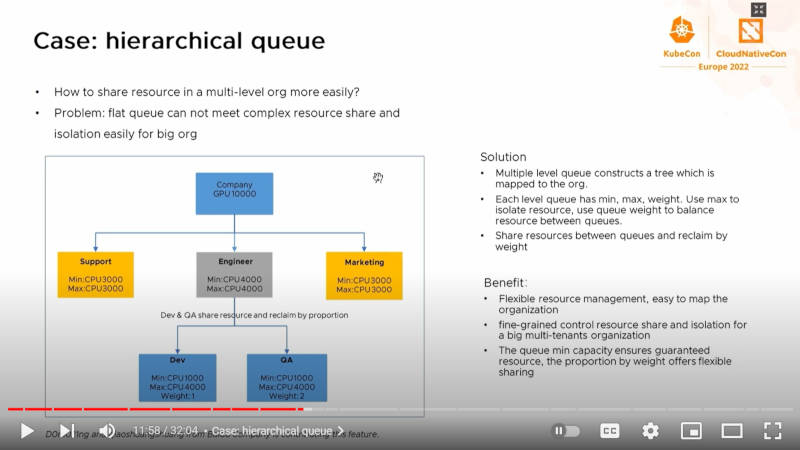
ヒエラルキーに従ったスケジューリングも可能
ここでは組織の構造に即したリソースの割り当てが可能であることを説明している。特に大規模な組織にCPU/GPUなどを割り当てる場合に、組織ごとの最小値/最大値を設定することでその組織に属する下部組織について、リソースの割り当てが可能であるという。元々Volcanoを開発していたのが、Huaweiであることを考えると、大規模な組織のニーズにあったスケジューリングポリシーが採用されるのは当然だろう。

Volcanoが対応するさまざまなスケジューリングポリシーの例
ここではVolcanoが対応するスケジューリングポリシーを挙げて説明している。ギャングスケジューリングは複数のアプリケーションが相互通信を行う場合に並列に実行を行うためのポリシーだ。他にもGPUやNUMAのハードウェアを意識したスケジューリングも設定できるという。いかにGPUのアイドルタイムを減らしてフル稼働させるか? という部分が機械学習のスループットに大きく関係してくるため、なるべく無駄なく隙間を埋めるようなスケジューリングをしたいというのがデベロッパーの思いだろう。

SparkのジョブをKubernetesでスケジューリング
ここではSparkにおけるバッチジョブのスケジューリングを紹介している。2022年6月30日、CNCFのブログにSpark 3.3でVolcanoがデフォルトのスケジューラーに採用されたという記事が公開されている。
参考:Why Spark chooses Volcano as built-in batch scheduler on Kubernetes?
これによって、MapReduceジョブもVolcanoによってKubernetes上でスケジューリングを行うことがデフォルトの選択肢となる。
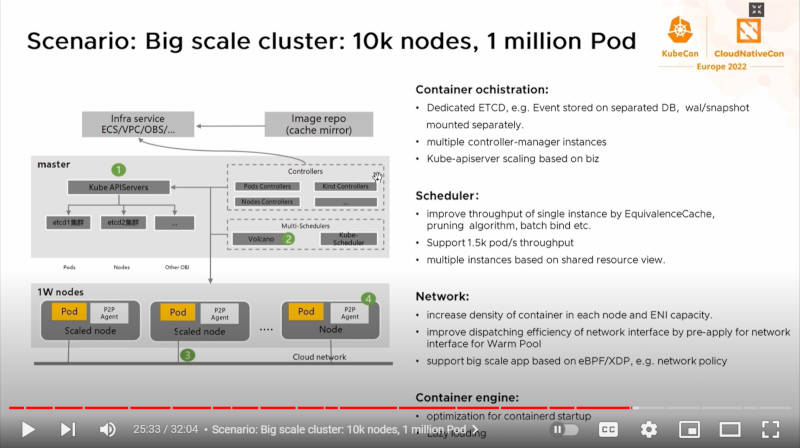
大規模システムでの複数のKubernetesを使った階層的スケジューリング
この例では1万台のノード、100万個のPodが実行される大規模システムにおいて、フラットなKubernetesによって実装するのではなく、Kubernetesの上にKubernetesを重ねた階層的な構成を取ることでスループットを上げることができる例を紹介している。ここでもHuaweiやTencentという中国のメガサービスプロバイダーのニーズを満たすことを主眼が置かれていることがわかる。

小紅書というECサイトの例を紹介
このスライドでは小紅書(Xiaohongshu)と呼ばれる中国のSNSおよびECサイトでのユースケースを紹介している。ここではレコメンデーションのための機械学習にVolcanoが使われており、毎月1億人のアクティブユーザーがいるという巨大なサイトでデータ学習のパフォーマンスが20%向上したという例を説明した。
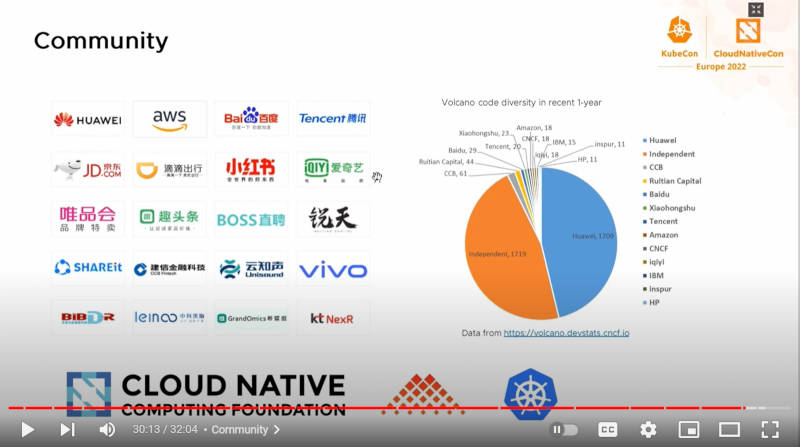
Volcanoのコミュニティは中国本土が大多数
最後に過去1年のコントリビューターの割合を示したスライドを使って、Volcanoにコードを提供しているコントリビューターの割合を紹介。ここでもHuaweiが圧倒的にコードを提供していること、中国の企業が少数ながら貢献を行っていることがわかる。
またユースケースとして上げられたRuitian Capitalという投資会社における導入例では、バッチのスケジューリングにHadoop/Yarnを使っていたのを、Kubernetesへの移行を試みたという。その際、最初のPoCでデータサイエンティストが同時に5000のPodをスケジュールしようとして作成したYAMLファイルが1.5MBを超えるサイズとなったことで、etcdの上限を超えてしまったために試行が上手く行かなかったそうだ。その後、レプリカセットを使うことですべてのジョブをPodとして記述するのではない方法に変更することで移行できたという例を紹介している。詳細は以下のブログを参照されたい。
参考:How Ruitian Used Volcano to Run Large-Scale Offline HPC Jobs
Volcanoの公式GitHubリポジトリー:https://github.com/volcano-sh/volcano
Volcanoはコミュニティとして中国以外にどうやって拡げていくのか? を模索していると思われる。しかしコミュニティミーティングも中国国内向けの議事録しか公開されてない現状からみると、前途はそれほど明るくないと言えるだろう。何よりもVolcanoを使ってくれるユーザーを見つけること、そこから開発に関わったエンジニアのリクルートに繋げるなどの地道な努力が必要だと思われる。
なお、KubeCon EU 2022のショーケースではHuaweiも出展していたが、他社のブースに比べると非常にあっさりとしたブース構成で、中国人参加者が非常に少ないという現状を反映したものだったのかもしれない。

活気に欠けるHuaweiのブース

Volcanoも展示していたが閑古鳥状態
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
