Chaos MeshとGitHub Actionsの連携
Chaos MeshとGitHub Actionsの連携
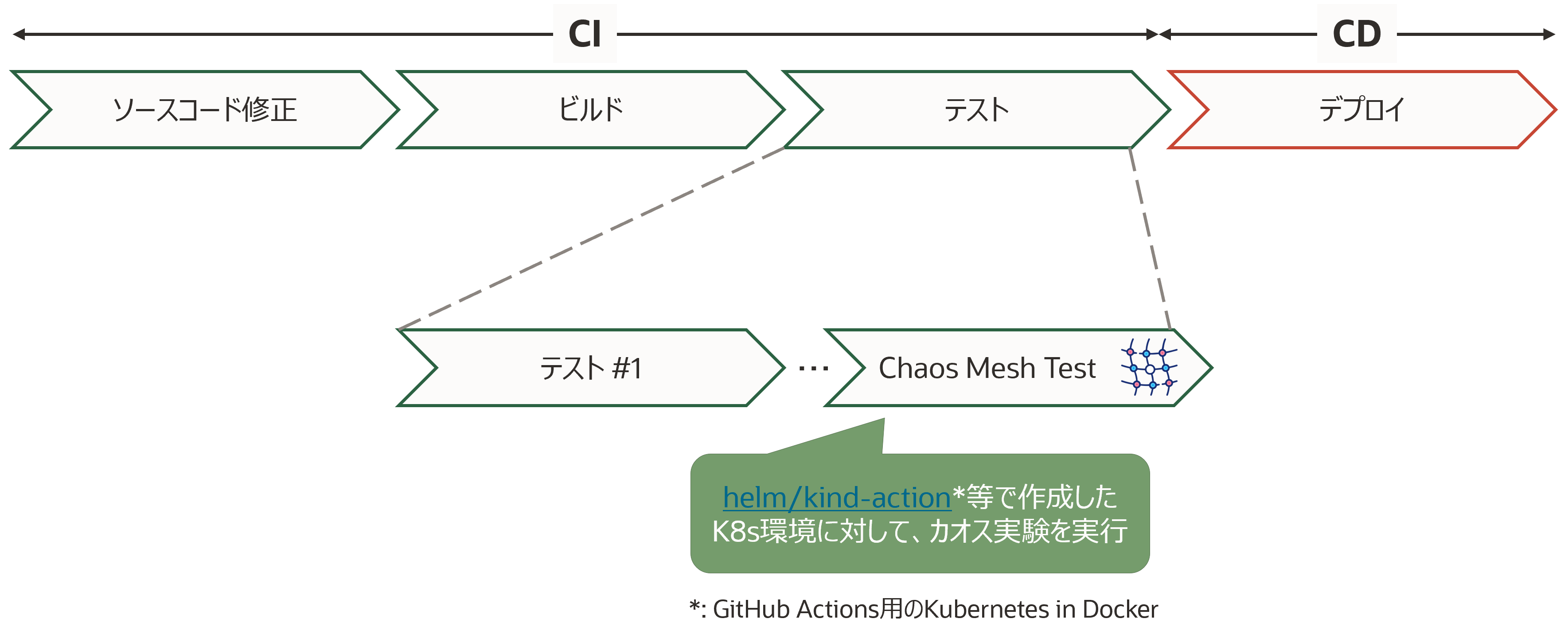
Chaos Meshには、CI(Continuous Integration)の一環として組み込むためのGitHub Actionsがマーケットプレイスで公開されています。helm/kind-actionなどを用いてGitHub Actions上に一時的なKubernetesクラスタを構築し、カオス実験を行った信頼できる資産を各環境に配備することが可能となります。CI上という一時的な環境のため実行できることは限られますが、影響範囲の局所化に対して戦略的なアプローチを取ることができます。
Chaos MeshとGrafana Dashboard
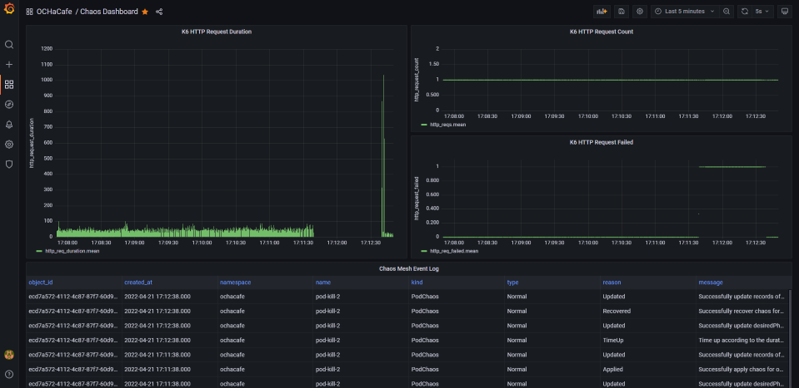
Chaos Meshには、Grafanaの Data Source用のプラグインも提供されています。これは、定常状態の測定結果や実験時の測定結果とChaos Meshのイベントログを1つのダッシュボードとして構築したい場合などに重宝します。2023年4月現在では、GrafanaがまだChaos Mesh Data Sourceのプラグイン提出を受け入れていないため、grafana-cliを用いたインストールは行えません。
chaosctl
Chaos Meshには、実験のデバッグログや主要コンポーネントのログを表示するためのクライアントツールchaosctlが存在します。特に新しい実験タイプを作成する際のデバッガーとして活用することが想定されます。
Demo: 初めてのカオスエンジニアリング w/ Chaos Mesh
発表時は、Demo: 初めてのカオスエンジニアリングで実施したデモを、Chaos Meshを使って再度実施しました。

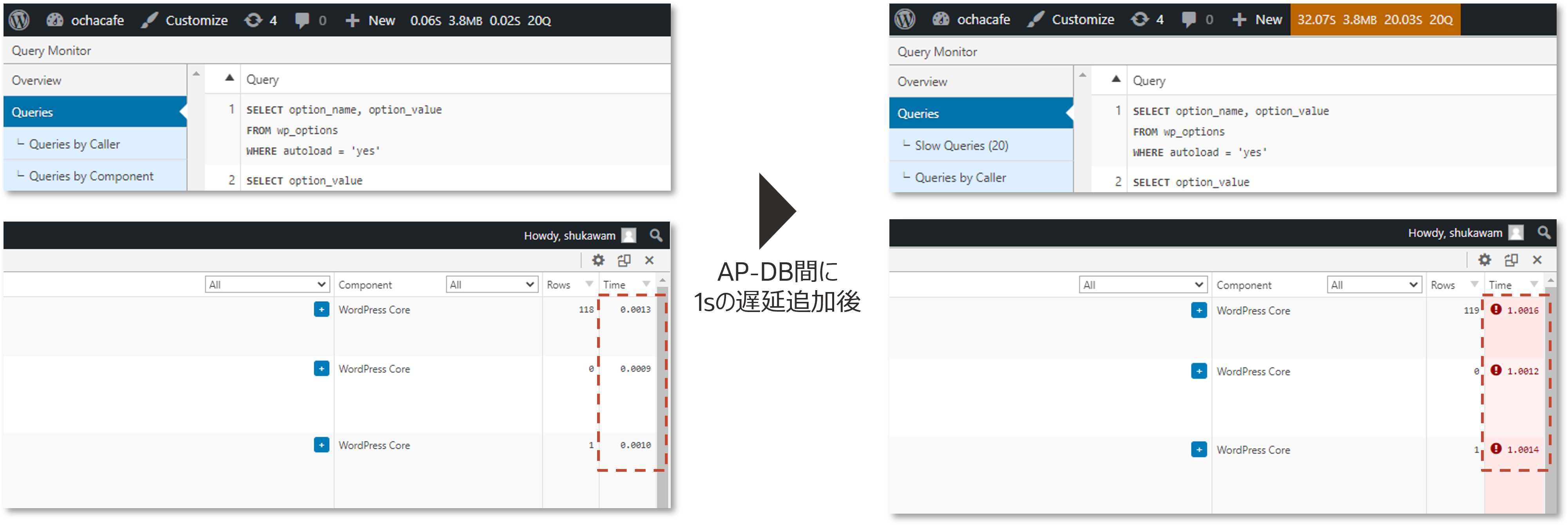
Chaos Meshのワークフロー機能を活用し、k6を用いた定常状態の測定、WordPressとMySQLの間の通信に1sの遅延を注入した際の平均応答時間の測定、Slack通知までを自動化しています。さらに、k6の実行結果とChaos Meshのイベントログを同じGrafanaのダッシュボードに表示することで、イベント注入のタイミングと測定結果の紐づけも分かりやすくなります。
発表時のデモは、アーカイブに残していますので、ぜひ参照ください。
参考: 極端な遅延が発生した理由
今回のデモでは、該当ページを表示させるために複数回(20〜40回)のクエリーが直列で実行されていることがQuery Monitorで確認できました。そのため、WordPress - MySQL間に仕込んだ1sの遅延は最終的に1s \* 20~40 回 = 20~40sの遅延として観測されます。
カオスエンジニアリングをサポートするツール群
カオスエンジニアリングをサポートするツールは、Chaos Meshに限らず、dastergon/awesome-chaos-engineeringを見ると多くのツールが存在することを確認できます。今回は、この中からGremlinとPumbaの2本を簡単に紹介します。
Gremlin
Gremlinは、Gremlin社がFailure as a Serviceのコンセプトで開発したカオスエンジニアリング用のSaaSプラットフォームです。インスタンスにエージェントを仕込む形で様々な障害をシミュレートできます。また、SaaSならではのプリセット済みのカオス実験のシナリオや簡易的な実験レポート機能も提供されています。
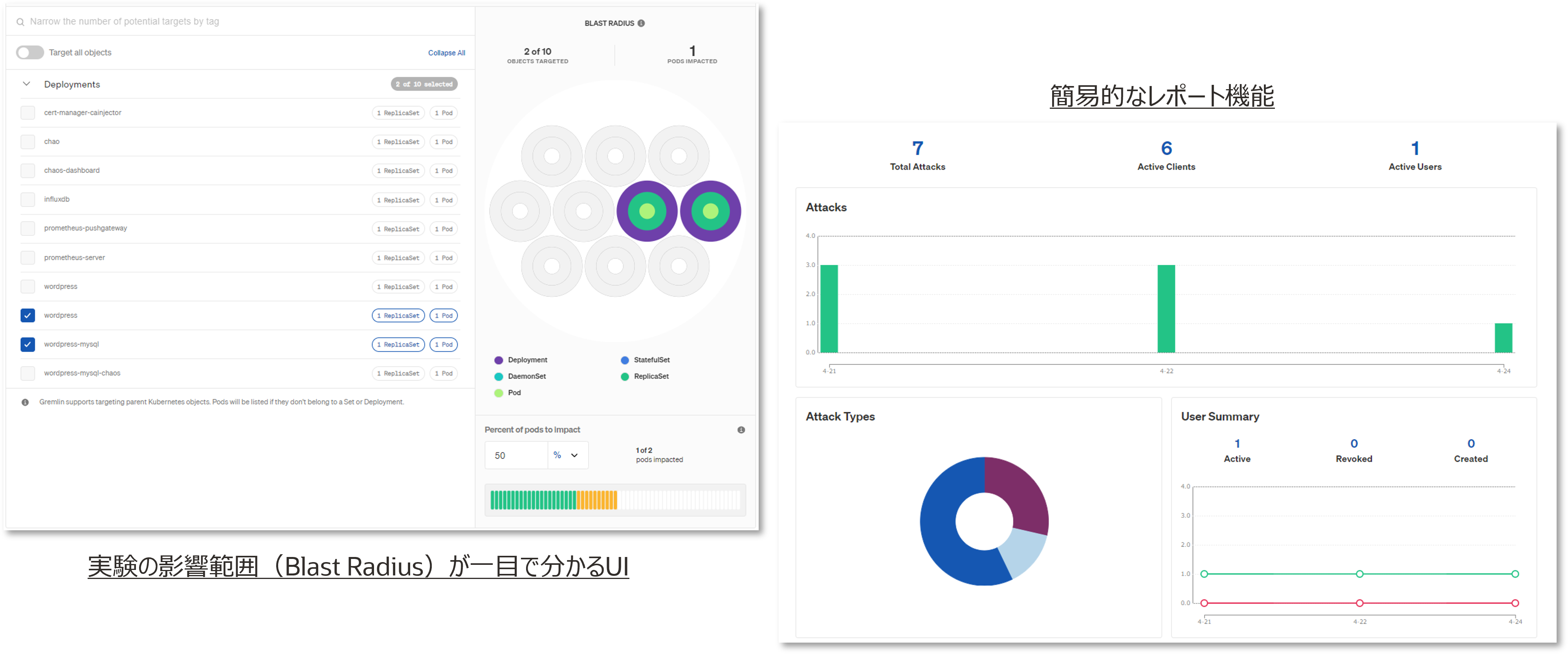
提供されている障害の種類としては幅広く、2023年4月現在では下表の種類が提供されています。
| Category | Attacks | Description |
|---|---|---|
| Resource | CPU | CPUの負荷をシミュレート |
| Resource | Disk | ハードディスクへのファイルを書き込みの負荷をシミュレート |
| Resource | IO | I/Oデバイスに対する負荷をシミュレート |
| Resource | Memory | メモリへの負荷をシミュレート |
| State | Process Killer | 指定されたプロセスを強制終了する。アプリケーションや依存関係のクラッシュをシミュレートするために使用 |
| State | Shutdown | ホストOSのシャットダウンを実行 |
| State | Time Travel | システム時間を変更し、summer timeやその他時間に関連するイベントへの適応をシミュレート |
| Network | Blackhole | 条件に一致するすべてのネットワークトラフィックをドロップする |
| Network | DNS | DNSサーバーへのアクセスをブロックする |
| Network | Latency | 条件に一致するすべてのインバウンドのトラフィックに対して、レイテンシーを注入する |
| Network | Packet Loss | 条件に一致するすべてのトラフィックに対して、パケットロスを発生させる |
Pumba
PumbaはDocker(Swarm)専用のカオスエンジニアリングツールで、Pumbaのバイナリをインストールして使います。コンテナアプリケーションのクラッシュやネットワーク障害のエミュレーション、コンテナリソース(CPU、RAM、IO、etc.)のストレス診断等の実施が可能です。
pumba --help
NAME:
Pumba - Pumba is a resilience testing tool, that helps applications tolerate random Docker container failures: process, network and performance.
USAGE:
pumba [global options] command [command options] containers (name, list of names, or RE2 regex if prefixed with "re2:")
VERSION:
0.9.0 - 2e7ab7b (master) 2021-11-21T10:12:49+0200
AUTHOR:
Alexei Ledenev <alexei.led@gmail.com>
COMMANDS:
kill kill specified containers
exec exec specified containers
restart restart specified containers
stop stop containers
pause pause all processes
rm remove containers
stress stress test a specified containers
netem emulate the properties of wide area networks
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
--host value, -H value daemon socket to connect to (default: "unix:///var/run/docker.sock") [$DOCKER_HOST]
--tls use TLS; implied by --tlsverify
--tlsverify use TLS and verify the remote [$DOCKER_TLS_VERIFY]
--tlscacert value trust certs signed only by this CA (default: "/etc/ssl/docker/ca.pem")
--tlscert value client certificate for TLS authentication (default: "/etc/ssl/docker/cert.pem")
--tlskey value client key for TLS authentication (default: "/etc/ssl/docker/key.pem")
--log-level value, -l value set log level (debug, info, warning(*), error, fatal, panic) (default: "warning") [$LOG_LEVEL]
--json, -j produce log in JSON format: Logstash and Splunk friendly [$LOG_JSON]
--slackhook value web hook url; send Pumba log events to Slack
--slackchannel value Slack channel (default #pumba) (default: "#pumba")
--interval value, -i value recurrent interval for chaos command; use with optional unit suffix: 'ms/s/m/h' (default: 0s)
--label value filter containers by labels, e.g '--label key=value' (multiple labels supported)
--random, -r randomly select single matching container from list of target containers
--dry-run dry run does not create chaos, only logs planned chaos commands [$DRY-RUN]
--skip-error skip chaos command error and retry to execute the command on next interval tick
--help, -h show help
--version, -v print the version
おわりに
今回はPrinciples Of Chaos Engineeringを参照し、カオスエンジニアリングとは何か?、実験の手順、理想的な応用方法を具体例を交えながら整理しました。カオスエンジニアリングは実験的な側面が非常に強いです。そのため、まずは適用できそうな小さな範囲からでも実際に試してみることが重要なのではないでしょうか。その際に活用できるツールとして、本連載では Chaos Mesh、Gremlin、Pumbaを取り上げましたが、これ以外にも数多くの有益なツールが存在します。
今回の内容が、読者の皆さまのカオスエンジニアリング導入にお役に立てれば幸いです。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
