大規模言語モデルの概要
第2回は、「ChatGPT」が誕生した背景を中心に、大規模言語モデルの本質について見て行きます。
2023年6月21日 6:30
はじめに
前回はスケーリングの法則により、大規模言語モデル(LLC)の競争時代が始まったことを解説しました。今回は、大規模言語モデルがどのように生まれたかを解説します。我々はChatGPTが人間のように会話したり、とても博学なのに驚かされましたが、いったいどうやってそんなことができたのでしょうか。
人の一生とAIの短期トレーニング
例えば人間であれば、いろいろな人と話したり、たくさんの文章を読み書きした結果で知識や会話能力、文章力が増えて、そのノウハウがその人の脳に刻まれています。実は、言語モデルAIの場合も似たようなアプローチです。膨大な文章を学習データとして読み書きのトレーニングをし、そこで得たナレッジをパラメータ化しています。
人間が一生かけて読み書きするテキスト量は馬鹿になりませんが、AIはそれをはるかに超える量のテキストを短期間で学習し、それをニューラルネットワークという脳に刻んでいるので、とんでもなく博識なのです。
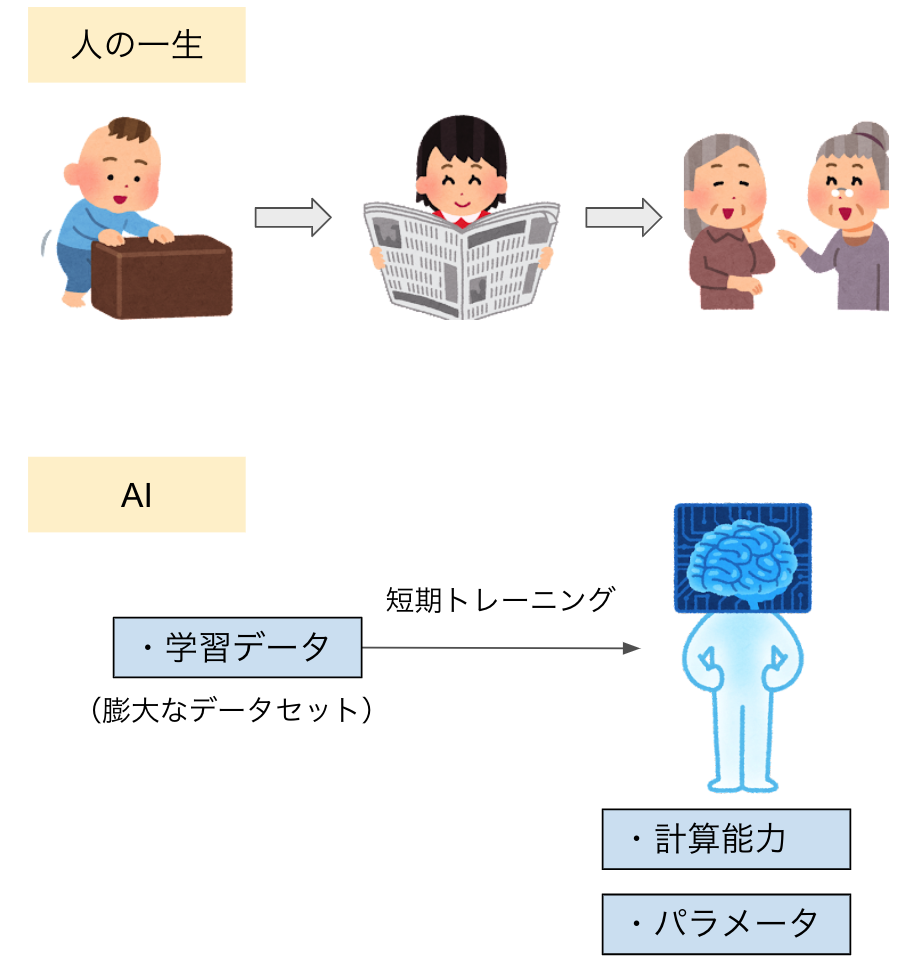
図1:人の一生とAIの短期トレーニング
そう考えると、スケーリングの法則が、言語モデルの性能は「計算能力」に加えて「モデルサイズ(パラメータ)」と「学習データセットの量」に比例すると言っている意味が理解できます。今や、パラメータは数千億から兆単位に拡大し、チャットを通じて世界中の人々から生きたデータを(個人情報を除いて)集めているので学習データも莫大に増えています。そして、大規模になればなるほど、それを高速処理する計算能力が必要となり使用されるGPUの数も多くなっているのです。
GPT-3の学習データ
GPT-3.5は2021年3月までのデータ、ChatGPTとGPT-4は2021年9月までのデータで学習しています。これらのモデルがどの学習データを利用しているかは非公開ですが、GPT-3の学習データをベースにしているので、GPT-3がどんな学習データでトレーニングしたのか見てみましょう。
GPT-2の学習データは40GBだったのに対し、GPT-3は570GBにボリュームを拡大しています。図2はその内訳です。約6割の寄与度を締めているのがCommon Crawlコーパスです。これはインターネットのWebサイトをクロール(巡航)し、そこに掲載されているテキストデータをスクレイピング(データ取得)してコーパスにしたものです。
コーパスとは、文章や会話などを大量に集めて、コンピュータで処理しやすいように構造化した言語データベースです。Common Crawlのホームページを見ると「12年間のクロールで収集されたペタバイト単位のデータ」と記載されています。2008年からクロールとスクレイピング技術で集めたデータは、メタデータ(WAT)も付けられてAmazon S3に保存されており、誰でも無料でアクセスできます。このうち各言語の含有率は英語が50%程度であり、日本語は5%となっています。
WebText2は、Common Crawlコーパス以外のWebページのデータ、Book1とBook2は書籍データですが、どのような情報が使われたかについては明確にされていません。
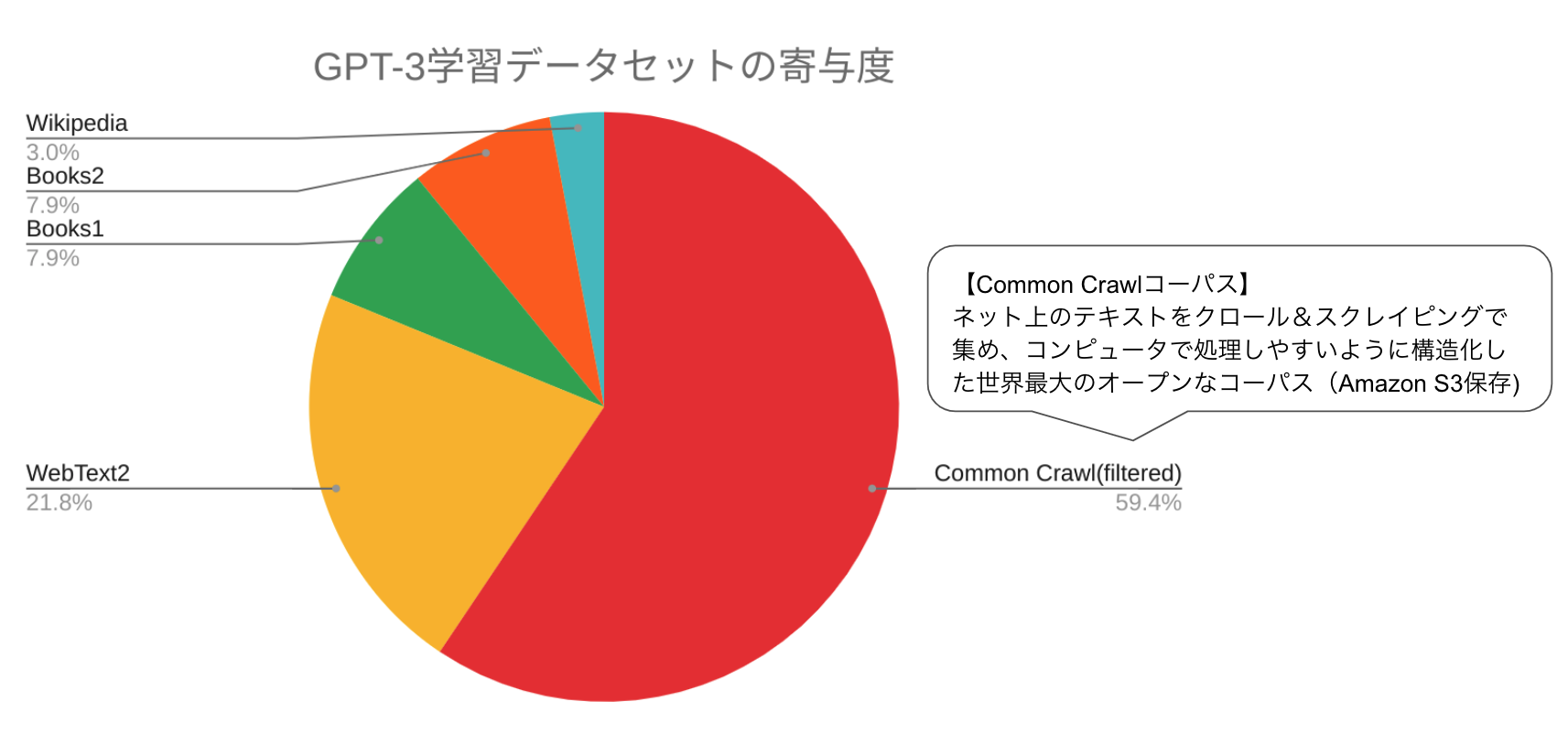
図2:GPT-3学習データセットの寄与度
日本語コーパス
Common Crawlのスナップショット(ある時点のデータを抜いたもの)で、フリーの日本語コーパスが公開されています。MC4はGoogleの多言語コーパスで、そこから日本語部分を抜き出したものです。OSCARはフランス国立情報学自動制御研究所(INRIA)のOrtizチームが各国語に分けて提供しているもの、そしてCC-100はFacebookのコーパスで、そこから日本語を抜き出したものです。
また、国立国語研究所がさまざまな書籍や雑誌、新聞、白書、ブログなどからデータを集めたBCCWJという日本語コーパスや音声データのコーパスCSJなどもあります。大規模言語モデルの出現により学習データの重要性が再認識されたことで、日本語のコーパスのさらなる充実が期待されます。
表:主な日本語コーパス
| データセット | サイズ | 提供元 |
|---|---|---|
| mC4 | 830GB | Google製データセットの日本語部分 |
| OSCAR | 260GB | INRIAが各国語のコーパスを提供 |
| CC-100 | 82GB | Facebook製データセットの日本語部分 |
| BCCWJ: 現代日本語書き言葉均衡コーパス | 約1億語 | 国立国語研究所 |
| CSJ: 日本語話し言葉コーパス | 約700万語 (音声データ) | 国立国語研究所 |
言語モデルの本質
ChatGPTのTransformer技術を説明する前に、言語モデルの本質について理解しておきましょう。AIには、分類(Classify)や予測(Prediction)、異常検知(Anomaly detection)などさまざまな技術分野があります。その中で、言語モデルは自然言語処理(NLP:Natural Language Processing)を中心としたAIです。
言語モデルの機械学習
言語モデルの本質は「次の単語を予測するAI」で、そのトレーニングは学習フェーズと推論フェーズからなる機械学習で行います。図3のように事前学習(Pre-training)で徹底的に人間の文章を叩き込み、学習済みモデル(Pre-trained Transformer)を本番で使って「推論」させます。
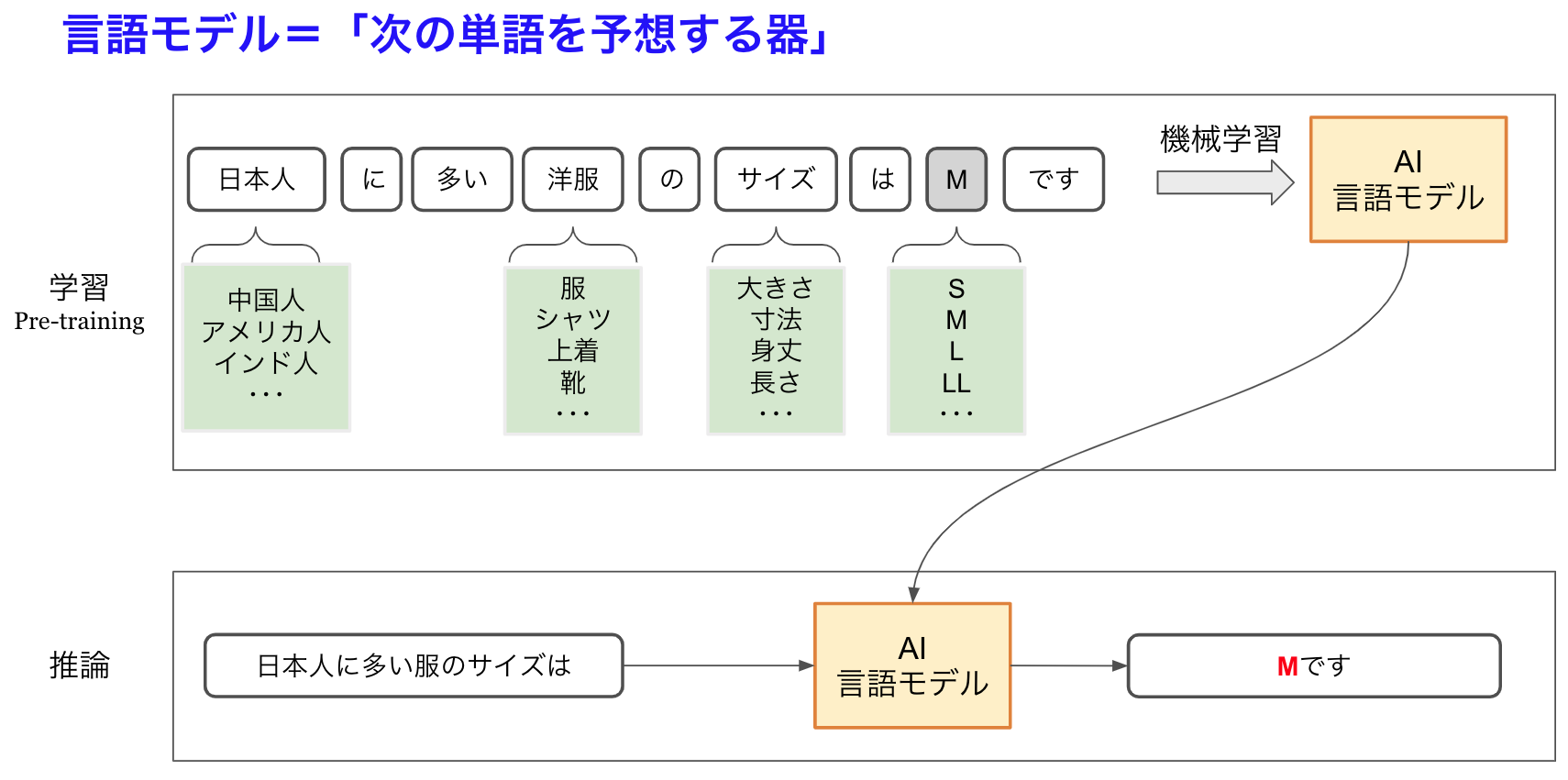
図3:言語モデルの機械学習
ここでは「日本人に多い洋服のサイズはMです」という文章を学習データとしてインプットしています。学習データには膨大な量のテキストが用意されており、「日本人」「洋服」「サイズ」「M」などのところに別の単語が入った文章データもあるわけです。これらを徹底的に学習することで「日本人に多い洋服のサイズは?」と聞かれた場合に、Mと回答する「次の単語予想」に強い言語モデルができるわけです。
この例はシンプルですが、実際は助詞の「の」にしても「は」や「も」や「に」などもさまざまなバリエーションがあり、それにより回答も変化します。ものすごい数の組み合わせがあるため、到底不可能に見えます。でも、人間だって長い年月をかけてこのような学習をし続けて、普通に会話できるレベルに達しているわけです。AIの場合は、24時間365日すごい処理速度のマルチGPUで大量データで勉強を行っているわけで、そう考えれば不可能ではないと理解できるのです。
LLMは連想ゲームの達人
我々はChatGPTの出現によりLLMの言語能力に驚いているわけですが、彼らは考えて答えているわけではありません。それよりも連想ゲームの特訓を死ぬほど行った次の単語予測器と考えた方が良いでしょう。
「日本人は」でピンと来たいくつかの続く単語を確率付きで出力し、「日本人は、夏は」で、また次に来る文章を予測する。そんなふうにインプットされた文章で反射的に浮かんだ単語を回答する連想ゲームの達人なのです。つまり、言語モデルが「次の単語を予測する器」だとしたら、大規模言語モデルは「連想ゲームの達人」なのです(図4)。
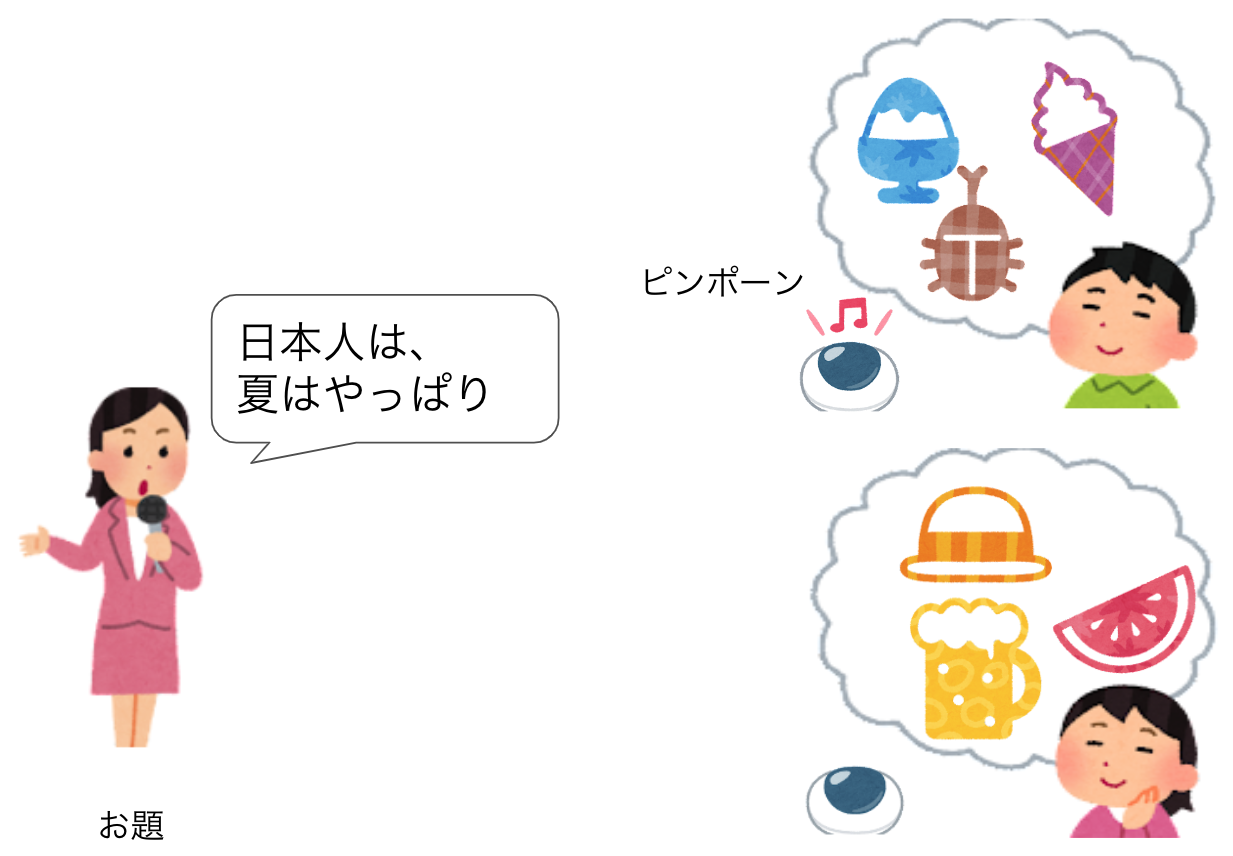
図4:大規模言語モデルは連想ゲームの達人
まあ、突き詰めて考えたときに、人間だって知識の中から考えて答えているのと、ぱっと浮かんだ単語を反射的に答えているのと、どこに境界があるのかは微妙です。しかし、大規模言語モデルが考えて答えているわけではないことを知れば、とりあえずは過度に脅威を感じる必要はなさそうです。と言いつつ、最近大規模言語モデルの「思考の連鎖」の研究が著しいので、これから考える力も身につけてきそうな不気味さも感じます。
大規模言語モデルは言語の天才
ところで、言語モデルをトレーニングして次の単語を推測できるようにしたものが、なぜ、プログラミングや作曲などもできるようになったのでしょう。図5を使って説明しましょう。
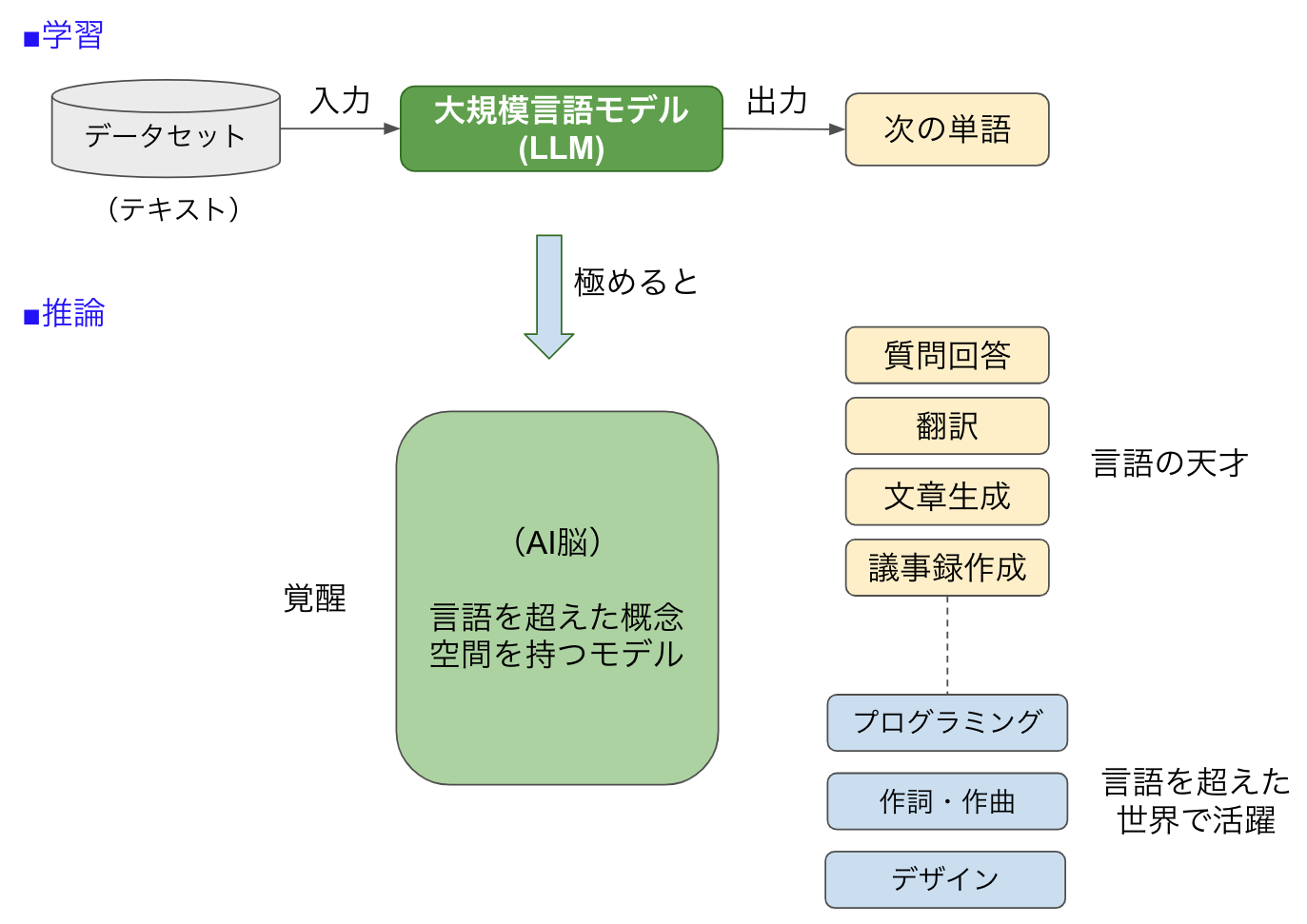
図5:大規模言語モデルの覚醒
大量のデータセットを使って、次の単語を連想するゲームを学習しまくった言語モデルは徐々に覚醒していきます。そして「質問回答」だけでなく「翻訳」「文章生成」「議事録作成」など、言語をいろいろ操れる天才の素質を見せてくれます。
このとき、言語モデルの頭の中には「言語を超えた概念空間を持つモデル」ができてきます。人間が自分の脳の仕組みをきちんと説明できないように、このAI頭脳がどのようになっているかは誰も説明できません。
翻訳の場合は、日本語の文章を入力して英語を出力させるトレーニングを行います。これも基本は「次の単語を予想する言語モデル」で、入力された日本語をAI能の空間でパターン化し、それを英語で出力するという形になります。例えば、和英翻訳を学習したLLMに「私はふるさとが好き」とインプットすると、AI脳がどういうロジックを使っているかはわかりませんが、「I love my hometown」とアウトプットするのです。
面白いのは、日本語や英語は単なる入出力のフォーマットにしか過ぎないということです。例えば、中国語と英語の翻訳を学習した言語モデルに「私はふるさとが好き」とインプットすると(たとえ日本語と中国語の翻訳を学習してなくても)「我愛我老家」などと翻訳してくれます。
つまり、日本語と英語というような2つの言語のペアで覚えているわけではなく、ある言語でインプットされた情報がいったん「AI脳」に変換され、それを別の言語にアウトプットしているだけなのです。GPT-4がポリグロット(多言語を話せる)なのは、この仕組みによります。
ChatGPTやGPT-4の学習データは圧倒的に英語が多く、日本語データはそれほど多くないのです。そのため英語で使用したほうが性能は良いわけですが、その割には日本語でもびっくりするほど優秀です。これも、英語圏の知識は英語データの方がもちろん豊富ですが、知識以外の部分はAI脳が処理しているからだと推定されます。
大規模言語モデルは言語を超えた叡智
大規模言語モデルの「次の単語予想」トレーニングを極めてゆくと、いつのまにか「質問回答」や「翻訳」などの言語処理だけでなく「プログラミング」「作詞・作曲」「デザイン」など多彩な採用を見せるようになります。まるで、子どもが急に、やらせてみたらなんでもできるように覚醒したかのようです。
これも原理はAI脳です。プログラミングも言語であり、音楽も譜面を読むという言葉があるように言語のようなものです。AI脳にとっては、日本語も英語もプログラムコードも楽譜もすべて言語のようなものなので、世界中のデータを教師データに使って、Attentionという技術で連想ゲームを教えさえすれば、ジャンルを問わず人間のようなアウトプットを作り出す才能を発揮できるわけです。
まとめ
今回は、以下の内容について学習しました。
- 大規模言語モデルが学習したテキストの量は、人間が一生で読む量より桁外れに多い
- GPT-3の学習データの6割は、ネットから取得したCommon Crawlコーパスである
- 言語モデルは「次の単語を予測する器」で、大規模言語モデルは「連想ゲームの達人」
- AI脳が「言語を超えた概念空間」を持つからこそ、連想だけでマルチになんでも行える
今回は大規模言語モデルの本質を中心に説明しました。次回からは、Attentionを中心としたTransformerモデルの説明や解説していきます。難しい式は使わず、図や例でわかりやすく説明するので、新しい技術に対する好奇心を一緒に楽しんでいきましょう!
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
