KubeCon China 2024、GPUの故障を検知するOSSを解説するセッションを紹介
KubeCon China 2024、GPUの故障を検知するOSSを解説したセッションを紹介する。
2024年11月27日 8:06
KubeCon China 2024から、MicrosoftのAzureのエンジニアとイギリスの自動運転システムのベンダーWayveのエンジニアとが共同で行ったセッションを紹介する。このセッションではGPUノードを使った機械学習ジョブにはアプリケーション、ネットワーク、オーケストレーターそしてハードウェアなど多数のコンポーネントが必要となり、複雑さが増していることを紹介して、多くの時間がかかる学習の段階で起こるエラーに対応するためのツールを解説する内容だ。

プレゼンテーションを行うWayveのSarah Belghiti氏
前半をWayveのSarah Belghiti氏が行い、後半のプレゼンテーションとデモをAzureでGPU周りのインフラエンジニアであるGaneshkumar Ashokovardhanan氏が行うという分担だ。

AzureのインフラエンジニアAshokovardhanan氏
●動画:Detecting and Overcoming GPU Failures During ML Training
セッションのタイトルは「Detecting and Overcoming GPU Failures During ML Training」というもので、GPUを長時間使用して処理を行う機械学習ジョブにおいて、関連するさまざまなコンポーネントのヘルスチェックをどうやって行うのか? を解説している。

機械学習ジョブにKubernetesが最適な理由
Belghiti氏は多数のGPUを使って分散処理を行う学習ジョブにはクラウドネイティブなシステムのプラットフォームであるKubernetesが向いているとして、基本的な特性を整理した。ここでは分散処理であること、ジョブをスケジューリングするツールが存在すること、GPUを利用するためのプラグインがNVIDIAから提供されていることなどを要因として挙げた。
その上でGPUのような複雑なハードウェアは、シンプルな構成のプロセッサに比べて故障する確率が高いことを紹介。ここでは具体的な例としてMetaの発表を引用し、2024年7月に発生した障害のうち、58.7%がGPU関連の障害だったとして、多くのGPUユーザーが抱えている問題を浮き彫りにした形となった。
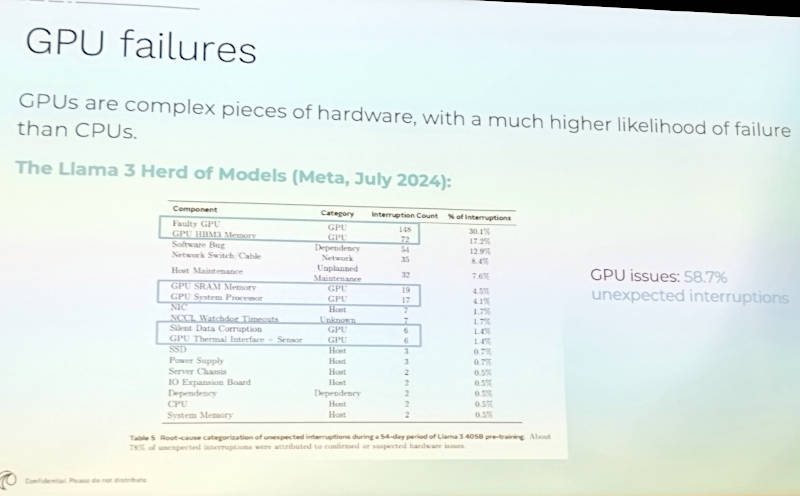
Metaでは2024年7月の障害の内、半分以上がGPU関連
またGPUの価格も高止まりしている現状で、高価なGPUが故障により稼働できないとすると経済的な損失は大きいと説明した。NVIDIAのデベロッパーカンファレンスでもいかに効率よくGPUをスケジューリングするのか? ということは何度も繰り返し語られる内容だが、それはハードウェアが正常に稼働していることが前提だろう。ハードウェア障害だけではなく、ソフトウェアに起因する異常停止や性能劣化、ネットワーク関連のトラブルなど、アプリケーションデベロッパーだけではなくインフラエンジニアにとっても大きな問題である。

障害、異常停止、性能劣化などさまざまな要因がインパクトを与えている
デベロッパーにとってもインフラエンジニアにとっても、異常に対応するのであれば最初に必要なのは検知することだ。最終的にはジョブを障害が発生したノードから移動させ、修理もしくは交換などの対応が必要になる。

検知してジョブを安全に移動させ、ノードを復旧もしくは交換するのがゴール
検知の最初の段階では、NVIDIAが提供するテストツールなどを使って事前にハードウェアやネットワークのヘルスチェックを行う必要があると説明。

異常があるノードでジョブが実行されないようにヘルスチェックを実行
ただし事前のチェックで正常と判定されてもジョブの実行中に異常が検出されることもあるとして、バックグラウンドで実行するヘルスチェックとワークロード、つまりジョブの中にヘルスチェックを組み込む方法があると説明。それぞれの長所と欠点を解説した。

ジョブ実行中のモニタリング
ジョブの実行中に以上が発生した場合は、ジョブのチェックポイントファイルを生成して他のノードに移行して続行するという方法を紹介した。チェックポイントファイルが巨大になってしまう場合、いかにそれを移動するのかという問題点に触れていたセッションもあったが、ここでは簡単な説明に留まっていた。
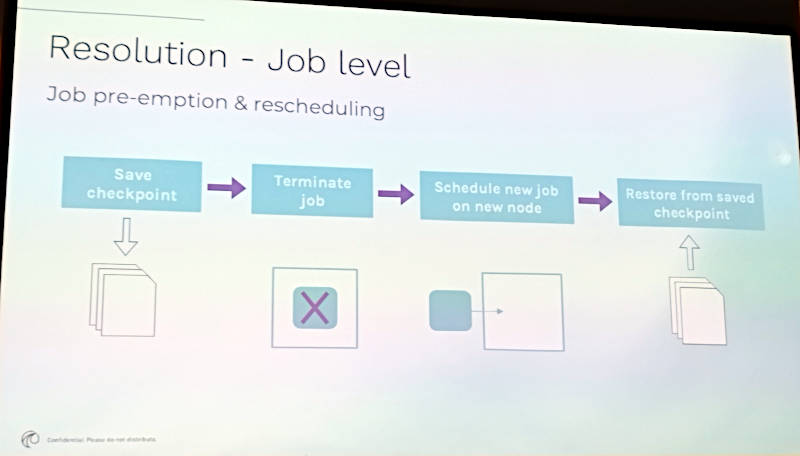
ジョブを中断して他のノードに移動する方法を解説
またノードレベルの検知ではヘルスチェックだけではなくメトリクスやログにも注目してエラー処理を行うことが必要だと説明。
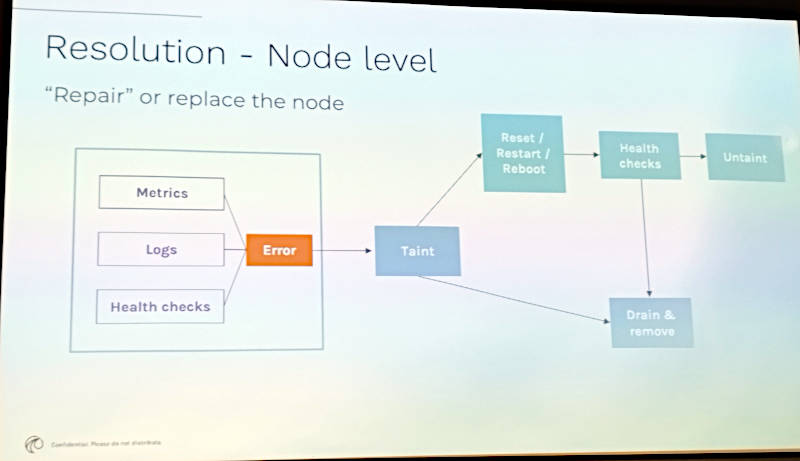
ノードレベルではヘルスチェックだけではなくメトリクス、ログも利用する
ここからはMicrosoftのAshokovardhanan氏に交代してインフラストラクチャーレベルでの対処方法を解説する内容となった。

Ashokovardhanan氏がインフラストラクチャーレベルの障害対策を解説
エラーのレイヤーには4つの段階が存在するとして、スライドで説明。ここではアプリケーションの一つ下のレイヤー、Kubernetesが担うオーケストレーターの部分に特化して解説を行った。

オーケストレーターレベルのヘルスチェックを解説
最初に紹介したのはKubernetesの公式の検知ツール、Node Problem Detector(NPD)だ。

Node Problem Detectorを紹介
このツールは、本来GPUに特化したチェックを行うものではないと説明し、カスタマイズされたヘルスチェックジョブを行うCron JobやLBNL Node Health Checkを紹介。他にもAzureが開発しオープンソースとして公開しているツールも存在することを説明した。ちなみにLBNLはLawrence Berkley National Laboratoryの略で、米国の研究機関由来のオープンソースツールである。Node Health Checkについては以下の公式サイトを参照されたい。

GPUに対応した各種ヘルスチェックツールを紹介
ここでは構成ファイルなどを見せながら紹介を行っているが、Azureのツールはまだ実験段階という但し書きがついている状態だ。
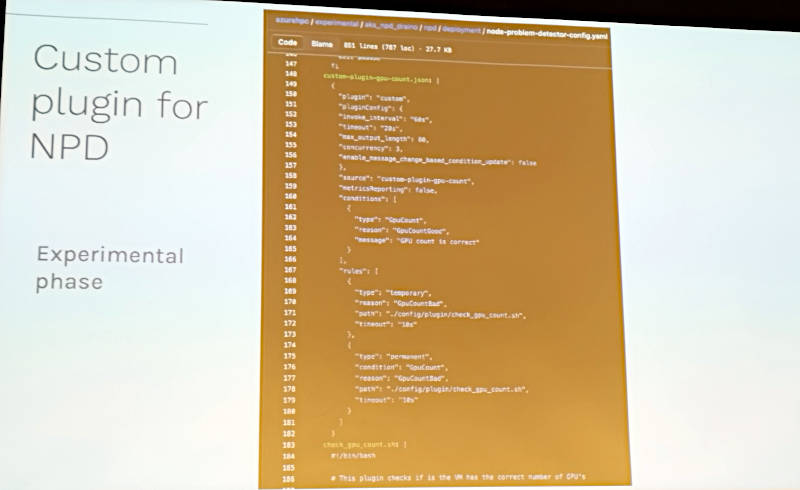
Azureのヘルスチェックツールはまだ実験段階
Kubernetesにおいてはエラーを検出するだけではなく、そのエラーの内容に応じて対処を行うRemedy Controllerが実装されていることを紹介。
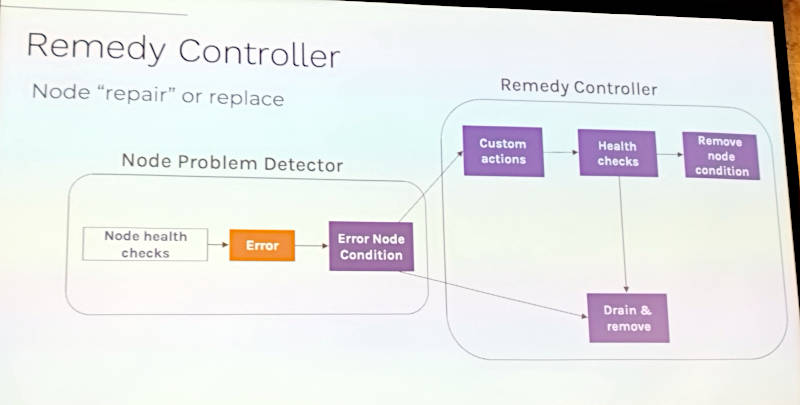
Remedy Controllerの紹介。エラーに対する対処を実装
他にもエラーのシミュレーションを行うツールやKubernetesのノードを実際に立ち上げずにシミュレーションとしてクラスターを起動するKWOKなども紹介され、Kubernetesのエコシステムに数多くのツールが存在していることを紹介した。

Kubernetesエコシステムのツールを紹介
KWOKについては以下の公式GitHubページ及びSIGのドキュメントサイトを参照のこと。
●参考:KWOK
●ドキュメント:Manage nodes and pods with kwok
ここからは実際にターミナルを使ってKubernetesのノードの状況を監視するデモなどを行った。
Kubernetesクラスターの内容を確認するデモ画面
GPUのヘルスチェックについてはまだ多くの課題が残っているとしていくつかを紹介。特にGPUの機種やネットワーク接続の設定などによって必要なテストが変わってしまうこと、ヘルスチェック自体が負担となってしまうこと、そして処置不可能なハードウェア関連のエラーとソフトウェア的に対応可能なエラーの切り分けが難しいことなどを挙げた。

学習ジョブに必要なリソースに対するヘルスチェックの難しさ
ここで他のツールも紹介し、LinuxからCUDAの処理中にチェックポイントを生成/リストアするツールCRIUやKubernetesのコミュニティにおいても多くの議論が行われていることを紹介した。

CRIUなどのツールを紹介
CRIUはNVIDIAのデベロッパー向けブログでも紹介されているツールで、x86ベースのLinux環境においてGPUの状態を保存、リストアするツールだ。
●NVIDIAによる解説:Checkpointing CUDA Applications with CRIU
●CRIU公式ページ:https://criu.org/Main_Page
冒頭の障害検知の部分以外はAzureのエンジニアが解説するセッションとなってしまい、WayveのBelghiti氏の出番が少なかったことが惜しまれるが、実際に機械学習を運用する際に高い確率でGPU関連の障害が発生していること、そしてそれに対応するツールも徐々に整備されていることが理解できる内容となった。
Wayveは自動運転システムを搭載した車輛を開発しているのではなく、OEMの形で自動車メーカーに提供するのがビジネスモデルのようだ。KubeEdgeを搭載する車輛そのものを製造するNIOとはビジネスモデルが異なるということだろう。クラウド側はMicrosoftのAzureがバックエンドという関係だろうか。今後の進化が楽しみである。
Wayveについては以下の公式サイトを参照されたい。
●Wayve公式サイト:https://wayve.ai/
- この記事のキーワード
この記事をシェアしてください
関連記事
KubeCon China 2024、Kubernetes上でMLジョブのフォルトリカバリーを実装したKcoverのセッションを紹介
2024年11月12日 9:16
KubeCon North America 2025、BloombergによるAIをマルチクラスターで実装したKarmadaのセッション
2月11日 5:59
KubeCon China 2024、LLMを用いてロボットの操作をシンプルにするDoraのセッションを紹介
2024年11月19日 9:11
GTC 2019ではFacebook、Google、Walmartなどによる人工知能関連のセッションが満載
2019年4月18日 6:00
KubeCon China 2025、DaoCloudが解説するLLM開発高速化のセッションを紹介
2025年10月10日 6:00
KubeConChinaのキーノートにMS、IBM、Rancher Labsが登壇
2018年12月25日 12:23
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
