KubeCon China 2024、Kubernetes上でMLジョブのフォルトリカバリーを実装したKcoverのセッションを紹介
KubeCon China 2024から、Kubernetess上でMLジョブのフォルトリカバリーを実装したKcoverのセッションを紹介する。
2024年11月12日 9:16
KubeCon China 2024から、中国のクラウドプロバイダーDaoCloudのエンジニアが、機械学習ジョブの障害対策のためのオープンソースソフトウェアKcoverを解説したセッションを紹介する。DaoCloudは2014年に創業し、上海に本社を置く中国のパブリッククラウドプロバイダーだ。クラウドネイティブなオープンソースソフトウェアに対しては大きな貢献を行っていると、自社のホームページで訴求していることからもわかるように、このカンファレンスでも多くのセッションでスピーカーを登壇させていた。

プレゼンテーションを行うDaoCloudのエンジニア
GPUクラスターではさまざまな要因でエラーが発生する
セッションを担当したのは、Fanshi Zhang氏とKebe Liu氏、ポディウムに立って解説をしているのがFanshi Zhang氏で、その右に立っているのがKebe Liu氏だ。セッションのタイトルは「Sit Back and Relax with Fault Awareness and Robust Instant Recovery for Large Scale AI Workloads」というもので、分散実行される機械学習のジョブの障害検知とリカバリーを行うツールKcoverを紹介する内容だ。
●動画:Sit Back and Relax with Fault Awareness and Robust Instant Recovery for Large Scale AI Workloads
最初に機械学習におけるトレーニングプロセスについて解説し、ジョブがGPUに分散されて実行されることを説明。その中でさまざまなエラーが発生することは避けられないと語った。

分散学習ではGPU、ネットワーク、フレームワークなどさまざまな要素が必要
そのエラーについて例を挙げて説明した。ここではGPUのハッスルエラーメッセージを例に説明を行っている。
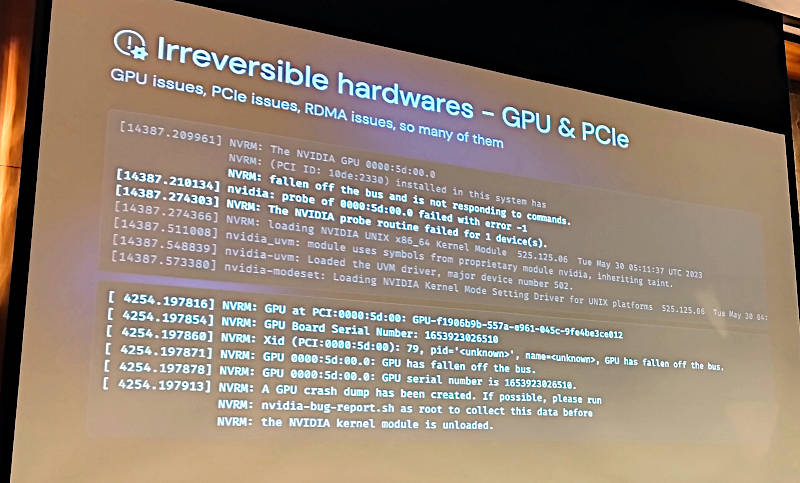
さまざまな要因でエラーが発生する例を紹介
特に複数のGPUと接続して通信を行うNVIDIAの通信ライブラリーNCCL(NVIDIA Collective Communication Library)についても実際のエラーメッセージを見せて、エラーは避けられないことを強調した。

NVIDIAのGPU間通信ライブラリーのエラーを紹介
また当然だが、PyTorchにおいてもエラーが発生することを紹介。単にGPUを複数使って分散学習を行うと言っても、多くの要因でエラーが発生することを説明した。
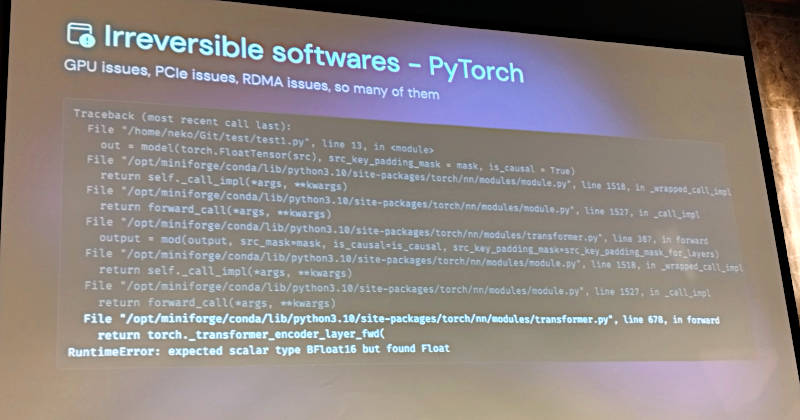
PyTorchでもエラーは発生する
またエラーについて「Irreversible(回復不能)」という形容詞を使って説明している点について説明を行った。

回復不能なエラーになってしまう分散学習の特徴を解説
ここでは分散学習のジョブはKubernetesの文脈で言えば単なるデプロイメントというよりもステートフルセット、つまり状態を持ち長期にCPU/GPUを占有してしまうジョブであること、複数のノードが協調して実行するためにはノード間のトポロジーや接続の状態、データ転送に使うバンド幅などを計算した上でどのノードでどのジョブが実行されるのかを決定する必要があり、コストが高いことなどを解説した。

複数のノード間でのエラーの伝搬が往々にして発生する
そして最初に挙げたようにさまざまなハードウェアやソフトウェアコンポーネントにおいてエラーが発生する状況は、Kubernetesなどのクラウドネイティブなシステムでは前提条件となっているが、相違点として分散処理のためのアルゴリズムがPyTorchやNCCLの中に組み込まれていること、Kubernetes Operatorではエラーの検知からリカバリーなどの動作が実装されていないこと、GPUに関連するハードウェア、ドライバー、ライブラリーなどにおける原因解析が不十分であることなどを挙げて、分散学習の運用はそれほど楽ではないことを強調した。これはDaoCloud自身がd.runというGPUサーバーをパブリッククラウドサービスのひとつとして提供している経験から来ている生の感想だろう。

分散学習の運用の難しさを説明
またエラーを検出してその原因を解析したとしても、エラーが発生したハードウェア以外のノードでジョブを実行するためには、トレーニングデータの状態を保存するCheckpointsを利用して再開する必要があると説明。しかしCheckpointsファイルは非常に巨大なサイズ(例えばLlama2では80GBを超える場合も)になってしまうことを例に挙げ、分散学習においてエラーへの対応は容易ではないと説明した。

学習データのチェックポイントファイルが巨大になる問題を説明
それらを考慮して実際に分散学習の処理時間が膨大になってしまうことを数式で解説。ここでは処理時間はジョブの実行時間だけではなく、チェックポイントファイルの保存や読み込みに必要な時間をノード数やGPUの数で乗算したものになるとして、単なる処理時間だけでは収まらないことを示した。

分散学習に必要な処理時間はジョブの実行時間だけではないことを説明
エラーから回復するための処理時間を減らすためには診断の時間を減らし、回復にかかる時間を減らし、チェックポイントファイルの処理の高速化するしかないと説明した。

エラー発生時の回復のための時間を減らす要因を紹介
そのために多くの研究がなされ、公開されている論文なども存在することを説明。ここではMetaが公開している24,000台のGPUクラスターでエラー処理にかかる時間を大幅に削減した事例を紹介。これはMetaが発表した下記のLlama3の公式ブログに書かれている内容を引用している。

Metaの例を挙げてGPUクラスターのエラー処理の高速化を紹介
●参考:Introducing Meta Llama 3: The most capable openly available LLM to date
他にもKubernetesのSIGで開発されているJobSetやANT Groupが開発しているDLRoverなどを紹介。DaoCloud以外にもGPUクラスターのエラー処理に悩みを抱えているユーザーがいることを示していると言えるだろう。

JobSetやDLRoverなどの他のソフトウェアを紹介
Kcoverの解説
そこからプレゼンテーションをKebe Liu氏に譲ってKcoverを解説する内容となった。

Kcoverの解説が始まった
Kcoverはこれまで説明してきた分散学習におけるエラー検知、ノードの安全なシャットダウン、ノードのジョブの回復、定期的なノードのヘルスチェック、マイグレーションを行うために開発されたツールである。開発途上であり、まだ部分的な機能しか実装されていないことが「we solved the problems, partially」という一文に表現されていると言える。

Kcoverの機能を紹介
Kcoverのアーキテクチャーを解説するスライドではCollectorとRecovery Managerというモジュールが解説された。
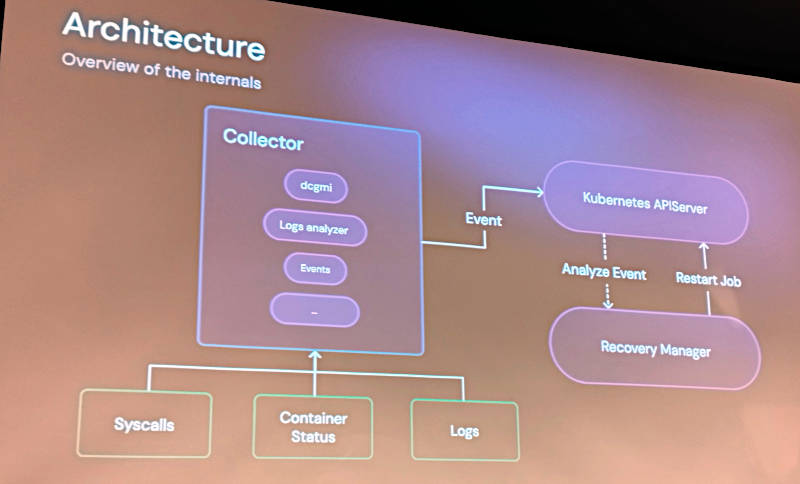
Kcoverのアーキテクチャーを紹介
具体的な機能について解説するスライドではエラー収集にラベルを使うこと、さまざまなエラーと終了のコードを収集した後にジョブのシャットダウンを安全に行い、リカバリーが始まることなどを説明した。NVIDIA製のさまざまなテストツールなどを組み込むことで、定期的なヘルスチェックを行うことなども説明された。

Kcoverの具体的な動作を解説
インストールやラベルの設定などについても説明を行った。Kubernetesの作法に従った動作スタイルを踏襲していることがわかる。

使い方を説明。インストールはHelmを利用
最後に再度Fanshi Zhang氏がプレゼンテーションを行い、今後の予定、コミュニティとの協調について説明を行った。

コミュニティと協調して開発を行うことを説明
しかし実際にKcoverのGitHubページを参照してみればわかるが、コントリビュータは回のセッションの登壇者2名だけがリストされているのが見てとれる。つまり、DaoCloudのGPUクラスター運用のためのソフトウェアという感が強い。実際にはDaoCloud社内にGitリポジトリーが存在して開発され、DaoCloudに依存しない仕様のコードだけがGitHubに公開されているという状態なのではないだろうか。
今回のKubeCon Chinaでは多くのこれまで聞いたことのないオープンソースソフトウェアが紹介されていたこと、中国ではGitHubよりもGiteeがリポジトリーサービスとしては台頭していることなどを考えると、中国以外では流通していないオープンソースソフトウェアが多く存在することは明らかだろう。
●Kcoverの公式GitHubページ:https://github.com/BaizeAI/kcover
香港の会場では元Juniper NetworksのVPだったRandy Bias氏が参加しており、久しぶりに対面したが、Bias氏も初めて聞く中国製のオープンソースソフトウェアの多さに驚いていた。「中国のオープンソースは自国内で独自に進化しているけど規模も大きいから、ガラパゴス島というよりはガラパゴス大陸だね」とコメントしたところ「気に入った。何かに使わせてもらうよ」と笑っていた。ちなみにBias氏の現在の仕事はMirantisの「VP Open Source Strategy and Technology」だという。
2018年に行ったRandy Bias氏のインタビューは以下から参照されたい。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
