ロボットと会話する仕組み~音声認識
ロボットと会話する仕組み~音声認識
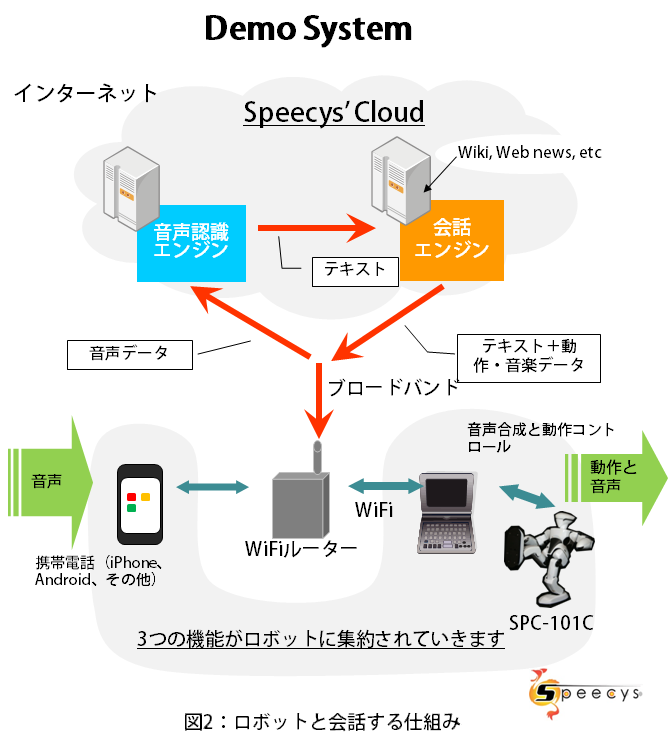
1ページでご紹介した動画をご覧いただけたことと思います。ロボットと人間が円滑にコミュニケーションをしていますね。その原理を少しご説明したいと思います。図2は、この動画を作ったシステムの構成図です。
図のオーナーは、このシステムではiPhoneに向かって話しかけています。これは将来的にはロボット内のマイクに向かって話しかけることになります。
iPhoneをマイク代わりに使い、そこで拾った音声を簡易処理した後、WiFiとルーターを通じてインターネット上の音声認識エンジンに送っています。このように音声認識を1か所で行うのではなく、サーバーで行うシステムを“DSR(Distributed Speech Recognition)方式”と呼んでいます。この方が認識用の辞書を複雑かつフレキシブルに利用できるので、認識率がぐっと上がります。
この方式は、アドバンスト・メディア社(http://www.advanced-media.co.jp/)から、iPhone用の音声認識メールツールとして無料配布されているので、興味のある方はダウンロードしてみてください。普通にしゃべるだけでメールが書けてしまうので、驚かれるのではないかと思います。
そこで音声認識して得られた音声テキスト情報を今度は会話エンジンに送ります。会話エンジンでは、あらかじめ設定されたシナリオに基づいて受け取った音声のテキストを処理し、会話を作ります。
こういった会話エンジンは、最近いろいろなところで使われており、よくある例では企業などが電話によるユーザーの質問などに自動で応答する場合などがあります。そのほかにも、Web上でアバターのキャラクターと会話をするサイトがかなりありますので、ご存じの方も多いのではないかと思います。
さらに、実際ロボットに使うにはエンターテインメント性が重要になるので、楽しい会話ができるように工夫する必要があります。
ロボットと会話する仕組み~会話エンジンと音声合成
音声テキスト情報を送られた会話エンジンでは、得られた会話をもとに、それにふさわしいロボットの動きや音楽などを付加して、会話のテキスト情報をロボットに送ります。
ロボットでは、この会話のテキスト情報を音声合成(TTS:Text-To-Speech)し、ロボットの動きを付加し、音楽なども付加してロボットのコンテンツとして再生します。
また、オーナーからの要望でニュースを聞いたり、Wikipediaに質問があった場合には、会話エンジンがインターネット情報にアクセスしてテキスト情報を入手し、作成する会話の中にそれらを組み込み、ロボットで再生させます。
こういった会話システムで重要なのは、
・音声認識の精度
・いかに自然な会話を合成するか
・認識失敗しても会話を成り立たせる融通性
にかかっています。特に、自然な会話の合成は、技術的なことばかりではなく、音声認識がうまくいかなかった場合にでも、いかにオーナーを迷わすことなく自然な対応をするか?といったコンテンツ作成のノウハウが重要になってきます。
簡単に言えば、認識が失敗しても会話としては成り立っていれば良いわけで、“適当に”会話を成り立たせてしまうといった融通性が大事になってきます。
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
