| ||||||||||||
| 1 2 3 次のページ | ||||||||||||
| テキスト処理の流れ | ||||||||||||
第3回の今回は、これまでとは話の内容を転換して、テキストマイニングの技術的な内容について言及していきたい。テキストマイニングを支える技術には、「自然言語処理技術」と「データマイニング技術」がある。 実は自然文のテキストデータは、そのままの状態では分析することができない。そのため、「自然言語処理技術」の形態素解析や構文解析といった処理を行い、単語の出現の有無などを表現するために定量的なデータに変換する。 「データマイニング技術」としては、同時に出現する単語間の関連性を見る「アソシエーション分析」、テキスト間の類似性からグループ化するのに利用される「クラスター分析」などがある。 では実際に、野村総合研究所(NRI)が自社開発したテキストマイニングツール「TRUE TELLER」における処理を参考にして、具体的なテキストデータ処理の流れを見ていこう。 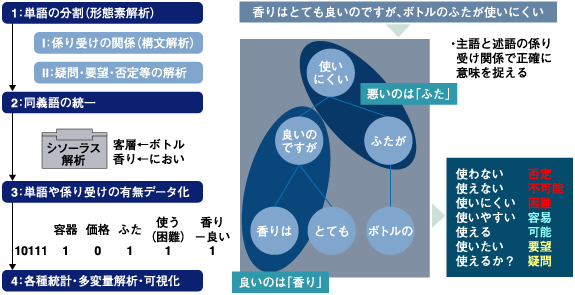 図1:テキストデータ処理の流れ (画像をクリックすると別ウィンドウに拡大図を表示します) まず、図1のチャートを見ていただきたい。ここに掲げる1〜4が基本的な分析系テキストマイニングの処理の流れを示している(なお図中のI〜IIはTRUE TELLERの特徴であり、詳しくは次項で述べる)。 テキストマイニングを行うには、最初に自然言語処理によって文章を「形態素」と呼ばれる単位に分解する。これは「形態素解析」と呼ばれる処理だ。なお形態素とは、これ以上細かくしてしまうと意味を成さなくなってしまう最小の文字列を意味する。これは単語レベルの単位に近い。そこであえて本連載では、理解しやすいよう「単語」という表現で説明を進める。 日本語の文章は数値データと異なり、単語が連続して記述されるため、このような処理が求められるのだ。また形態素解析では単語に分解するだけでなく、それぞれの単語の品詞(名詞、動詞、形容詞など)を把握することも可能だ。 次の処理として、同義語の統一を行う。例えば「価格」「値段」などを、代表的な単語に統一してまとめることだ。ひらがなやカタカナ、固有名詞や省略形の表現なども、この段階で統一されることになる。なおTRUE TELLERでは1つ1つ手作業で同義語を入力する手間を回避するために、同義語登録支援機能を利用することもできる。 続いて第3段階では、「各テキストにどの単語が出現しているのか」といった単語の出現パターンを抽出し、統計処理が可能な数値データへの変換を行う。例えば1つ目のテキストデータには「香り」や「容器」が含まれているかどうかなど、データベース上で0/1の数値情報で保持する。 そして第4段階では、前段階で抽出した出現パターンを基に統計処理を行う。これで各種分析作業のための準備が完了する。 | ||||||||||||
| 1 2 3 次のページ | ||||||||||||
| ||||||||||||
| ||||||||||||
| ||||||||||||
-
人気記事ランキング
-
-
連載


新着記事
焦りは禁物?「特化」の前に「汎用」を。エクサウィザーズが語る東海製造業における生成AI成功の秘訣 7月16日 6:30 SUSE、インフラのレジリエンスとオープンソースAIで日本のDXを加速——ベンダーロックインからの脱却を支援 7月16日 6:20 「HAMi」でKubernetes上のGPUメモリ分離の仕組みを理解し、共有を試してみよう 7月15日 6:30 「C/C++」の「RayLib」でコンソールゲーム「Color」を開発してみよう 7月15日 6:30 Gartner、エージェント型AIによってエンタープライズ・アプリケーション向け支出の2,340億ドルがリスクにさらされるとの見解を発表 7月14日 6:30