| ||||||||||||
| 前のページ 1 2 3 次のページ | ||||||||||||
| TRUE TELLERの構文解析 | ||||||||||||
さらに深い分析を行う場合、TRUE TELLERでは構文解析という処理を行っている。さて、この「構文解析とは何か」について、もう少し深く見ていこう。 従来のテキストマイニングで行う形態素解析では、文章内での単語の出現状況を把握するのみで、単語間のつながりを判別することは不可能であった。これに対して構文解析は、文章を単語間に分割した後、文法的なつながり(係り受けの関係)を判断する技術である。 例えば主語と述語の関係や、修飾語と被修飾語の関係の把握を行う。これによって、より正確で、かつ詳細な文章の内容の判断ができる。「何が良くて、何が悪いのか」という、文章で最も重要な情報を正しく知ることが可能になる。 この構文解析については、具体的な例をみていこう。今、著者は2年前に購入したノートパソコンでこの原稿を書いている。購入時は見た目が良かったのだが、使っていると今ひとつ性能が悪く悩んでいる。そこで、「デザインは良いけど、性能が悪い」という著者のコメントを解析してみよう。 この文章に形態素解析を行うと、以下のようになる。 「デザイン/は / 良い/けど / 性能/が / 悪い」 このまま統計処理を行うと、1つの問題が発生する。例えば著者のような表現を用いた発言が多い場合には、単純に単語の同時出現件数を集計すると「性能 / 良い」の組み合わせが非常に多いと判断してしまうことがある。果たしてこのノートパソコンは、性能が良かっただろうか。 一方、形態素解析を行った結果をさらに構文解析にかけると、前後関係を捉えて判断してくれる。その結果前述の通り、文法的には主語と述語の関係や修飾語と被修飾語の関係を捉えてくれるため、「良いのはデザイン。悪いのは性能。」と正しく判断することができるのだ。 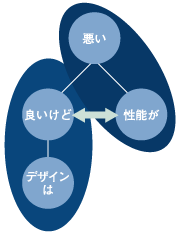 図2:構文解析結果 複数の係り受けも判断できる。例えば、「店員の説明や分厚いマニュアルは、理解でなきかったよ、私には。」といった文章があった場合、表1のように判断できるのである。
表1:判断結果 また上記の判断に関するTRUE TELLERでの解析結果を図3に示す。 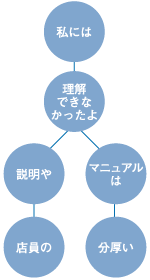 図3:構文解析結果 | ||||||||||||
| 前のページ 1 2 3 次のページ | ||||||||||||
| ||||||||||||
| ||||||||||||
| ||||||||||||
-
人気記事ランキング
-
-
連載


新着記事
焦りは禁物?「特化」の前に「汎用」を。エクサウィザーズが語る東海製造業における生成AI成功の秘訣 7月16日 6:30 SUSE、インフラのレジリエンスとオープンソースAIで日本のDXを加速——ベンダーロックインからの脱却を支援 7月16日 6:20 「HAMi」でKubernetes上のGPUメモリ分離の仕組みを理解し、共有を試してみよう 7月15日 6:30 「C/C++」の「RayLib」でコンソールゲーム「Color」を開発してみよう 7月15日 6:30 Gartner、エージェント型AIによってエンタープライズ・アプリケーション向け支出の2,340億ドルがリスクにさらされるとの見解を発表 7月14日 6:30