| ||||||||||||||||||||||||||||||||||
| 1 2 3 次のページ | ||||||||||||||||||||||||||||||||||
| 運用管理のもう1つの肝:運用監視 | ||||||||||||||||||||||||||||||||||
第2回では、統合運用管理ツールであるHinemosのジョブ管理機能の使い方を説明しました。最終回の今回は、運用管理のもう1つの中心業務である運用監視におけるHinemosの活用法を紹介します。 | ||||||||||||||||||||||||||||||||||
| Hinemosでのシステム運用監視 | ||||||||||||||||||||||||||||||||||
Hinemosでは、NMS(Network Management System)などで監視するネットワークレイヤから、httpサーバのレスポンスのようなアプリケーションレイヤまで、統一的な操作で設定・監視を行うことができます。Hinemosで監視可能な項目を表1に示します。
表1:Hinemosで行える状態監視項目 Hinemosの運用監視では、2つの観点でシステムの状態を把握します。1つは定期的なポーリングによって把握した管理ノードの状態を表示する「ステータス画面」です。例えばping監視によるステータス表示をオンにした場合、pingが届いていなければ赤の「危険」と表示し、その状態が改善しpingが届くようになると緑の「通知」と変えて表示します。 2つ目の観点は、ログや重要な状態をイベントとして表示管理する機能です。pingの不達時にイベントを出力する設定をしている場合は、pingが届かなかったときに赤の「危険」のイベントを出力します。これにより、いつの時間帯にネットワーク障害があったかという履歴がすぐに把握できます。 | ||||||||||||||||||||||||||||||||||
| 通常の運用監視 - 簡単に状態を把握したい | ||||||||||||||||||||||||||||||||||
通常の運用監視として、ミッションクリティカルなシステムや大規模システムでは、オペレータが常時または定期的に管理画面を確認するといった運用が多いでしょう。また一般的なシステムでは、異常が発生した際にメールなどで通知するというような場合もあるでしょう。 管理対象のシステムに問題がない時には、管理負荷をできるだけ下げるためにも、システムが正常であることを簡単に確認できることが求められます。 Hinemosの統合監視画面では、多数の監視項目をまとめて一番重要な状態を表示します。「第1回:Hinemosができること」で説明したようにHinemosでは管理対象ノードをグループ化して階層管理することができます。統合監視画面でもノードの状態はノードが所属する上位のグループに伝搬されます。 つまり、管理対象の最上位グループの状態が正常ならば、下位に属するノードにも問題が発生していないということになります(図1)。これにより、管理対象のサーバやネットワーク機器が多数存在しても、簡単に状態を把握することができます。  図1:Hinemosの統合監視画面 (画像をクリックすると別ウィンドウに拡大図を表示します) 管理対象ノードに問題が発生した場合には、通知設定によりメール通知を実行したり、事前に定義しておいたジョブを実行させることができます。さらに、この通知は回数や時間を設定できますし、また「警告 → 危険」といった状態の遷移があった場合にのみ出力することも可能です(図2)。システム要件に応じた柔軟な設定が可能なので、確認に時間を要したり無駄なメールに悩まされることがありません。  図2:細かな制御が可能な通知設定 (画像をクリックすると別ウィンドウに拡大図を表示します) Hinemosの初期状態では「危険」「不明」「警告」「通知」の順で重要度が高くなっており、重要度の高いイベントやステータスから対応することができます。この重要度はカスタマイズすることができ、例えば複数のサーバのうち1台でも正常であれば、Hinemosとして正常(通知)として判定することもできます(図3)。 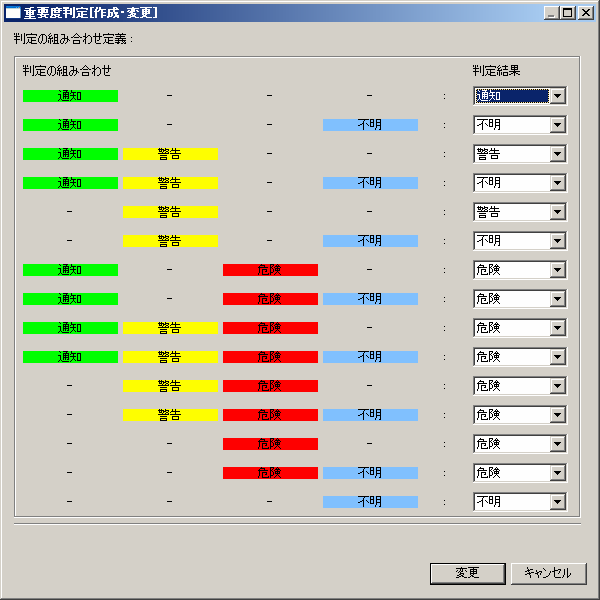 図3:判定基準のカスタマイズ (画像をクリックすると別ウィンドウに拡大図を表示します) | ||||||||||||||||||||||||||||||||||
| 1 2 3 次のページ | ||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||
-
人気記事ランキング
-
-
連載


新着記事
AIはコードを書ける。では、ソフトウェアエンジニアは何をするのか 8月3日 6:30 Meta、AIグラス助成プログラム 30団体を採択、Roblox Plus、新たなカスタマイズ機能を順次展開 ほか 8月3日 6:00 「Proxmox VE」とは? 製品群の全体像と仮想化基盤として注目される理由 7月31日 6:30 LFがOSSの脆弱性協調対応イニシアティブ「Akrites」を発足、CRA準備状況レポートは改善どころか悪化、ほか 7月31日 6:20 NVIDIAら37社が「Open Secure AI Alliance」設立――AIエージェントのセキュリティは重みの非公開では守れない 7月30日 6:20