モデル推論をKubernetes上で行うKServeのオンラインセミナーを紹介
モデル推論をKubernetes上で行うKServeのオンラインセミナーを紹介する。
6月3日 6:00
The Cloud Native Computing Foundationのオンラインセミナーから、大規模言語モデルなどのAIワークロードのためのフレームワークKServeを解説するセッションを紹介する。動画は以下から視聴可能だ。
●動画:Cloud Native Inference at Scale - Unlocking LLM Deployments with KServe
プレゼンテーションはデモと説明を分担して実施
プレゼンテーションを行ったのはNutanixの2人のエンジニア、Snehlata氏とJay Prasad氏で「Member of Technical Staff」というタイトルとなっているため、所属部署やポジションなどは不明だが、エンジニアであることは間違いないだろう。Nutanixはハイパーコンバージドインフラストラクチャーのベンダーとして唯一生き残っている独立系ベンダーだ。過去にはNutanixのハードウェア上でKubernetesを実装したNutanix Karbon(Nutanix Kubernetes Engineに改名)やパブリッククラウドとも連携するNutanix Kubernetes Platform(NKP)などを開発、提供している。最後のスライドでNKPを推奨しているところから、Kubernetes上で大規模言語モデル(LLM)実行のためのKServeのコミュニティで活動しているということだろう。Kubernetesの上でLLMが実行可能になることで、NutanixのNKPでの利用も拡がることを期待しているのは間違いない。
まずはKServeの概要についてPrasad氏が説明を行った。

KServeはCNCFのインキュベーションプロジェクト
KServeはCNCFのインキュベーションプロジェクトとしてホストされており、LLMの実行をKubernetes上で実装することが主なタスクだ。

コントロールプレーンとデータプレーンに分けてKServeを解説
KServeにはコントロールプレーンとデータプレーンが存在し、データプレーンではOpenAIのAPIに準拠したインターフェースが用意され、コントロールプレーンはデータプレーンで実行されるLLMのライフサイクルをサポートする機能を果たすと解説した。
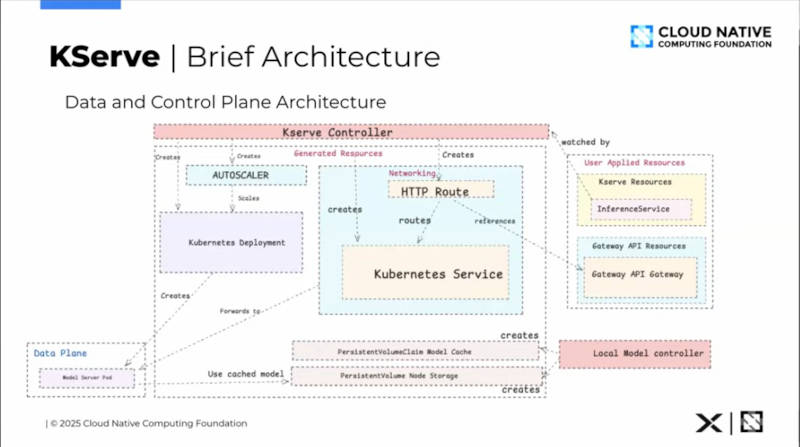
KServeのアーキテクチャー図
このスライドではアーキテクチャー図を使って説明。中央に大きく描かれているのがコントロールプレーンである。KServeコントローラーがオートスケーラーとネットワークのためのリソースを生成し、左に小さく書かれているデータプレーンであるLLM実行の本体が起動され、Gateway APIを使ったネットワークリソースがデータ通信を管理するという内容だ。
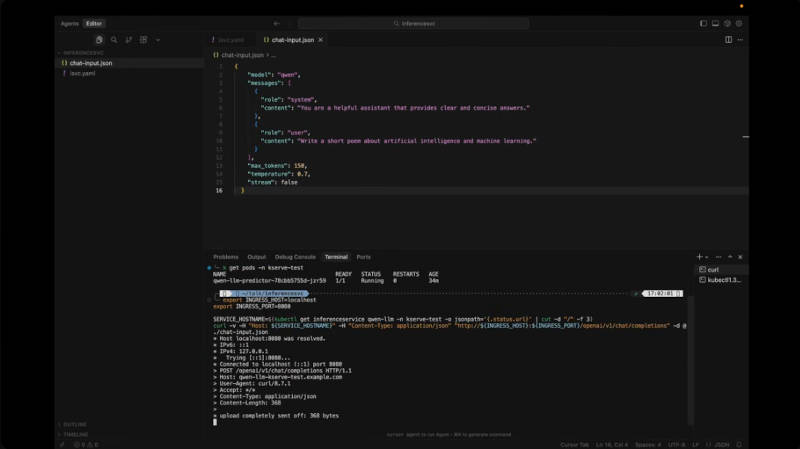
チャットを行うデモを紹介
ここからKServeのドキュメントを参照しながら、初めて生成AIジョブを実行する方法を解説した後にコマンドラインを使ったデモを実施。ここではQwenのモデルをPodとして実行した後にHTTPのポートを設定、コマンドラインから質問を送るというデモだ。
ここからはGateway Inference Extension(GIE)と呼ばれるルーティングの機能をSnehlata氏が解説する内容に移った。

モデルへのルーティングを行うGateway Inference Extensionを解説
これはKubernetesの新しいネットワークスタックであるGateway APIを拡張したもので、モデル名によるルーティング、単純なラウンドロビンではなく、GPUの使用率などに応じたロードバランシングなどを可能にする拡張機能である。
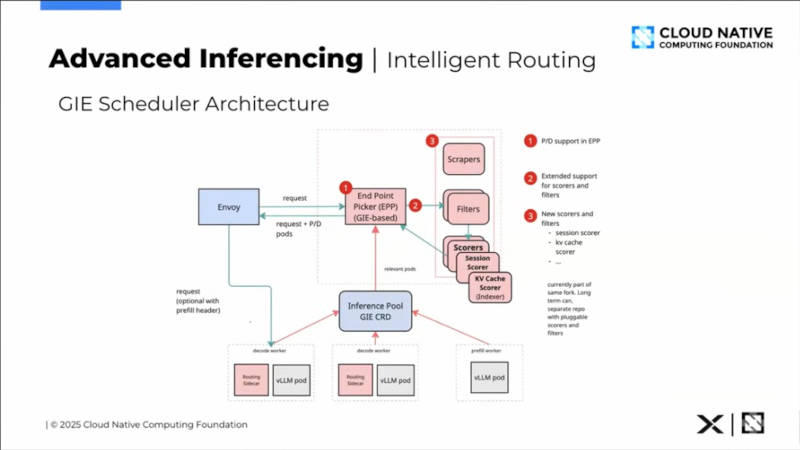
GIEのスケジューリングアーキテクチャーを解説
そしてGIEがどのようにしてスケジューリングを行うのか? を図を使って解説。クライアントから送られてきたリクエストは、Envoyを経て処理を実行するPodを選択するEnd Point Pickerによってリクエストが送られるPodが決定される。その際に単にモデル名の指定に従うだけではなく、GPUの稼働率やキューの長さ、モデルの状態(LoRAがロード済みかどうか)などによってもスケジューリングを変更できるため、資源を効率的に使うことが可能になる。
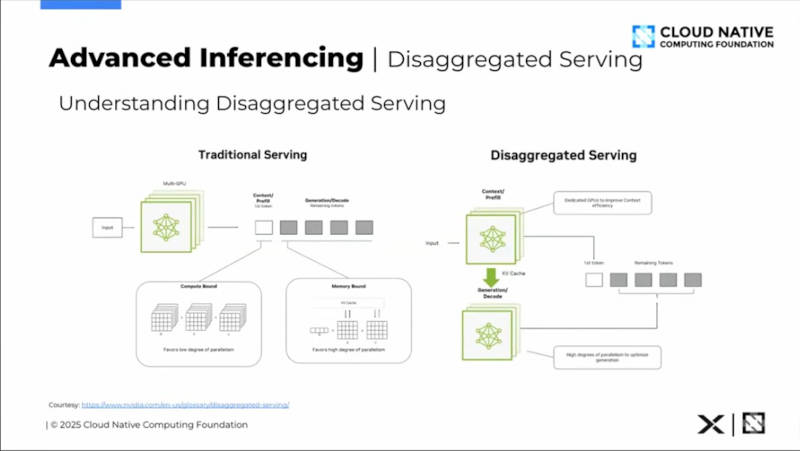
Disaggregated Servingの説明
機械学習におけるDisaggregated Servingはゲートウェイとモデル実行を分離する機能とLLMのPrefillとDecodeを分離する機能の2つの面を持つが、ここで解説されているのはLLMにおけるPrefillとDecodeを分離して別のGPUサーバーでそれぞれ実行することで効率を上げる機能の方である。
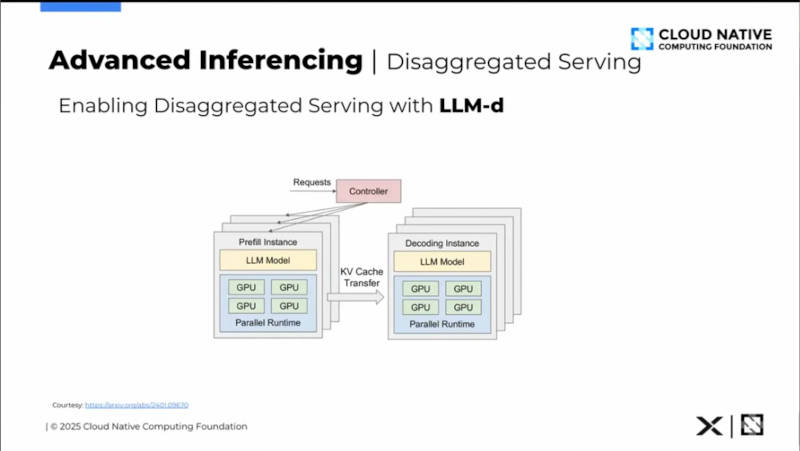
PrefillとDecodeを分離する際に使われるのがllm-d
このスライドではPrefillとDecodeの分離に際して、オープンソースのllm-dを利用していることが解説されている。ここからはKServeの内部ではLLMInferenceServiceと呼ばれる機能の中で、llm-dが果たす役割を解説する内容になっている。

LLMInferenceServiceの特徴を解説
生成AIとLLMに特化したスケジューリングを行う機能が実装されていることを解説しているが、より詳しく順序に従ってその処理内容を解説したのが次のスライドだ。

LLMInferenceServiceの処理を順に解説
チャートを使ってGateway APIからInference Scheduler、そしてLLMを実行するPodに処理が移っていくようすを解説した。
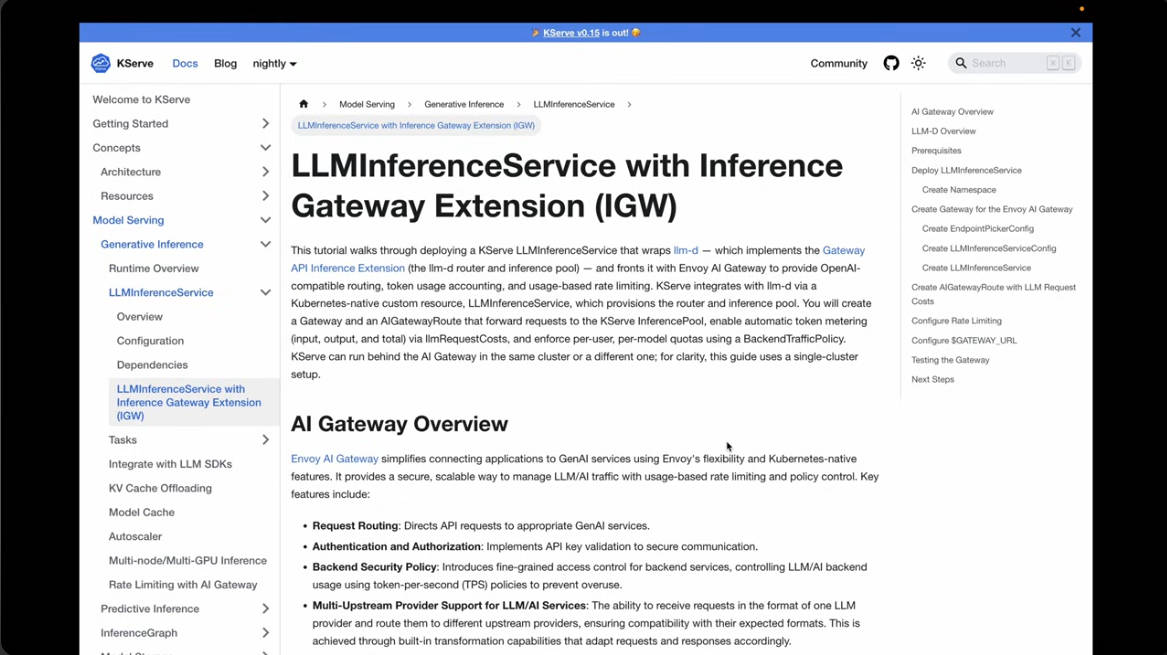
再度、KServeのドキュメントサイトから解説
ここでもう一度、KServeのドキュメントサイトを使ってルーティングの部分を解説し、その操作をデモとして見せた。
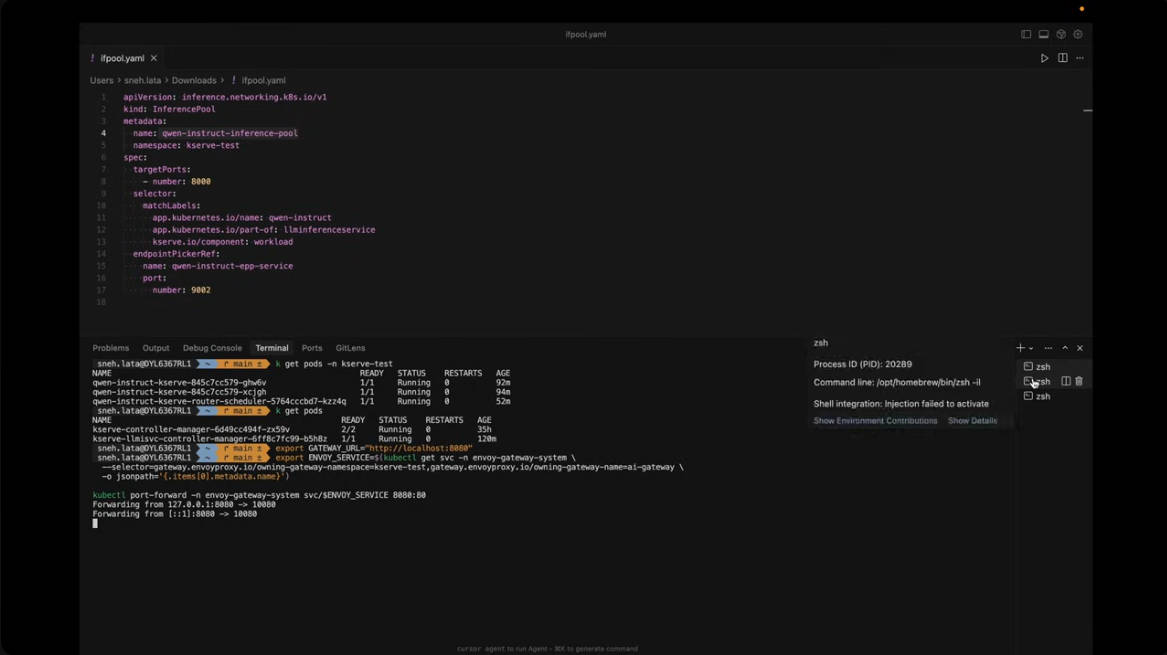
ルーティングが実施される部分をコマンドラインのデモで実施
ここまででKServeの解説を終えたNutanixのエンジニアだったが、LLMや生成AIに適したPodのスケジューリングという部分に特化して解説しており、従来のスケジューリングがLLMに向かない理由などについては特に深い解説を行っていなかったのが興味深い。CNCFは生成AIにおけるベストなプラットフォームとしてKubernetesを推しているが、その中核の機能であるLLM実行のPodスケジューリングについてより深く理解して欲しいという意図を感じた内容となった。
クラスター内部の複数GPUのスケジューリングについてはDynamic Resource Allocation(DRA)という機能がGPUにおいても利用可能となっているが、llm-d及びvLLMはその下のレイヤーで動的にLLMが実行されるPodをGPUに配置する機能となる。複数GPUのスケジューリングとGPU内部のパッキングを同時にコントロールするオープンソースソフトウェアとしてHuaweiが公開したHAMiが存在するが、llm-dはvLLMとはレイヤーが異なり競合することはないようだ。これからも多くのオープンソースプロジェクトがGPUのスケジューリング問題には参入してくると思われる。この分野はGPUの効率化に頭を悩ましているエンジニアにとっては注目すべき観測点となるだろう。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
