即活用!ツールを活用したデータモデリング 第4回
論理モデル上だけリレーションを引く
論理モデル上だけリレーションを引く
図2と図3は、前回使ったSQL ServerのNorthwindデータベースをER図にリバースした物理モデルと論理モデルです。
物理モデルには、実データベースの情報がそのまま表示されます。エンティティ間のリレーション(実線:依存型、破線:非依存型)が参照整合性制約に相当しますので、図2を見るとこのデータベースには参照整合性制約が張られていることがわかります。
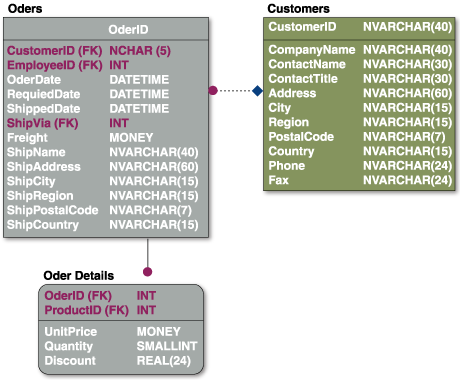
図2:Northwindデータベースの物理モデル
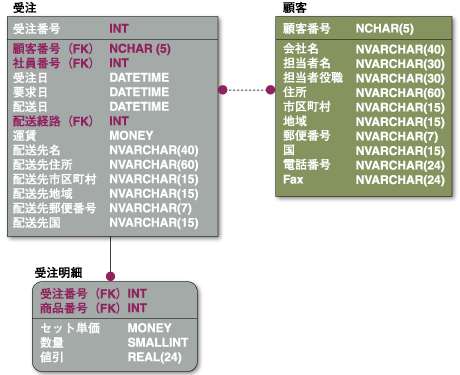
図3:Northwindデータベースの論理モデル
リレーションの線にも物理モデルと論理モデルがあります。そのため、参照整合性制約を使わない方針にした場合でも、わかりやすいER図を作成できます。物理モデル表示では箱(エンティティ)が並ぶだけの表示になりますが、論理モデル表示でエンティティ間のリレーションを設定できるのです。
Unicodeを使うか
図2や図3のエンティティの中(アトリビュート)を見ると、文字列のデータ型がvarcharではなくnvarcharが使われていることに気づきます。頭のnは、National LanguageのNのことで、各国語文字、すなわちUnicode形式で文字列を格納することを示しています。
皆さんはvarcharとnvarcharのどちらを使用していますか?
多分、ほとんどの人はvarchar、つまりS-JISなどの日本独自コードを使っていると思います。その理由を一言でいえば「Unicodeを使う理由がない」というものでしょうか。
確かにUnicodeは1文字に3バイト(UTF-8の場合)も使用しますし、Unicode非対応の外部システムとの連携にも困ります。英語と日本語以外の文字を格納しないのであれば、わざわざUnicodeを使う必要がないと考えるのも無理ありません。
筆者はといえば、実は比較的Unicodeを使っています。これまた絶対的な理由があるわけではありません。なぜかと聞かれれば、以下の3点を理由にあげます。
- サポートしている漢字種類が格段に多いこと
- 将来外国語を格納する可能性を残すこと
- 最近は世界的にUnicodeを使ったアプリケーションが増えてきたこと
表2:Unicodeを使用する理由
この時注意して欲しいのは、Oracleでは通常データベースのキャラクタセットでAL32UTF8などのUnicode指定を行います。つまりキャラクタセットでUnicodeを指定していれば、個々のデータ型でvarcharを選択していてもUnicodeとなります。
逆にいえば、データ型でnvarcharを明示的に指定するのは、キャラクタセットと異なっていてもUnicodeにする場合ということになります。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
