Kubernetesで機械学習を実現するKubeflowとは?
KubeCon+CloudNativeConにおいて、Kubernetes上で機械学習を実現するKubeflowが紹介された。
2018年6月1日 6:00
Kubernetesを中心としたクラウドネイティブなソフトウェアのカンファレンスであるKubeCon+CloudNativeCon、3日目のハイライトはなんと言ってもKubeflowだろう。朝9時から始まったキーノートの最初に登壇したGoogleのDavid Aronchick氏は、「KubeConには第1回から参加している」と語り、Kubernetesの盛り上がりに驚きを隠せないようだった。今回は、Kubernetesとともに今最も注目を集めている機械学習をクラウドネイティブにするという、Kubeflowを紹介するセッションとなった。
最初に紹介したのは、機械学習を使う効果だ。Googleのデータセンターの消費電力について、機械学習で制御を行った場合と、人手で制御を行った場合に大きな違いが出ていることを紹介した。
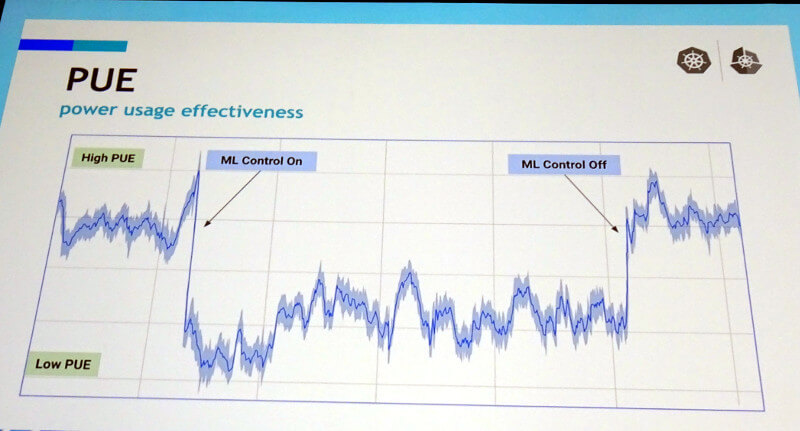
Googleの機械学習による省電力の効果
しかし多くの人にとって、機械学習を使って効果を出すのはまだ難しいと説明。その理由として、実際の機械学習の利用に至るまでに多くのハードルがあることを解説した。
理想と現実には大きな差がある
そして機械学習が実行される方式としてDIY(Do It Yourself)型とHosted型があり、それぞれに課題があると説明。DIYの場合は、多くの前処理の実装と既存のシステムとの連携が必要になること、Hostedの場合は最初の段階では問題がなくても、すぐにDIY同じ問題を抱えることになると語った。GoogleはGCPをパブリッククラウドとして展開しているが、ここではGCPによるソリューションに対しても客観的に評価したということだろう。

DIYとHostedの課題を比較
そこから機械学習に求められる特性として、Composability、Portability、Scalabilityの3つを挙げて、解説を始めた。

機械学習の3つのポイント
Composability(構成可能性)は機械学習においてモデル作成に注目が集まるが、それ以外にも多くのプロセスが必要であることを表す。特に後半の本番環境へのロールアウトについては、この後のPortabilityにもつながる話である。
Portabilityは文字通り、作成した機械学習のアプリケーションをいかにポータブルにできるか? という話で、ハードウェアからOS、フレームワーク、モデルなど多くのレイヤーにソフトウェアが必要になる場合、依存関係やOSなどの互換性を留意して開発を行わないと、実際に本番環境への展開時に問題を残すということだ。

機械学習に必要となる様々なレイヤー
これは実験的な実装からモデルの学習、本番の3つのステージに分けてシステム展開を考慮した場合、デスクトップからオンプレミス、さらにクラウドまで視野に入れたシステム運用を考え必要があるということを示唆している。

実験から本番までのステージに展開できるポータビリティが必要
最後のScalabilityは文字通り、GPUやTPUなどのハードウェア、増大するストレージへの要求などに応えられるプラットフォームが必要であるということだ。しかし単にコンピュータリソースだけではなく、人的資産も必要だと言う辺りは、データサイエンティストが不足しているという部分についても言及したという形だろう。
そして機械学習をKubernetesで実装する場合、多くの要因について知識と経験が必要となることを指摘する。これはJapan Container Daysでメルカリのデータサイエンティストが語ったことを裏付ける内容で、データサイエンティスト自身が全てのシステム要件を一人で実装できるというのは稀であるということだ。

機械学習をKubernetesで実装するのは大変
そこで、それを実現するのがKubeflowであると語った。

Kubeflow 0.1の紹介
ここでは「Kubeflowの中に何が含まれるか?」という情報のほうが重要だろう。Jupyter NotebookとTensorFlowのためのコンポーネントが含まれる。またパッケージングには、Ksonnetが使われていることも注目だろう。簡単なコマンドでKubernetesのManifestを生成できるパッケージングツールだ。

Kubeflowの中身
ここからは実際にデモを行った。いわゆるテストランのレビューを、TensorFlowを使って評価するというもので、特徴的なのはラップトップで作ったMinikubeの構成から、パラメータを変えるだけでGCP上のGKEにモデルを実装して推論を行うという部分だろう。この部分は、Ksonnetのパッケージの機能がうまく働いているようだ。
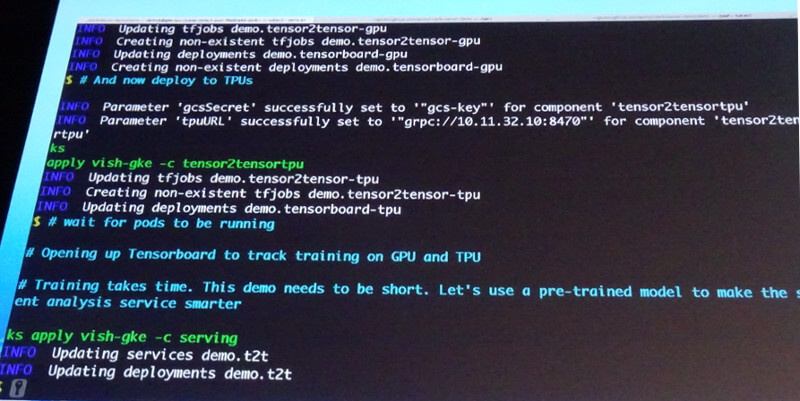
KsonnetのコマンドでモデルをGKEで実行
このセッションでは、ラップトップでの実行からGKE上のTPUを使った実行までライブデモを行い、いかにシンプルにKubeflowが実行できるのかを見せつけた形になった。

Kubeflowが「やらないこと」の紹介
ここでのポイントとしてKubeflowは「カスタマイズされた特別なツールではないこと」、「クラウドに限定されたものではないこと」、さらに「Kubernetes APIをカスタマイズしたものでもないこと」が強調された。つまり、デスクトップからオンプレミス、GCP以外のパブリッククラウドでも実行可能であること、Ksonnetによって様々なプラットフォームに対応できることを意味している。
まだバージョンも0.1ということで、あくまでも初期のプロトタイプ的な位置付けだろうが、このままコミュニティが成長して、AWSやAzureなどのプラットフォームへの対応、TensorFlow以外の機械学習フレームワークへの対応が進めば、一気にKubernetes上への機械学習の実装が進むのでは? と感じさせるプレゼンテーションであった。
David Aronchick氏のプレゼンテーション「Kubeflow ML on Kubernetes」
KubeConでは他にも、Heptioのエンジニアと組んでより詳細にデモを実施したセッションも行われた。Kubeflowをラップトップ、AWS、GKEのそれぞれのプラットフォームで動かし、Heptio ArkというこれもオープンソースのKubernetesクラスターをバックアップするツールを使って移動させるというデモも行われた。ここでも、マルチクラウドを意識した運用を想定していることが見てとれる。
「Conquering a Kubeflow Kubernetes Cluster with ksonnet, Ark, & Sonobuoy」
参考までに、HeptioはGoogleでKubernetesを開発していた二人のエンジニアが創業した企業で、Kubernetes関連のソフトウェアを多く開発している。
Heptioのオープンソースソフトウェア:https://heptio.com/products/
機械学習のワークロードは、バッチ式の実装や大量のデータストアの必要性から、どちらかといえばKubernetesには向かないのではと思われていた。しかしKubeflowにより、Googleの推進するオープンソースソフトウェアでこれが実装されたということに大きな意味があると言えるだろう。まだ「バージョン0.1」ということで、これからの進化が楽しみになったセッションであった。
- この記事のキーワード
この記事をシェアしてください
関連記事
Kubernetes上で機械学習のパイプラインを実装するKubeflowを紹介
2021年6月8日 7:12
KubeCon Europe 2024開催。前日に開催されたAIに特化したミニカンファレンスを紹介
2024年5月9日 6:00
KubeCon North America 2025、Kubernetesのコスト管理を行うZestyのR&Dチームのリーダ-にインタビュー
3月4日 6:00
KubeCon Seattleと併催のOpenShift Commons Gatheringレポート
2019年1月22日 6:00
KubeCon Europe 2025、エッジでAIを実行するKubeEdge Sednaのセッションを紹介
2025年5月29日 6:00
KubeCon+CloudNativeCon Europe 2026開催。併設のカンファレンスからAIに特化したセッションを紹介
6月5日 6:00
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
