今回は、21世紀型のシステム運用を行うことによって実現してきたシステム改善の具体的な事例を紹介する。
ここで紹介する事例は、「これまで紹介してきたノウハウやツールを活用した、日々のシステム運用のちょっとした改善」から、「システム運用の中で蓄えてきたデータを、次期システム全体のリニューアルに生かす例」に至るまで、大小いくつかだ。
読者のみなさんが運用されているシステムには、そのまま当てはまらないかもしれないが、一部分でも何か参考になるような点を見つけていただければ幸いである。
とあるシステムでのパフォーマンス改善(アプローチ事例)
DBミラーリングによる過負荷が発生
このシステムは、「Webサーバー」「アプリケーションサーバー」「DBサーバー」の三層構成である。サイト上でイベントを頻繁に行うため、アクセス集中対策として、余裕を持った作りになっている(図1)。
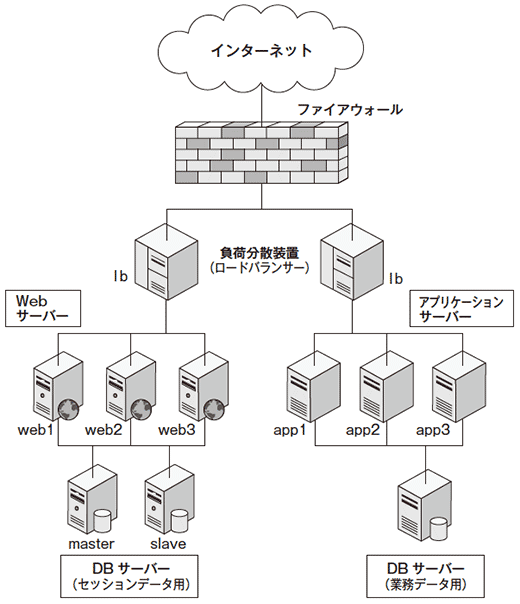
Webサーバーとアプリケーションサーバーをそれぞれの層で独立に負荷分散、データベースも業務データ用とセッション情報用を別々に用意している。
業務データ用DBはクラスタリング構成、セッションデータ情報用DBは2台のサーバーによるミラーリング構成であった。
冗長化は時にはシステムの障害となりうる
このように余裕がある作りにもかかわらず、新規にサービスを始めたところ、サービス遅延が起き、ちょっとしたピーク時に応答障害が起きるようになった。結論から言うと、セッションDBがボトルネックになり、応答が返せなくなっていたのである。
セッションDBサーバーとして投入されていた2台について調べてみると、マスターサーバーは十分と思われるスペックを持った最新サーバーであったが、スレーブサーバーはスペックの劣る1世代前の余剰サーバーを再利用していた。そして、パフォーマンスの異なる2台の間で、同期モードのミラーリングを行っていた。
同期モードのミラーリングの場合、マスター/スレーブとも書き込みが終わるまで、処理は完了しない。そのため、スレーブDBのパフォーマンス不足に引っ張られる形で、応答遅延が起きていた。
さらには、1時間ごとにトランザクションログの切り捨てや圧縮処理を行っていることもわかった。トランザクションログの切り捨てはともかく、圧縮処理はI/Oに大きな負荷を与える処理であり、1時間ごとに行うような処理でもない。そこで、当面の処置として、セッションDBのミラーリングをあきらめ、マスターサーバー単独での処理に切り替えた。それとともに、トランザクションログの切り捨てを1時間ごとに、トランザクションログの圧縮処理を1日1度のみとした。
このようにして、システムは安定稼働に入った。
当初、このシステム構築者は、データバックアップのつもりで、DBのミラーリングを考えていたのかもしれない。しかし冗長化は、行えばよいというものではなく、ときには障害の元凶になる可能性もあるので、十分な考慮が必要である。
システム責任者には、ミラーリング構成を望むのであれば、後日、新規サーバーをもう1台購入してからということで納得していただいた。
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
