リレーショナルデータベースの特徴
リレーショナルデータベースの特徴
リレーショナルデータベースは、複雑なデータを表のような細かなデータに分解し、それらを組み合わせて扱うようなデータベースです。表のことを「テーブル」と呼びます。個々のテーブルは比較的シンプルな構造になりますが、表どうしを柔軟に組み合わせる(結合する)ことで、複雑なデータ構造を表すことができます。
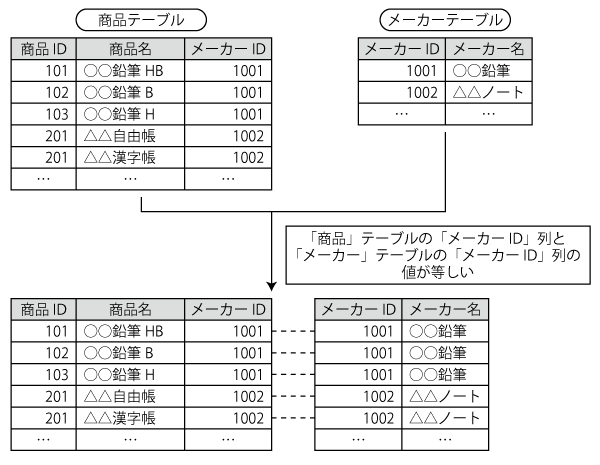
例えば、図2の上半分のように、「商品」と「メーカー」という2つのテーブルがあるとします。この場合、「『商品』の『メーカーID』列と、『メーカー』テーブルの『メーカーID』列の値が等しい」という条件で、これら2つのテーブルを結合することで、図の下半分のように、商品名とその商品のメーカーの情報から構成されるデータを得ることができます。
また、たいていのリレーショナルデータベースでは、「SQL」という言語でデータを扱うことができます。SQLでは、テーブルの一部の列を取り出したり、条件を指定して一部の行を取り出したりといったことを、比較的シンプルに書くことができます。
例えば、前述の図2のような操作をSQLで書くと、以下のように表すことができます。
SQLでは、データの読み込みだけでなく、追加/変更/削除や、データベースの各種の制御についても、命令が用意されています。
なお、SQLの書き方は、データベースソフトごとに細かな差はありますが、基本的な部分はおおむね統一的な書き方をするようになっています。
|
|
| 図2:「商品」と「メーカー」の2つのテーブルを結合する |
リレーショナルデータベースに求められる機能
リレーショナルデータベースは、ビジネスの分野で幅広く使われています。そのため、複雑な利用に耐えうるだけの機能が必要とされています。
まず、どんな処理を行ったとしても、データが矛盾しないような機能が必要です。例えば、1件の処理を行う際に、複数のデータベース操作が必要だとします。この場合、データベース操作がどれか1つでも失敗すれば、処理全体を失敗として、データベースを処理前の状態に戻すことができる必要があります。この機能のことを、「トランザクション」(Transaction)と呼びます。
また、大企業のデータベースなど、データの量が膨大になるケースもあります。このようなデータベースを1台のコンピュータですべて管理するのは、物理的に不可能になることもあります。そこで、1つのデータベースを複数のコンピュータに分散して管理するような機能も必要です。
さらに、故障等のトラブルがあったとしても、データベースが利用不能に陥らないようにすることも必要です。そこで、同じデータベースを複数のコンピュータで保持しておいて、あるコンピュータが故障しても、ほかのコンピュータで処理を続けられるような機能も必要です。この機能を「レプリケーション」(Replication)と呼びます。
企業の基幹業務に使われるようなデータベース製品だと、上記のような機能をすべて装備しています。ただ、低価格な製品や、オープンソースの製品だと、上記のような機能を完全には装備していない場合もあります。
- この記事のキーワード
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
