データ分析エンジニア対象「BIGDATAダッシュボード勉強会」レポート
8月22日(金)「BIGDATAダッシュボード勉強会」(主催/共催:サイオステクノロジー株式会社/Treasure Data Inc.)が日本創生ビレッジ東京21cクラブ(東京千代田区)を会場に開催された。データ分析エンジニアを対象として初開催「ビッグデータを活用するために、まずデータの可視化(ビ
2013年8月29日 21:00
8月22日(金)「BIGDATAダッシュボード勉強会」(主催/共催:サイオステクノロジー株式会社/Treasure Data Inc.)が日本創生ビレッジ東京21cクラブ(東京千代田区)を会場に開催された。
データ分析エンジニアを対象として初開催
「ビッグデータを活用するために、まずデータの可視化(ビジュアライゼーション)について考える」をテーマとして、4名のスピーカーから製品デモ等を中心に講演が行われた。主催者の配慮から、交通の利便性に優れる丸の内新丸ビル会場と金曜日の18時30分開演ということもあり、会場には仕事を終えて駆けつけたと思われる参加者の姿が多く見受けられた。
大企業で採用されるクラウド、ビッグデータ
アメリカで起業し同じく拠点を置くTreasure Data Inc.で製品マーケティング・製品開発の責任者を務める田村氏は本会のためにシリコンバレーより来日し、最初に登壇した。

現場で活きるビッグデータ
Treasure Data Inc.(以降、トレジャーデータ社)の提供する「Treasure Data Platform」はHadoop、自社技術、クラウド(AWS)を活用した情報処理基盤をユーザー企業に提供している。ビッグデータに対してHadoopは効率良いデータ収集及びデータ解析を助長して行くが、いざ現実的に自社での導入を検討した場合には導入までの時間とコストは膨大になるケースが多い。導入されている企業はfacebook、A9.com等、馴染み多い大企業が中心だ。そこでトレジャーデータ社では独自技術とクラウドを組み合わせることによって、導入決定からビジネスバリューまでを2〜3週間で達成し、オンプレミスに比べ圧倒的に時間圧縮を可能としている。このことからも、田村氏はクラウドのメリットを強調する。
また、「ビッグデータとはデータ量だけでなく、データの種類を豊富さに神髄がある」と語った。前時代のデータ分析は専門家が量・種類共に少ないデータを抜き出して独自の分析を社内(現場)に提出していたが、今日では量・種類の多いデータを企業内でそれぞれの立場の人材が自身のミッションと見地に即したデータを分析し、その結果を持ち寄ることによってより迅速で業務に密接した意思決定が実現できる。そのためにはダッシュボードによるPUSH型のデータ可視化が重要だ。
実例として掲げられた「ソーシャルゲーム会社」ではゲームタイトル毎にゲームプロデューサー、エンジニア、データアナリストが在籍し、数百タイトルのゲームが立ち上げられている。個別のデータはデータ分析基盤チームが統括して行っているので分析・KPI一元化が課題となっている。要望の内訳としては1:データ蓄積・分析の仕組みを統合してデータ分析をより楽にしたい。2:複数ゲーム間でのKPIを比較したい。3:新KPIの追加を柔軟に・計画的に行いたいとのこと。トレジャーデータ社のサービスとMetric Insightsを組み合わせることによって、横断的にKPIを横断的に管理するビッグデータダッシュボード実現する。
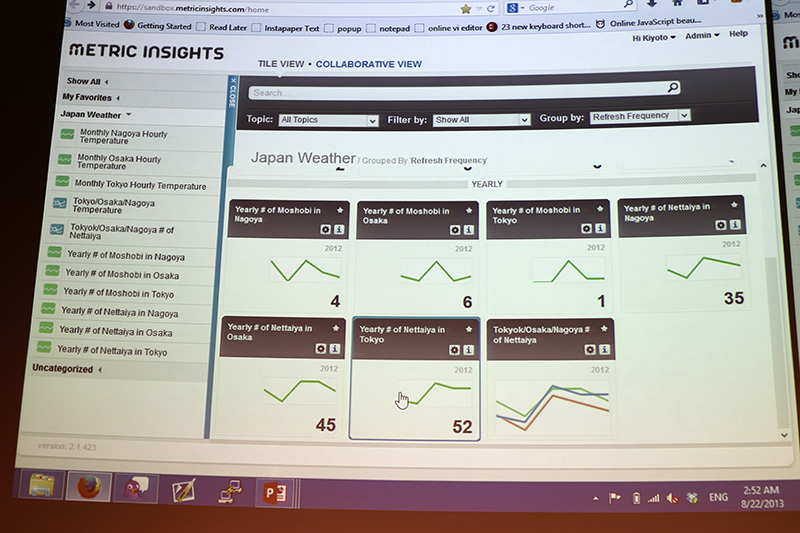
設定の事例としては気象庁の毎時気温データを用いた。地域毎に時間、週、月単位での比較もでき、必要なデータを1つのSQLを記述するだけで1つのメトリクスとして登録されるので、ダッシュボード上に自動更新される。また、Metric InsightsはGoogle BigQueryとも連携するので、様々なセンサーデータとの組み合わせて分析の多視点をもたらすことが可能でもある。
群雄割拠のBIツール
企業で用いられるBIツールについては、クライアント起業でのプロジェクトを間近で接する機会の多い田村氏の経験では「どのツールが特に多く使われていると言うことはなく、企業によって様々なツールを組み合わせて使われている。普及度で言えばExcelが最も多いBIツールと言える」と語り、現在トレジャーデータ社でもExcelをBIツールとして使える様に開発中とのことだった。
統計専門性を払拭するスモールデータ回帰分析
株式会社サイカは「最後に決定する直感値や経験値」モットーに支援を行うために2012年に2月に起業された。登壇した同社の取締役CTOである海老原氏は「データ分析等を専門家や外注した場合、分析者は現場で業務を行っているのではないので、意識の共有が難しい」と指摘し、かと言って現場で分析を行った場合は「データはあるがどの様に分析して良いか変わらない」といった、現状で多くの企業が抱える問題を指摘する。「ビッグデータと言うほど巨大ではないが、人力的では分析が困難である、企業内でストックされているデータ量の活用」を提唱し支援している。同社は「回帰分析」の手法を用いたWebサービスadelieを提供する。
adelieは統計の専門家ではなく現場での分析を重視し、コンサルタント・データエンジニアはより困難で挑戦的な領域への注力をする。

(重)回帰分析を可視化
デモでは「気象データとかき氷の売り上げ」を例として挙げられた。売り上げと各気象データとの相関関係率を示す。これは結果に対して、要因毎にどの程度の度合いをもって相関しているかを示唆することができる。「強くポジティブに相関する要因」「弱くネガティブに相関する要因」「そもそも相関があまりない要因」とadeliedeでの手法はOLS(最小二乗法)を用いている。ダッシュボード上で発見された"特異値"を発見することも容易としている。デモでは売り上げと気温の相関関係が崩れている日を調べ、要因が「台風のあった日」を例に特異値に当てはまる変数を簡単に当てはめることを行った。インラインでの修正も行うこともできるが、気に入ったモデルは分析モデルとして保存もできる。

サービス範囲をあえて回帰分析に限定することによって、統計や分析に不慣れな現場担当者レベルでの深い分析の支援を目指す。今後は現場での活用を深めてもらうために、分かりやすいチュートリアルやユーザー間での分析モデルの共有を実装してゆく予定とのこと。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
エンジニア初心者も知っておくべきUNIXの基礎知識
2023年10月26日 8:47
ゲームプログラマーを目指すにはどんな準備が必要? パソコンのスペックは? 学ぶべき言語は?
2024年1月17日 6:00
「リグレッションテスト」でソフトウェア開発を効率的するための必須ポイント
2023年7月11日 6:30
アジャイル開発とは?プロジェクト推進からチームビルディング、見積もりのコツまでを完全解説
2023年6月2日 9:27
データマイニング基礎講座 ービッグデータを業務に活かすためのポイントとは
2023年6月9日 6:00
140台以上の「さくらのVPS」を自在に操る! 仮想化の鉄人が語るVPS使いこなし術
2011年7月15日 20:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
