ウォームスタンバイ構成
ウォームスタンバイ構成
PostgreSQLのバージョン8.2からは、レプリケーション(非同期)を実行するよりも簡単な方法として、「ウォームスタンバイ」機能がサポートされました。実はバージョン8.0から可能だった機能ですが、同機能に対応したツール群が充実したことでバージョン8.2からより使い勝手がよくなりました。若干のツールやスクリプトと、マシン間でファイルを転送する手段があれば、あとはPostgeSQL本体の機能だけで実現できます。
ウォームスタンバイは、アーカイブ・ログを用いたリカバリ処理を応用したものです。アクティブ・マシンのPostgreSQLを、通常のPITR(ポイント・イン・タイム・リカバリ)と同様に、スレーブ・マシン上でリストアします。この際、読み込むWALファイルが尽きてもPostgreSQLを起動させずに、アクティブ・マシンから次のWALファイルが来るまで待機します。この挙動は、設定ファイルでスクリプトやツールを指定するだけで実現できます。
スレーブ・マシンでは逐次、アクティブ・マシン上でのデータ変更差分を適用しています。このため、通常のPITRのようなリカバリ時間がかかりません。リカバリを必要とせずに、直ちに起動させることができます。さらに、pgpool-IIやHAクラスタ・ソフトと組み合わせれば、自動でフェイル・オーバーすることも可能です。レプリケーションにかかる負荷がSlony-Iと比べて軽い点も魅力です。
ウォームスタンバイの欠点は、非同期であることや、スレーブ・マシンでSQLを受け付けられないことなどです。この点は、次バージョンのPostgreSQL 8.5に向けて改良案が提案され、実装されつつあります。
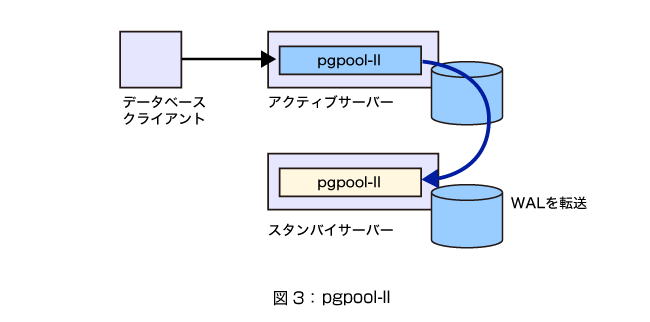
その他の方法、ソフト
PostgreSQLのレプリケーションを行うソフトは、このほかにも多数あります。現在も開発が続いているオープンソースだけでも、PGCluster(http://pgfoundry.org/projects/pgcluster)、SkyToolsのLondiste(http://pgfoundry.org/projects/skytools)、Bucardo(http://bucardo.org/wiki/Bucardo)などを挙げることができます。このほか、商用製品がいくつかあります。
信頼性を高める別の手段としては、より高レベルの要求に対しては、FT(Fault Tolerant=無停止型)サーバー上でデータベースを動かすことも考えられます。一方で、より低レベルの要求に対しては、単にPITRでバックアップを運用するやり方もよいでしょう。
いずれにせよ、まず初めに可用性(信頼性)の要求レベルがあって、さらには稼働するデータベースの特性があって、それに見合った高信頼化の方式を選択することが重要です。
■高速化のためのクラスタ構成
ここまでは、信頼性を高めることに着目してクラスタ構成について解説してきましたが、クラスタ構成は処理性能を高める目的にも利用できます。
例えば、pgpool-IIは、ロード・バランス(負荷分散)の機能を持っています。単純に言えば、SELECT文をバックエンド・サーバーの1つにだけ渡すことで、データベース参照時の負荷分散が実現できます。実行するSQLの比率が参照系が80%以上で更新系が20%以下のシステムであれば、バックエンド・サーバーの台数を増やすことで性能を高められます。pgpool-IIによるロード・バランスは、レプリケーション部分にSlony-Iを使った場合も有効です。
ただし、レプリケーションと負荷分散の組み合わせは、更新が多いシステムではレプリケーションにかかる負荷が大きくなってしまいます。このため、バックエンド・サーバーの台数を増やしても処理能力は増えません。また、多数の同時接続ではなく、1つの接続からの1つのSQLの実行時間が遅い場合は、サーバー台数を増やしても速くなりません。
1つの接続からの1つのSQLの実行時間が遅い場合には、データを複数のPostgreSQLサーバーに分散して格納する方法が有効です。シェアード・ナッシング(何も共有しない)構成などと呼ばれます。機能ごとに分散格納する方法と、データの値ごとに分散格納する方法があります。前者についてはアプリケーション側で対応する必要がありますが、後者については、アプリケーションで対応するほかに、ミドルウエアを使って実現する方法もあります。
データごとの分散格納と分散問い合わせを実現するミドルウエアには、GridSQL(http://sourceforge.net/projects/gridsql)があります。また、pgpool-IIには、分散問い合わせが可能なクラスタを構成する機能があります。これらは一般的に、BI(ビジネス・インテリジェンス)やOLAP(オンライン分析)のように、大量のデータに対して分析のためのSQLクエリを発行する用途に使われます。
一方、通常のWebアプリケーションにおいてデータベースの更新負荷が高い場合の対策としては、機能ごとにデータベース・サーバーを分割するやり方が一般的です。
以上で第4回は終わりです。クラスタリグによってPostgreSQLの可用性を高める方法について解説してきましたが、いかがだったでしょうか。いよいよ最終回となる次回では「Oracle Databaseとの違い」について、解説していきます。
--------------------------------------------------------------------------------------------------
※Think IT編集部注(2009.11.13):以下の部分を修正しました。
図3「PgAdmin III」→「pgpool-II」
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
