はじめに
「機械学習」とは、大量のデータを用いてあるデータの中にある様々な関係の符号化を行うモデルを作成する一連の技術を言います。
機械学習の応用の1つに「予測」があります。Stripeについて言えば、一定の入力値(例えば、カードの発行国や過去にあるカードがStripeネットワーク上で使用された国の数)が与えられた時、ある決済が不正(True)か正当(False)かを真偽値で予測したいわけです。
今回は、Radarがデータの入力および出力に基づく予測をどのように行っているのかを紹介します。
「クラス分類タスク」と「回帰タスク」
この予測問題は、「クラス分類タスク」と「回帰タスク」の2種類のタスクに分割できます。
- クラス分類タスク
サンプルがあるクラスに属するか、別のクラスに属するかを予測します(例えば、ある取引が不正な決済クラスか、正当な決済クラスかを予測したい場合)。 - 回帰タスク
入力と関連した数値的な出力を予測します(例えば、ドルを使っている新規顧客の生涯価値を予測したい場合)。
クラス分類タスクと回帰タスクは異なる技術に見えますが、基礎的な部分で関連しています。クラス分類は「あるサンプルがあるクラスに含まれる確率を予測する」という回帰タスクと見なせます。
モデルを訓練(または生成)するのに用いられるデータは、下図の例で示されるような取引記録と出力値、および入力値から成り立っています。
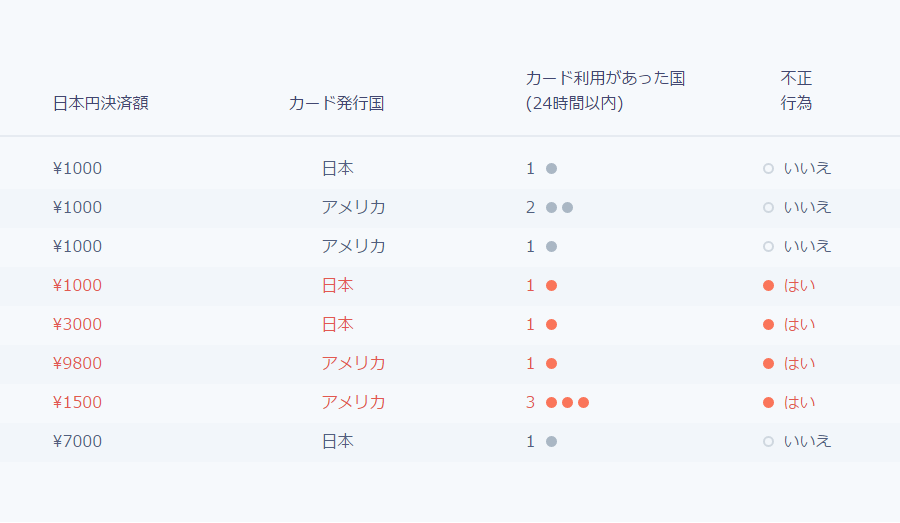
この例では3つしか入力値がありませんが、実際には機械学習モデルが数百から数千の入力値を持つこともよくあります。この機械学習アルゴリズムによる出力では、次のような決定木のモデルになるかもしれません。

新しい取引が行われる度にカードの発行された国や、過去にそのカードが利用された国の数、そして日本円の決済額に着目しつつ二十の質問型決定木を用いて、葉の1つに到着するまで辿るという方法です。それぞれの葉は、決定木を下まで辿る際に通った質問と回答のペアを満たすデータセット(上図参照)中のすべてのサンプルから成り立ちます。取引が不正である確率は、その葉の中のサンプルに含まれる不正取引をサンプル総数で割った数となります。別の言い方をすると、決定木は「この取引と類似した属性を持つデータセットに含まれる取引の内、実際に不正であった割合はどれくらいか」という質問に答えてくれるのです。機械学習の部分は決定木の構築と関連しています。
では、どのような質問をどのような順番で行えば、これら2つのクラスを見分ける確率を最大化できるでしょうか。決定木は容易に視覚化や推論を行えますが、学習アルゴリズムは他にも数多く存在し、それぞれの方法でデータの関係性を表現しています。
現在、機械学習モデルは社会に広く浸透しており、決定木のような簡単なモデルと比べて遙かに洗練されています。
- Google/Apple/Amazon/Microsoftでは、インテリジェンスアシスタントに機械学習を活用しています(それぞれGoogleアシスタント/Siri/Alexa/Cortanaと呼ばれています)。機械学習の活用には様々な形があり、音声の断片からテキストを予測したり、質問の意味や意図を抽出したりするのに用いられています。これらは文字や音声の膨大な数のサンプルからモデルを生成しています。
- Amazonではレコメンデーションシステムに機械学習を活用しています。特定の商品を買った人たちがその後何を購入しているかに基づいて商品をいくつか推薦することで、追加購入の確率を高めています。
- GoogleやFacebookでは検索やニュースフィードにおいて、機械学習でどのような広告を表示するかを決定しています。入力情報は広告の内容やその他の文脈情報(検索文字列や隣接するニュースフィードの内容など)が含まれ、モデルの出力として広告のクリック確率が得られます。Google、Facebookともにこのクリック確率を最大化したいと考えています。
そしてRadarのベースであり、どの決済が不正なのかを予測するのも機械学習です。
機械学習はどのような仕組みで動いているのか?
大学の機械学習コースではモデリングプロセスに焦点が置かれています。つまりデータ(例えば上図)をモデル(例えば決定木)に変換する方法です。このモデルは入力値(カード発行国やカード使用国など)を出力値(この取引が不正か正当か)に展開するものです。上図の入力データを使いつつ、ベストな決定木を作るプロセスが機械学習手法の一例です。
モデリングには多くのステップが含まれるためあまり詳細には触れませんが、大まかな概要を紹介します。
まずトレーニングデータを取得する必要があります。自動的に不正使用を検出する前に、不正使用の事例データを学習しておくためです。各事例から今後出力値を予測する際に必要となりそうな多岐に渡る入力属性を記録します。この入力属性は特徴、さらにサンプルとそれに関する入力値をまとめた集合データで特徴ベクトルと呼びます。前述の例で特徴ベクトルは3つの要素を持っていました(カード発行国、カードを過去に利用した国の数、日本円の決済額)が、数百ないし数千の要素を持つ特徴ベクトルも珍しくありません。実際、Radarも数百の特徴ベクトルを活用しており、その殆どはStripeネットワーク全体を通して算出した「行動的統計値」になります。出力値(実装例としては取引が不正かに関する真偽値)はターゲットやラベルと呼ばれることもあります。このように、トレーニングデータは大量の特徴ベクトルとそれに対応する出力値から成り立っています。優れた特徴を考えるのはデータサイエンスやエンジニアリング上の大きな問題で、後ほど詳しく解説します。
続いてモデルのトレーニングが必要です。トレーニングデータが与えられたので、次に予測モデルを作る方法が求められます。前述したように機械学習の予測タスクには回帰とクラス分類という2つの類型があります。回帰タスクは数の出力(例:不正使用損失額)の予測を、クラス分類は対象となるサンプルが属するクラスの予測を目指します(例:対象の決済が不正決済のクラスに属しているか)。機械学習における分類器(クラス分類問題向けのモデル)は単にクラスのラベルを出力するだけではありません。通常、対象のサンプルが想定されるそれぞれのクラスに属する確率の割り当ても行います。例えば、分類器の出力から対象決済が不正である確率65%、正当である確率35%といった判定になることもあるでしょう。
これら2つのタイプのタスクについて数多くの機械学習的な技術が存在します。回帰では線形回帰や回帰木といった従来型モデルも活用できます。クラス分類にも多数ありますが、ロジスティック回帰、決定木、ランダムフォレストなどが活用できます。
脳の神経細胞構造からアイディアを得たニューラルネットワークとディープラーニング(※英語)も両タスクへ応用可能です(AlphaGoが李世乭棋士を下すといった同分野における近年の驚くべき進展もよく知られているでしょう)。しかし、機械学習の産業的な応用のほとんどは従来型モデルでも十分に対応できます。Stripeでは繰り返しモデリングプロセスの実験や再実装を行っていますが、ランダムフォレスト(前述の決定木を汎用化したもの)も私たちの機械学習に関する問題に十分機能することが確認できています。
特徴エンジニアリング
機械学習コース(またはKaggleのようなサイト)によりデータから機械学習モデルを作成すれば、「これで大変な作業は終わった」と思ってしまうかもしれません。しかし、そうしたサービスでは「どこからデータを入手するか」「事業にモデルを運用するには何が必要か」といった内容は教えてくれません。モデルトレーニングの作業に入る前にあちこちの事業からデータを入手し、モデルのトレーニングに使える形で連携するデータインフラを構築しなければなりません。さらにモデルを作成した後にも「新しいモデルを事業の業務フローに統合する」というハードルが待ち受けています。
産業用機械学習において最も錯綜した領域の1つが特徴エンジニアリングで、2つの要素から成り立ちます。1つは予測値を決めるための特徴の定式化で、もう1つは特徴値をモデルトレーニングおよびモデル評価に利用可能にするための開発です。特徴の定式化には問題領域における広範な知識が必要です。
例えば、問題があるカード決済について、過去Stripeで頻繁に利用されていた2つのIPアドレスのうち、どちらから来たものかを判定できる値が有用な特徴になるのではないかと考えたとしましょう(2つというのは通常、カードの利用は自宅と仕事場の2通りが考えられるため)。この例ではアイディアは直感的なものですが、こうした思いつきは何千件もの不正使用の実例を精査してはじめて得られる場合が多いのです。
特徴に使えそうなアイディアが得られたら、その特徴を組み入れた新しいモデルをトレーニングできるように過去の値を算出しなければなりません。これはモデルの作成で使用する「表」に新しい列を追加するということです。そのためにはStripeにおける過去のあらゆる決済の中から、そのカードで最も頻繁に利用されている2つのIPアドレスを算出する必要があります。これはHadoopを使って分散して行うこともできますが、ジョブがあまりに多くの時間とメモリを要すると判明する場合もあります。そこで小さな確率的データ構造を用いて算出の最適化を試みることもあります。シンプルな特徴に見えても、モデルトレーニングのためのデータを作成するには相当な労力が必要になるかもしれないのです。
新しい特徴を取り込んだモデルが作れたら(新しいモデルがどれくらい効果的か判断する仕組みは次回で解説)、今度はそのモデルを本番環境に適用します。前述したような作業を通して過去の決済に関するすべての特徴値が作れましたが、Stripeへ決済を行うAPIが呼ばれる度にリアルタイムであらゆる新規決済の特徴値が算出できなければなりません。新しいモデルが適用された分類器で不正使用の可能性が高いと考える取引をすべてブロックできなければならないのです。この計算処理はトレーニングデータを作成したものとは全く別なものです。Stripeで確認されるすべてのカードに利用頻度の高い2つのIPアドレスを常に最新の状態に保つ必要があります。こうした処理もAPIフローの一環なので、件数の取得やデータ更新も迅速に行われなければなりません。
最後に、もしすべてのアイディアに前述のプロセスを適用しようとすると、目も当てられないほど非効率的な状況になるでしょう。宣言的に特徴を特定する方法があれば理想的です。また、サポートするインフラについてもレイテンシを十分に低く抑えた状態で、過去の特徴値は訓練用に、現在の特徴値は本番環境で自動的に利用できるようになっていることが望ましいです。これはStripeの機械学習チームのエンジニアが取り組んでいるインフラ問題の1つでもあります。
今回は、Radarにおける不正/正当取引を予測する機械学習モデルの仕組みについて解説しました。次回はさらに踏み込んだ機械学習の応用について解説します。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
