現在、データサイエンスにはPythonやRなどの言語が使われる。それに対してRubyでデータサイエンスをできるようにしようというワークショップ「DataScience.rb 〜ここまでできる Rubyでデータサイエンス〜」が5月19日に開催された。主催はSciRuby-jp、共催が株式会社Speee、しまねソフト研究開発センター、一般財団法人Rubyアソシエーション。
開催の趣旨としてSpeeeの村田賢太(mrkn)氏は、Rubyはデータサイエンスで使うには道具もユーザーも開発者も足りず、それがさらにネガティブフィードバックとなっていると指摘。そのためデータサイエンスでは使えない言語になっているという。
そこで、Rubyをデータサイエンスで使える言語にしたいというのが開催の意図だ。その方法として村田氏は「巨人の肩に乗る」「既存のgem(ライブラリ)をなんとかする」「Rubyのための仕組みを作っていく」の3つの手段を挙げた。
この3つのそれぞれに対応して、3つの発表がなされた。

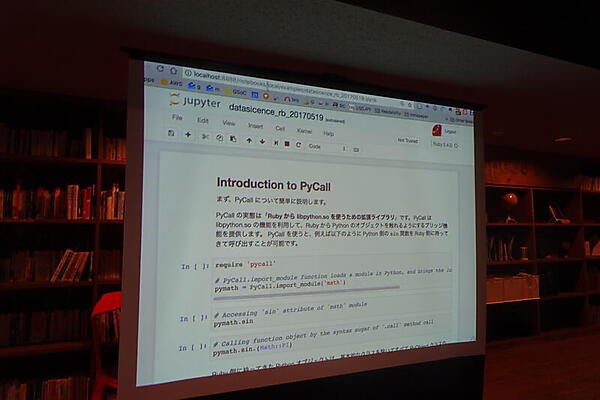
最初の発表は、村田賢太氏が開発しているPyCallの紹介だ。PyCallは、Rubyの中からPythonの処理系を呼出す機構で、PythonのクラスやオブジェクトをRubyのオブジェクトとして扱える。これを使って、Pythonのデータサイエンス関連のライブラリをRubyの中から実行するという、「巨人の肩に乗る」手法だ。
発表は、Webの中でPythonなどのコードを対話的に実行する「Jupyter Notebook」と、Jupyter NotebookでRubyコードを実行するエンジンIRubyを使ってデモしながら行なわれた。また、参加者用にもDockerイメージやサンプルが公開され、実習しながら話を聞けるようになっていた。
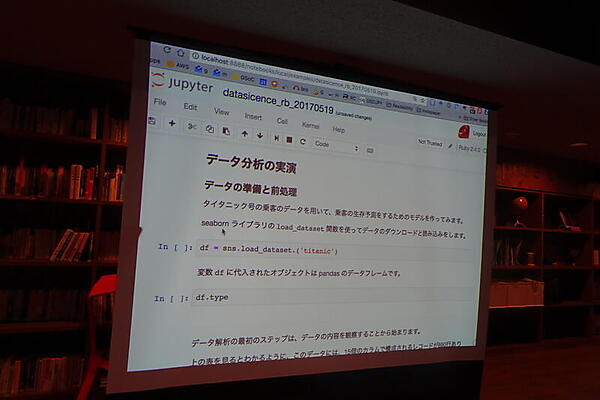
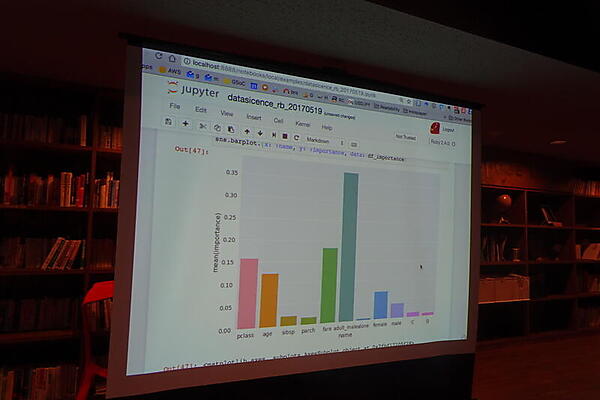
デモでは、データ分析でよく例に使われるタイタニック号の乗客データから、PythonのSeabornライブラリとPandasフレームワークを使って、生存予測をする例を見せた。データ中のsurviveの値をほかのカラムから予測するモデルを作る。読み込んだデータを下処理してから、ランダムフォレスト法でモデリングし、カラム間の相関を調べた。
村田氏は最後に感想として、PandasやSeabornなどのPythonライブラリが使えるのは非常に便利だとコメントした。ただし、現状はRubyとしてやや不自然な記法になることも指摘。さらに、PythonではなくRubyからPyCallを使って処理する意義が必要になると語った。
2つ目は、西田孝三氏と三軒家佑將氏による発表で、Pythonと同様のことをRubyで実現する方法を調査するものだ。冒頭の3つの手段のうち「既存のgemをなんとかする」に相当するもので、2016年にRubyアソシエーションの開発助成を得たプロジェクトだ。
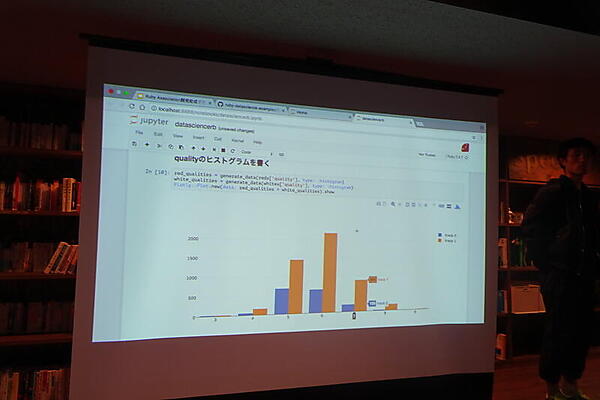
PythonのPandasのようなRubyライブラリにdaruがある。発表でも、Jupyter Notebook + daruを使って、赤ワインと白ワインのどちらが美味しいかを分析する例をデモした。
調査した結果として、Pandasに比べるとdaruは「かなり大変だった」という感想が語られた。まず、速度に顕著な差があるという。また、必要な機能がなく、たとえばデータサイエンスで大きな割合の時間を使う前処理の機能が足りないという。
その背景として、データサイエンスではPythonやRが使われRubyを使いたい人が少ないので、開発人材が不足することを指摘。打開するためには、Rubyの魅力を生かした用途が必要になるだろうとして、たとえばRailsやSinatraなどのWebアプリケーションと組み合わせるか、といったアイデアを挙げた。


3つ目は、須藤功平氏による、Apache Arrowの発表だ。Apache Arrowはデータ交換フォーマットの仕様とその実装だ。Apache Arrowを使うことで、たとえばPythonのプログラムでデータ処理した結果を効率よくRubyで利用できる。冒頭の3つの手段でいえば「Rubyのための仕組みを作っていく」にあたる。
Apache Arrowはビッグデータの交換を想定し、シリアライズやパースのコストゼロなのが特徴だ。各言語のバインディングがあり、特にPythonではPandasの開発者が積極的だという。そのため、Pandasで処理した結果をRubyで受け取って利用するといったことが容易になる。
須藤氏は、Pythonでファイルに出力したApache Arrow形式のデータをRubyやLuaなどで読むサンプルをデモ。また、Rなどで使われるFeatherフォーマットや、Hadoopなどで疲れるParquetフォーマットと組み合わせるなど、さまざまな言語やサンプルでデモした。さらに、受け取ったデータをRubyで処理する例として、全文検索エンジンのGroongaをデモした。
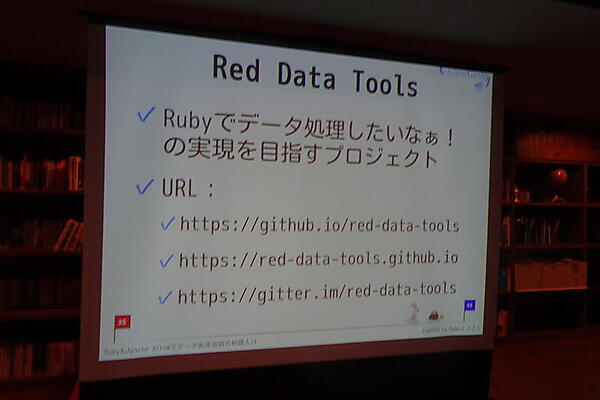
須藤氏は最後に「いちどArrowにすればいろいろなデータになる」として、Rubyでのデータ処理の実現を目指す「Red Data Toolsプロジェクト」を作ったことを紹介した。


(編注:2017年6月14日14時00分更新)誤字を修正しました、お詫びして訂正致します。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
使って分かった国産クラウド「K5」のメリットとは
2018年1月31日 6:30
初めてでも安心! OCIチュートリアルを活用して、MySQLのマネージド・データベース・サービスを体験してみよう
2021年4月21日 12:39
Dockerを理解するための8つの軸
2015年7月29日 22:00
Dockerの誤解と神話。識者が語るDockerの使いどころとは? Docker座談会(前編)
2016年2月22日 0:00
【イベントリポート:Red Hat Summit: Connect | Japan 2022】クラウドネイティブ開発の進展を追い風に存在感を増すRed Hatの「オープンハイブリッドクラウド」とは
2022年11月10日 8:45
Kubernetes、PaaS、Serverlessのどれを選ぶのか? 機能比較と使い分けのポイント
2018年5月23日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
