Intelが主導する新しいAIフレームワーク、BigDLとは?
Apache Spark上で動作するAIの深層学習向けライブラリーBigDLを、intelのエンジニアが解説。
2017年12月27日 11:00
オライリー主催のAI Conferenceシリーズの第4弾は、Intelが開発を主導するオープンソースソフトウェア、BigDLを取り上げたい。プレゼンテーションを行ったのは、IntelのビッグデータグループのJason Dai氏とDing Ding氏だ。

登壇するIntelのDai氏(右)とDing氏(左)
まず問題提起としてDai氏は、深層学習を実行するためのインフラストラクチャーを用意することが難しいことを挙げた。これはビッグデータであればHadoopやSparkなどが実際に稼働しているのに対し、深層学習の場合はCaffeやTorch、TensorFlowなどのフレームワークはすでに存在するものの、それを稼働させるインフラストラクチャーを構築する知見が少ないことを意味する。そこでIntelは、すでに実績のあるSparkの中に深層学習のフレームワークを構築して、実行させることを目指した。それがBigDLである。

BigDLの概要
Dai氏は「深層学習の専門家とビッグデータのエンジニアの間に大きな溝があり、それが深層学習の普及を阻んでいる」という認識から発想されたものがBigDLであると解説した。
Dai氏はBigDLの要件を「使い慣れたインフラストラクチャーを活用できること」「データが格納されているHadoop/Sparkのストレージを使えること」「Hadoop/Sparkのプログラミングと同じように実行できること」そして「すでに構築されたHadoop/Sparkクラスターを流用できること」であると説明した。つまりビッグデータの稼働環境にCaffeやTorchと同等機能を持つフレームワークを載せて、分散処理を行うのがBigDLということだ。
その後、ユースケースとして中国のUnionPayを紹介した。ここではビッグデータのプラットフォームであるSparkの上で、BigDLがSparkのジョブの一つとして実行できるという例だ。チャートの後半の記述によれば、BigDLによるニューラルネットワークによって不正使用かどうかを推測しているそうだ。
アーキテクチャーとして、Sparkのジョブを並列的に実行可能であることは、次のスライドでも説明がなされた。
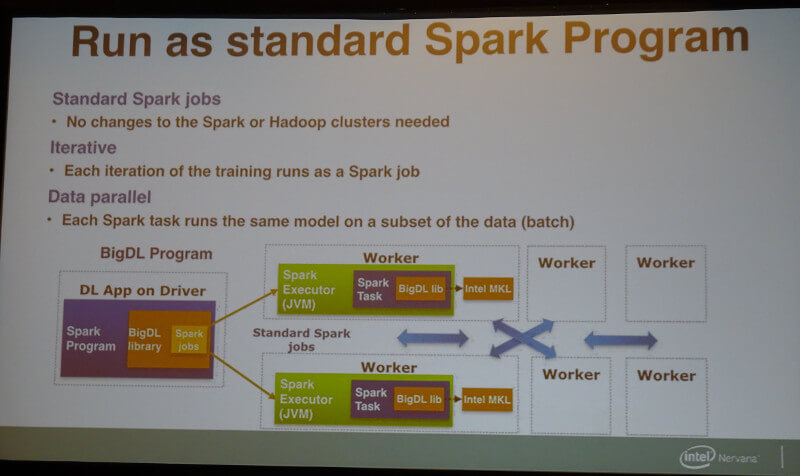
BigDL on Sparkの概要
またパラメータの分散と同期の処理にもBigDLが利用できるために、テストデータを複数に分割して処理を行った上で最終的に収束させることも可能であるという。
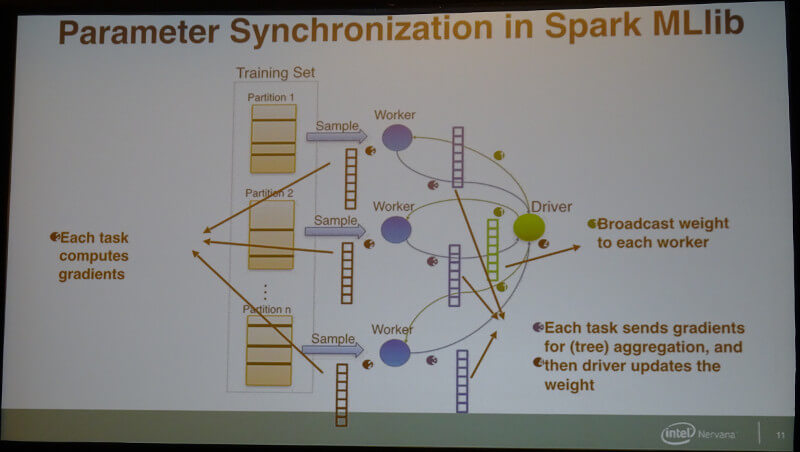
パラメータ同期の概要
そして並列で処理を実行する際にジョブのスケジューリングを行うためのエンジン、Drizzleに関しても概要が説明された。これもオープンソースソフトウェアとして公開されているもので、UC Berkeleyとのコラボレーションによって開発が進んでいるという。

Drizzleの概要
このスケジューリングエンジンを採用することで、並列実行時にSparkのオーバーヘッドを抑えることができたという。その検証の結果が次のスライドだ。
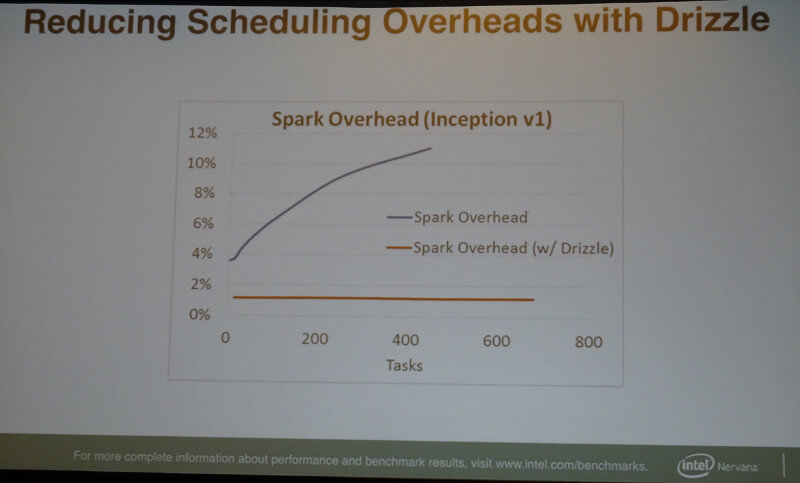
並列実行のオーバーヘッドが抑えられている
1日目のキーノートにおけるIntelのセッションでも、JD.comにおいてBigDLが使われていることが紹介されていた。そこで「BigDLは主に中国でのユースケースが多いのはなぜ?」という質問をセッションの後にDai氏に投げかけてみたが、意図的に選択しているわけではなく、北米でも利用が進んでいるという。ただ機械学習のエンジニアリングを行っているエンジニアに中国勢が多いのも事実であり、「AIで世界一を目指す」という中国の勢いがここでも確認できたということなのだろう。

キーノートで紹介されたJD.comでのBigDL
また深層学習といえばGPUをフルに活用する例が多いのは事実だが、Intelとしてはその部分にもチャレンジがあるという。それをBigDLに置き換えることで、大量の処理を実行する際にIntelのCPU(Xeon)を活用することができるというのも、いかにもIntelらしい方向性だろう。

GPUによる大量処理の問題点
ここでもGPUではなく、IntelのXeon上のSparkを使ってスケールアウトできることがアピールされていた。

BigDLをSpark上で稼働させる理由
まだ公開されて1年未満という新しいソフトウェアだが、Intelが本気を出して、AIコミュニティに対してXeonをプロモーションしていこうという強い思いを感じる熱いセッションであった。
より詳細な情報は、Intelのサイトにあるこのページを参考にされたい。
BigDL: Distributed Deep Learning on Apache Spark*
GitHubにおけるBigDLのリポジトリは、こちら。
この記事をシェアしてください
関連記事
感情を数値化するAffectivaとSparkで動くBigDL
2017年12月22日 12:00
KubeCon EU 2022からバッチシステムをKubernetesで実装するVolcanoを紹介
2022年9月15日 6:00
インテルがAIにフォーカスしたイベント「インテルAI Day」でPreferred Networksとの協業を発表
2017年4月25日 0:00
Microsoftのデータサイエンティストが解説するモバイル向けCNNとは?
2018年1月10日 6:00
KubeCon China 2025開催、中国ベンダーによるキーノートを紹介
2025年9月8日 6:01
イベント2日目:デモ連発で会場を沸かせたマーク・コリアー氏
2017年6月13日 0:00
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
