クラウドサービス運用で生じた失敗談
クラウドサービス運用で生じた失敗談
そしてここからが、本題である3つの失敗談を解説する段となった。
3つの失敗談をここから紹介
ゲストOSがブートしない
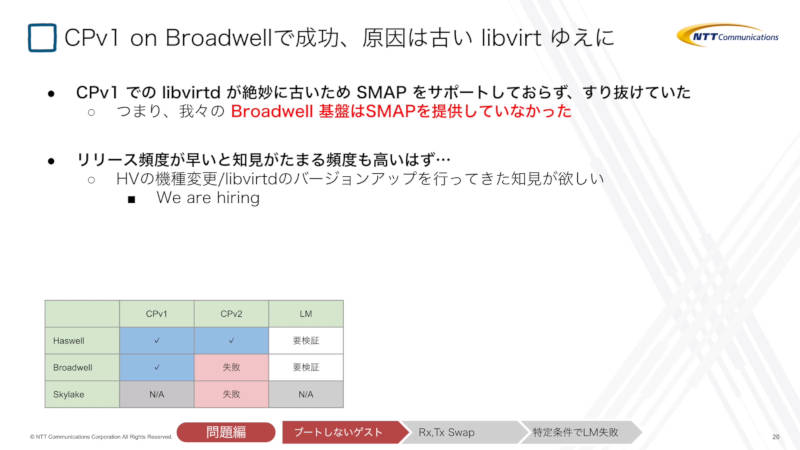
最初の失敗談は「ホストOSをアップデートしたらゲストOSがブートしない」というものだ。これはインテルのCPUに搭載されたSMAP(Supervisor mode access prevention)という新しい命令セットにゲストOSが対応していないからというのが原因だった。この新命令セットはBroadwellから導入されているのに、「Broadwell上のCPv1で同じ問題が発生しなかったのはどうしてだろう?」という疑問が生まれたことを紹介。

Broadwell/SkylakeでゲストOSがブートしない問題が発生
この挙動の理由は、CPv1で利用していたlibvirtdが古いバージョンであったためにSMAPをサポートしていなかったためだ。結果として、Broadwellのサーバーでは意図せずSMAPが機能していなかったわけだ。ハードウェア及びlibvirtdに関して知識が足らなかったことを説明し、そのような知見を持ったエンジニアがいればという心情を語った。
ハードウェア、libvirtdについての知識と経験が足らなかったことを吐露
対処方法として、CPv2にアップデートされたBroadwellサーバーでは互換性を保つという意味で、SMAPを無効にするオプションを利用してSMAPの機能を提供しないという結論になったことを解説した。CPUの新しい機能は提供したいという意図はあるものの、ここでは互換性を最優先したということになる。

Broadwell上のCPv2についての対処方法を説明
Rx/Txが入れ替わる現象
次に遭遇した問題は、仮想サーバーのネットワークにおける計測値(ここでは送信/受信パケット数だろうか)において、送信と受信が入れ替わっているように見えるという報告がモニタリングチームからなされたことがきっかけで顕在化した。
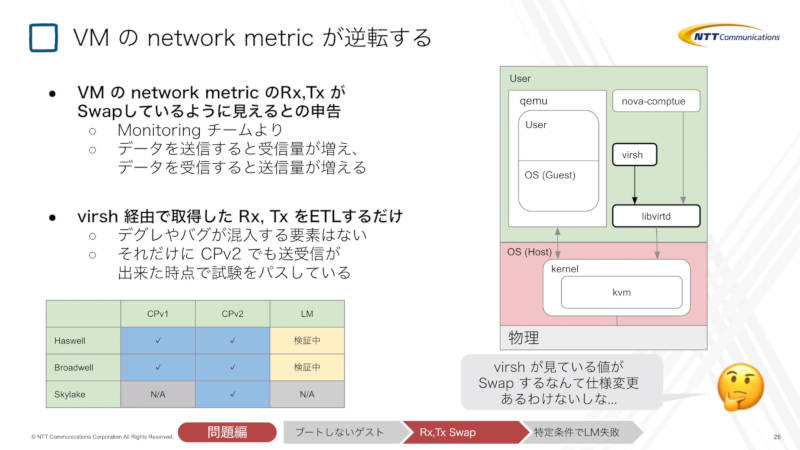
仮想マシンの送受信の値が入れ替わっている?
この現象はlibvirtdのバグが原因であり、これまでが間違っていてそれを正しく計測するように修正した結果であると解説した。
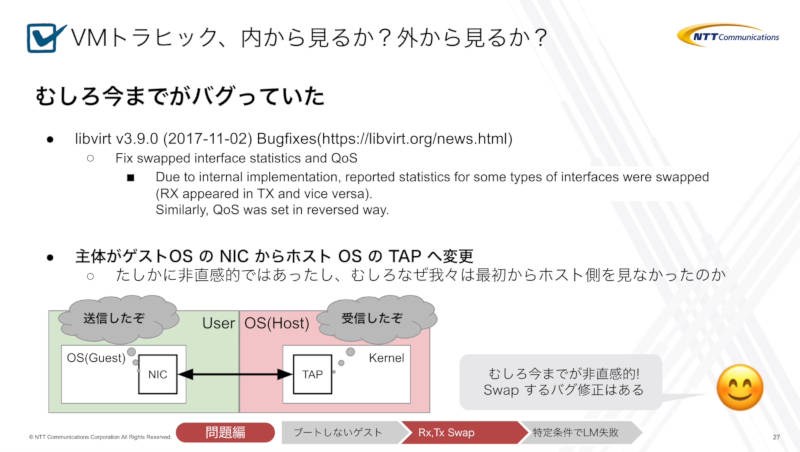
むしろ今までが間違っていたのを修正したのが原因
この経験からバージョンアップ、アップデートの頻度について、仮想マシンやハードウェアに近い部分のソフトウェアについては頻度を上げることも大事だが、「リリースノートをより深く理解するべき」という基本に忠実とも言える教訓を得たことを説明した。

ハードウェアに近いソフトウェアに付随する教訓
ライブマイグレーションの失敗
3つ目の失敗談は、OSのライブマイグレーションが失敗するという現象であり、かなりレアな条件の組み合わせで発生することを解説した。
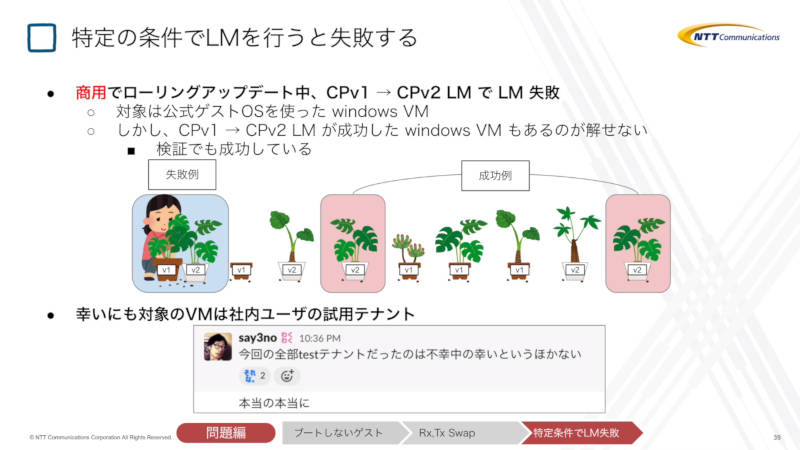
ライブマイグレーションがWindowsの仮想サーバーだけで失敗する例
これはCPv1からCPv2にアップデートを行った後に、Windowsの仮想サーバーをライブマイグレーションしようとすると失敗するという例だ。この例が幸運だったのは、発生したのが顧客向けのゲストOSではなく、社内ユーザーのテスト用環境でのみ発生するという点であり、実際に流れたSlackの社内用メッセージが挙げられていた。
これが発生する条件がレアなことを解説
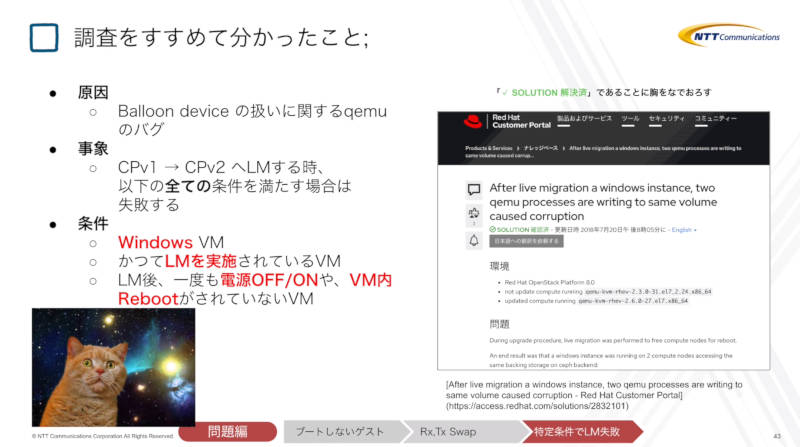
このライブマイグレーションの失敗は、Windowsの仮想マシンで過去にライブマイグレーションを行っていること、そしてライブマイグレーション後一度もリブートや電源オフがなされていないという条件でのみ発生する不具合であることが、レッドハットのナレッジベースで公開されていることが紹介された。Red Hat OpenStack 8が利用するqemuにおいて、すでに解決済みであることが救いだったという。
これに関しての対応としては、顧客に仮想マシンをリブートしてもらう、ライブマイグレーション前に対処を行うなど複数の対処方法が考えられるが、その中で一番顧客に影響が少ない方法を採用したと説明した。

対処方法は複数あるが一番顧客に影響が少ない4つ目の方法を採用
トラブルへの心構え
ここからは、このような「レアな条件でのみ発生する不具合を事前に予防するためには何をすれば良いのか?」という運用サイドとしては究極の課題について解説を行った。
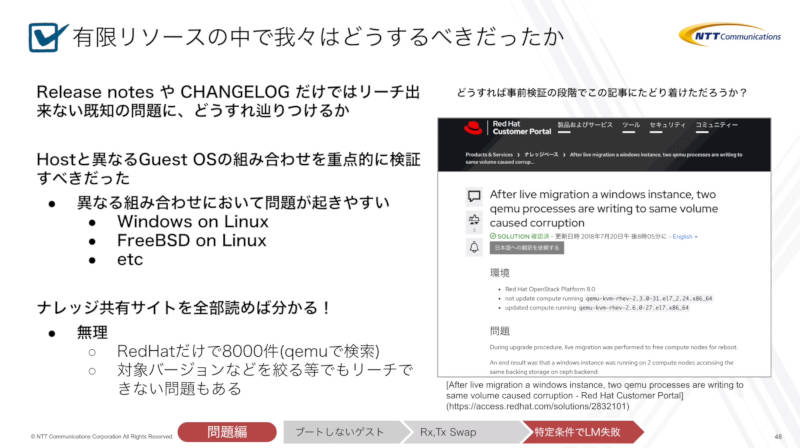
限られた時間、スタッフでどうやって不具合を未然に防ぐか? という課題
最後にまとめとして、SPDFとしての仮想サーバーのアップデートは完了したこと、検証しても問題が起こることを受け入れるカナリアデプロイメントの採用、インフラストラクチャーのコード化とテストの自動化などが必要としてセッションを終えた。
メガクラウドと比較して小規模ではあるものの、利用するコンポーネントのバグフィックスや制限事項に起因する不具合や、ホストOSとゲストOSの組み合わせで起こる不具合と対応を赤裸々に開示したセッションとなった。本来ならこのセッションこそが「運用苦労話」カテゴリーに入れられるべき内容だろう。大手にも関わらず、このような失敗談を共有したことは評価されるべきだし、他の通信事業者もぜひ見習って欲しい。
- この記事のキーワード
この記事をシェアしてください
関連記事
レッドハットが「OpenShift Commons Gathering Japan 2021」を開催、キーパーソンが語るハイブリッドクラウドを実現するための3つのポイントとは
2022年1月13日 6:30
CNDT 2022、Raspberry PIを使ったマイクロクラスターにKubernetesを入れ可視化した実験を解説
2023年6月7日 6:00
コンテナー管理ツール「Rancher」のエンタープライズ利用に向けたイベント開催
2017年10月30日 13:30
OpenStackのセミナーでコントリビューターたちが語ったOpenStackの未来
2017年12月13日 6:00
CNDT2021、三菱UFJのIT子会社が語る伝統的な銀行システムとコンテナを繋ぐシステム
2021年12月16日 6:00
Red Hat Summit 2024から、20万台のCentOS 7をRHEL 9に移行したSalesforceのセッションを紹介
2024年7月17日 6:00
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
