「KEDA」でPodのイベント駆動スケーリングを実現する
第17回の今回は、「KEDA」によるイベント駆動のオートスケーリングと、Prometheusをトリガーとした基本的なスケーリングの実装方法について解説します。
1月16日 6:30
はじめに
3-shakeのSreake事業部に所属する小池(@r4ynode)です。
Kubernetesを運用していると「夜間や休日はほとんど負荷がないのにリソースを消費している」「メッセージキューの処理でイベント発生時だけPodを増やしたい」といった課題に直面することはないでしょうか。
今回は、イベント駆動でPodをスケーリングできるOSS「KEDA(Kubernetes Event-driven Autoscaling)」を紹介します。Prometheusメトリクスを使った基本的なスケーリングの実装を通してKEDAについて理解していきます。
HPAの課題
Kubernetesには標準でHPA(Horizontal Pod Autoscaler)が用意されており、KEDAを使わなくてもCPUやメモリ使用率に基づいてPod数を自動調整できます。しかし、実際の運用では以下のような課題があります。
- リソースメトリクスだけでは不十分:メッセージキューの滞留数やデータベースのクエリ残数など、CPU・メモリと直接相関しない指標でスケールしたい場合に対応しづらい。
- アイドル時のリソース浪費:HPAは最小レプリカ数を1以上に設定する必要があり、処理すべきイベントがゼロでもPodが稼働し続ける。
こうした悩みを解決してくれるのがKEDAです。
KEDAとは
KEDAは外部イベントソースの状態に基づいてPodを自動スケーリングできるツールです。2020年にCNCFのSandboxプロジェクトとして受け入れられ、2023年にはGraduatedプロジェクトとなっています。
KEDAができること
KEDAの主な特徴は以下の通りです。
- 多様なイベントソースに対応:70以上のビルトインスケーラーで、メッセージキュー、データベース、クラウドサービス、Prometheusメトリクスなど多様なイベントソースに対応。
- Scale to Zero:イベントがない時はPod数を0にまでスケールインできる。
実はHPAでもカスタムメトリクスや外部メトリクスを使うことは可能ですが、別途Metrics Adapterなどを用意してKubernetesが理解できる形式でメトリクスを提供する必要があります。また、外部メトリクスのAPIServiceリソースは1つしか持てないため、複数の異なるメトリクスプロバイダに対応することが難しいという課題もあります。一方、KEDAはビルトインスケーラーが多く用意されており、単一のKEDAインストールで複数の異なるイベントソースを扱えます。
アーキテクチャ
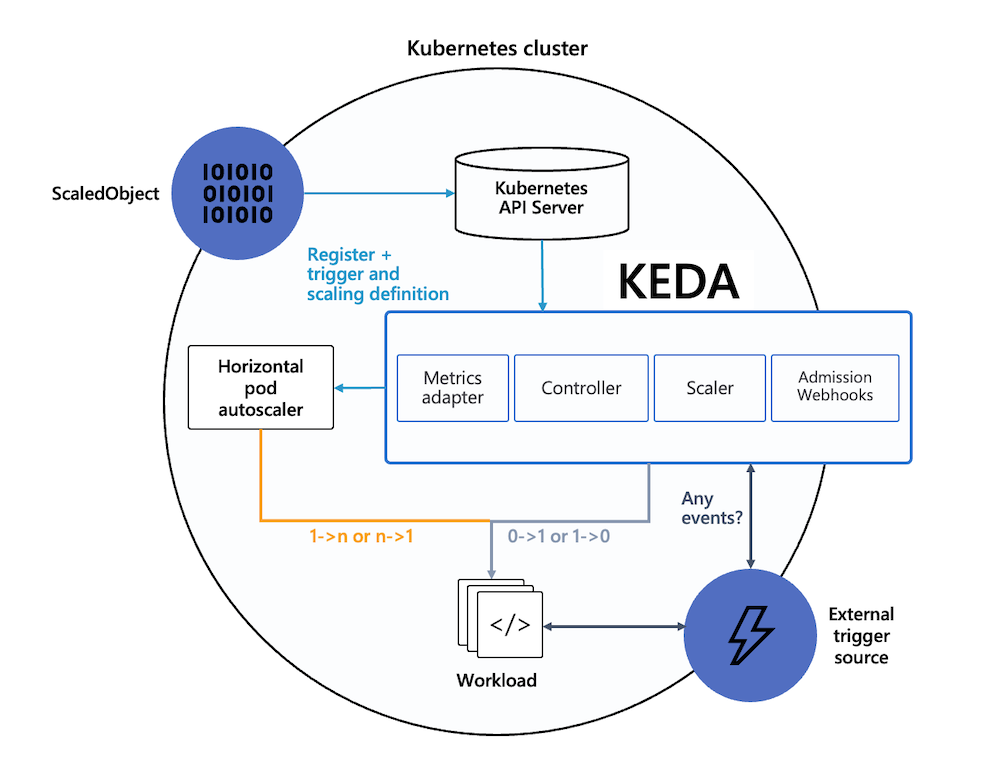
KEDAは以下の主要コンポーネントで構成されています。
- KEDA Operator:イベントソースを追跡し、需要に応じてスケーリングを実行する。
- Metrics Server:外部イベントソースからメトリクスを取得し、KubernetesのHPAに提供する。
- Scalers:各種イベントソースからメトリクスを収集する。
KEDAは内部的にHPAを管理することで、Kubernetesの標準的なスケーリング機構を活用しながら、イベント駆動のスケーリングを実現しています。
KEDAのCRD
KEDAでは、以下のCRDを使ってスケーリング設定を定義します。
- ScaledObject:DeploymentやStatefulSetを対象としたスケーリング設定。
- ScaledJob:Kubernetes Jobを対象としたスケーリング設定。
- TriggerAuthentication:イベントソースへの認証情報を管理。
External Scalers
KEDAは70以上のビルトインスケーラーを提供していますが、独自のイベントソースや特殊なメトリクスに対応したい場合があります。そのようなケースではExternal Scalerを使うことで、カスタムロジックを実装してKEDAと連携できます。
KEDAが「Scale to Zero」を実現できる理由
リソースを0までスケールインすることを「Scale to Zero」と呼んだりします。HPAでは実現できないScale to ZeroをKEDAではなぜ実現できるのでしょうか。
HPAは基本的にCPUやメモリの使用率をベースにスケーリングを設定するため、Podが起動していないとそれらのメトリクスは当然に取得できず、必然的にスケーリングできないわけです。一方、KEDAのスケーラーはPrometheusやCloudWatch、Queueなどの外部システムのメトリクスに依存するため、Podが起動していなくてもスケーリングを判断できるわけです。これが、KEDAがScale to Zeroを実現できる理由です。
この説明から見えてくるのは、KEDAを使ったとしてもPodのCPUやメモリをベースにした場合、HPA同様にScale to Zeroは実現できないということです。そのため、厳密にはHPAにできないことはKEDAにもできないわけです。
HPAでもScale to Zeroはできなくはない
「HPAはScale to Zeroを実現できない」と説明しましたが、フィーチャーゲートのAlpha機能としてHPAScaleToZero機能は存在します。この機能は、カスタムメトリクスまたは外部メトリクスを使用するときに、minReplicasを0に設定できるようになります。
【参考】https://kubernetes.io/ja/docs/reference/command-line-tools-reference/feature-gates/
Prometheusスケーラーで学ぶKEDA
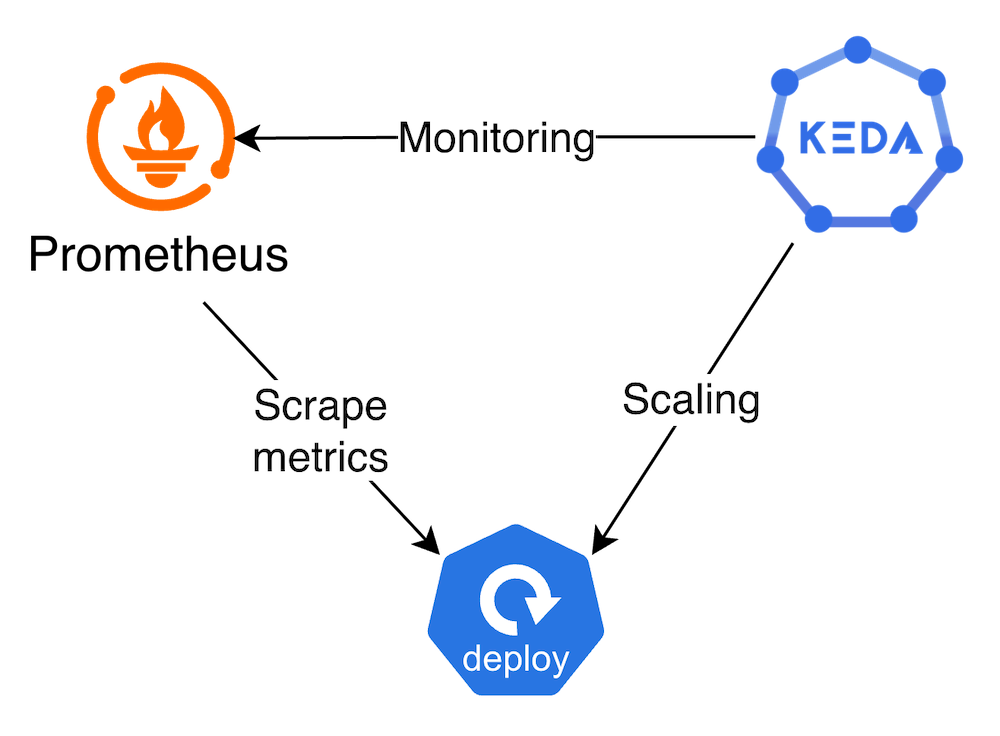
KEDAの使い方を理解するために、Prometheusのメトリクスを使った簡単なスケーリングを実装します。これから構築する内容は下図のとおりです。実運用においては、アプリケーションのメトリクスに依存する形だとScale to Zeroの実現は難しいかもしれません。
検証環境
Kubernetesクラスター上には、既に以下の3つのアプリケーションがデプロイされていることを前提に検証していきます。
- KEDA
- Prometheus
- /metricsエンドポイントを公開しているアプリケーション
スケーリング対象のアプリケーションの準備
スケーリング対象として「Hello World」と返すだけのシンプルなGoアプリケーションを実装しました。このアプリケーションは/metricsエンドポイントでサイトへのアクセス数を表すhttp_requests_totalメトリクスを公開しています(アプリケーションの実装は割愛します)。このエンドポイントをPrometheusでスクレイピングし、メトリクスを取得します。Goのアプリケーション側ではhttp_requests_totalを加算しているだけなので、アクセスするたびにこの値は増えていきます。
ScaledObjectの作成
KEDAのCRDリソースの1つであるScaledObjectを作成します。このリソースでトリガーとするメトリクスとその条件を設定します。今回は用意したhttp_requests_totalメトリクスを監視して、閾値を超えたらスケールする設定を行います。以下の例では、http_requests_totalが50を超えたらスケールアウトします。
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: simple-go-app-scaledobject
spec:
scaleTargetRef: # スケール対象を指定
apiVersion: apps/v1
kind: Deployment
name: simple-go-app
minReplicaCount: 1
maxReplicaCount: 2
triggers: # スケールを判断するトリガーを定義
- type: prometheus
metadata:
serverAddress: http://prometheus-stack-kube-prom-prometheus.default.svc.cluster.local:9090
threshold: '50'
query: http_requests_totalscaleTargetRefには、スケール対象となるDeploymentやStatefulSetを指定します。/scaleサブリソースを持つカスタムリソース(CRD)であれば、それも指定可能です。triggersでは、どの条件でスケールさせるかを定義します。triggersは配列になっており、複数のスケール条件を設定できます。
注意点として、1つのリソースに対して複数のScaledObjectを定義すると競合が発生し、正しく動作しない可能性があります。そのため、複数の条件でスケールさせたい場合は、1つのScaledObjectの中のtriggersにまとめて記述するのが良いでしょう。
今回の例ではPrometheusをトリガーとして使います。queryはPrometheusに投げるクエリで、PromQLで記述します。このクエリはPrometheusから返される値として、必ず1つのスカラー値または要素数1のベクトル値を返す必要があります。これは、KEDAが評価時に1つの値として扱う必要があるからです。そのため、通常はsum()やavg()などで集約し、1つの値にまとめます。今回の例では、http_requests_totalメトリクスは対象アプリケーションのみを計測しているため、1要素のベクトル値を取得できています。
Prometheusスケーラーを実際に導入する場合は、どのメトリクスを基準にスケールさせるかを要件に応じて細かく決める必要があるでしょう。以下のクエリは、特定のDeploymentに対して過去2分間のHTTPリクエスト数のレートを取得する例です。
sum(rate(http_requests_total{deployment="my-deployment"}[2m]))今回はスケールすることを簡単に確認したいので、単純にhttp_requests_totalだけを基準とします。
負荷生成とスケーリング動作の確認
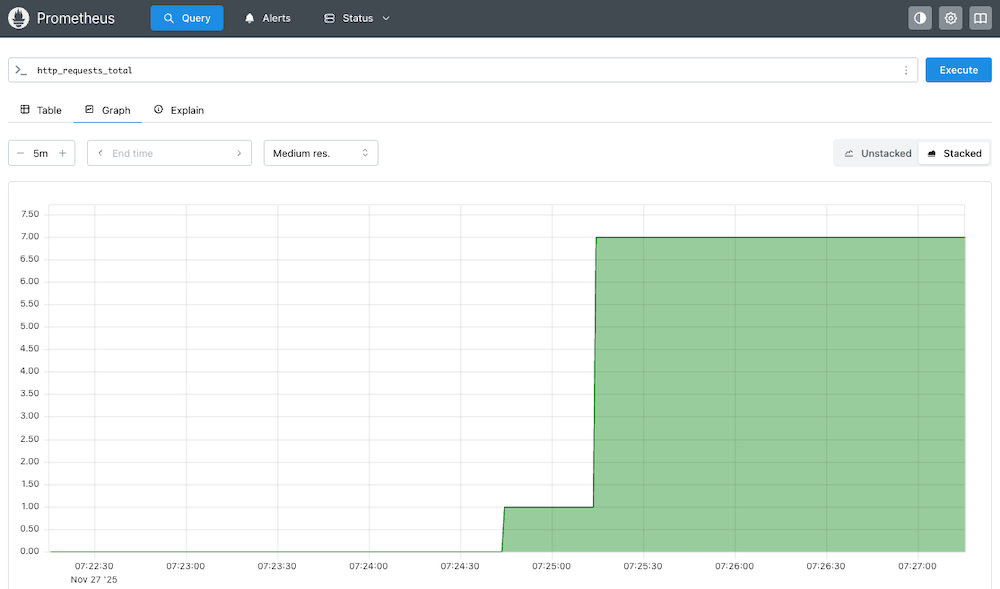
実際にアプリケーションにcurlなどでリクエストを送り、Prometheusのhttp_requests_totalの値を閾値以上に上昇させます。
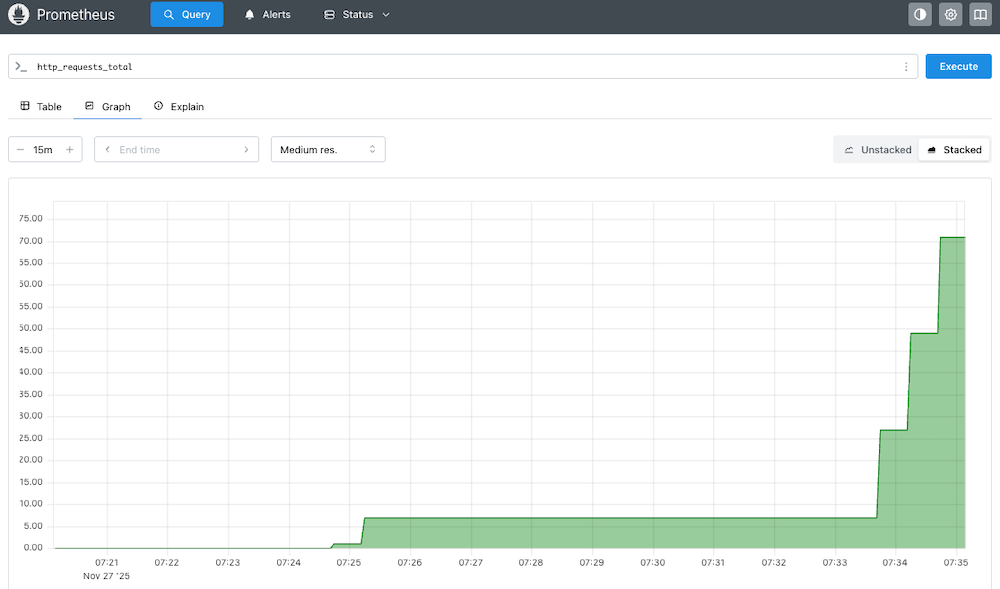
http_requests_totalの値に応じてPod数が変化するかを監視します。
$ kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
simple-go-app 1/1 1 1 29s
# pod数が1つ増加している
$ kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
simple-go-app 2/2 2 2 2m11s無事にPodをスケーリングさせることができました。
まとめ
本記事では、KEDAを使ったイベント駆動のオートスケーリングについて解説しました。また、Prometheusをトリガーとした簡単なスケーリングを実装し、KEDAの基本的な使い方を確認しました。
KEDAを活用することで、従来のHPAでは対応が難しかった多様なイベントソースに基づくスケーリングや、Scale to Zeroによるリソース効率化が実現できます。本記事で紹介したPrometheusスケーラー以外にも様々なビルトインスケーラーが用意されているため、実際の運用要件に合わせて最適なスケーリング戦略を構築してみましょう。
【参考】この記事をシェアしてください
バックナンバー
この記事の筆者

Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
