AI_dev Europe 2024から、IBMとRed Hatが一緒にプレゼンテーションを行ったInstructLabを解説するセッションを紹介する。このカンファレンスでは生成型AIのモデルがどれくらいオープンなのかを評価するModel Openness Framework(MOF)の発表が初日のキーノートで行われ、他にもオープンソースなAIモデルとクローズドなモデルを解説するセッションなども行われているように、The Linux FoundationとしてはオープンソースによるAI開発が業界にとっても社会にとっても最良の選択だと訴求したいという意図を感じる内容となっている。
何よりもオープンソースで最もビジネスとして成功しているRed Hatが、IBMの協力を得て土台となる基礎のモデルであるGraniteを公開したことで、Red HatそしてIBMはオープンソースによる生成型AI開発をリードしたい、賛同者を増やしたいことは明確だろう。
このセッションは2024年5月にデンバーで開催されたRed Hat Summitでのセッションをおさらいするような内容となっているが、その後のフィードバックを得て、より具体的な解説となっていることに注目したい。Red Hat Summitに関しては以下の記事一覧を参照して欲しい。このカンファレンスでRed Hatは、IBMの持つリソースをフル活用してオープンソースによる生成型AIの未来に賭けている姿勢が見て取れる。
●参考:Red Hat Summit 2024レポート 記事一覧
今回のセッションはIBMのMark Sturdevant氏とRed HatのCarol Chen氏によって行われたが、特に分担を分けずに交互にInstructLabを解説しているのが興味深いところだろう。実際の開発でも、IBMとRed Hatが役割を分担せずに共同作業を行っている印象を受ける。ちなみにSturdevant氏はIBM Researchでオープンソースに関わって約10年の経験を持つベテランで、InstructLabではCLIのメンテナーでもあると紹介された。一方のChen氏は、かつてはエキスパートシステムに関わっていたことはあるが、生成型AIについては経験が浅く、このカンファレンスの2か月前にInstructLabの仕事に異動してきたと説明し、学ぶことが一杯あると話していた。

セッションを行うChen氏(左)とSturdevant氏(右)
セッションのタイトルは「Applying Open Source Methods to Building and Training Large Language Models」、オープンソースによるソフトウェア開発の仕組みを大規模言語モデルに適用するInstructLabの背景と効果を解説する内容となっている。
●動画:Applying Open Source Methods to Building and Training Large Language Models
まずはLLMが発表されてから無数のクローン化されたモデルが市場に溢れていることを説明。ここではStar Warsのエピソード2のタイトル、「Attack of the Clones」をもじって「Attack of LLM Clones」という状態にあるとジョークを交えて解説を行った。
つまり各ベンダーや研究組織がゼロからベースとなるLLMの基礎モデルを作るのではなく、Llamaなどのモデルをベースにしてその上からデータを追加することで特定分野の知識を構成する方法論が現在の状態であることを説明した。

Foundation Model-Centric Applicationsというスライドでモデルの作られ方を説明
このスライドでは公開されたモデルに業界や企業に特化したデータを追加することで必要に応じたモデルを生成することが一般的であると説明している。ただしその結果として、オープンソースコミュニティで実現しているコミュニティがモデルの改善に協力するということができなくなっていることを説明したのが次のスライドだ。

成功しているOSSの特徴がLLMの開発に活かせない現状
ここではコミュニティによって統率された定期的なリリースや公開されたAPI、未来のロードマップの公開、コミュニティからの貢献、誰もが参加できるといったOSSの特徴がLLMの開発においては実現できていないことを、例を挙げて説明している。結果として、Llamaに対して貢献しようとしても大量のクローン化され少しずつ異なるLlamaモデルが発生しているため、困難であると語った。

Llamaの派生モデルが大量に発生して乱立している状態
そしてRed Hatの経験則から言えば、オープンソースのコミュニティによる開発こそがあるべき姿であることを説明。
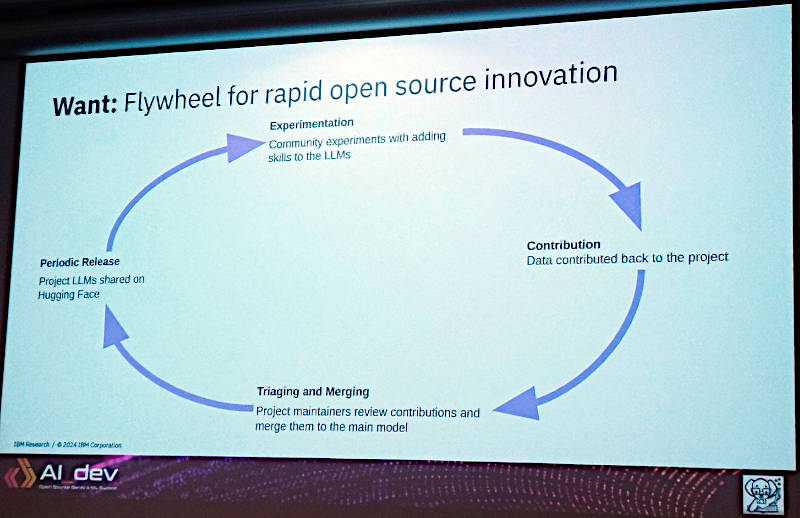
実験~貢献~トレーニングとマージ~定期的なリリースというサイクルを回すことがあるべき姿
ここでは実験~貢献~トレーニングと、マージ~定期的なリリースというサイクルをクローズドな方法ではなくコミュニティが参加することで実行していくことが必要だと説明した。

そのサイクルを回すための方法がLarge-scale Alignment for ChatBotメソドロジー
LLMに対する更新をそのサイクルを回すための方法がInstructLabで採用され、名称の一部にもなっているLAB(Large-scale Alignment for ChatBot)メソドロジーであると紹介。ここでは分類学に従ったデータの収集、大規模なデータ合成、フェーズごとに分かれたチューニングの3つのステップが解説されている。ここで注目したいのは、ナレッジとスキルという2つの分類によるチューニングという部分だ。
より詳しい説明を次のスライドでも行っているが、ここでもナレッジとスキルという分類でデータを収集することが記載されている。

前のスライドをより詳細に解説。ここでもナレッジとスキルが出てくる
そしてそのナレッジとスキルを使ってモデルを更新することがInstructLabの要点であると説明。

ナレッジとスキルを使ってモデルを更新するのがInstructLabの要点
それに関しては例を使って説明している。

ナレッジとスキルのサンプル
ここでは「チキンパルメザンを作るための簡単なレシピを作れ」という例が一番わかりやすいだろう。レシピを作るためにはナレッジとして「チキンパルメザンとは何か?」「必要な材料や調味料は何か?」「簡単なレシピとは何か?」が必要である。一方スキルとしては「結果をレシピとして使えるためにどんなスタイルで書き出すべきか?」を持っておく必要があり、その二つを組み合わせた結果としてレシピが生成されることになる。普通に料理ができる人間が持っている技能をナレッジとスキルという2つに分割してシステムに教え込もうというのが、分類学的なアプローチということになるのだろう。
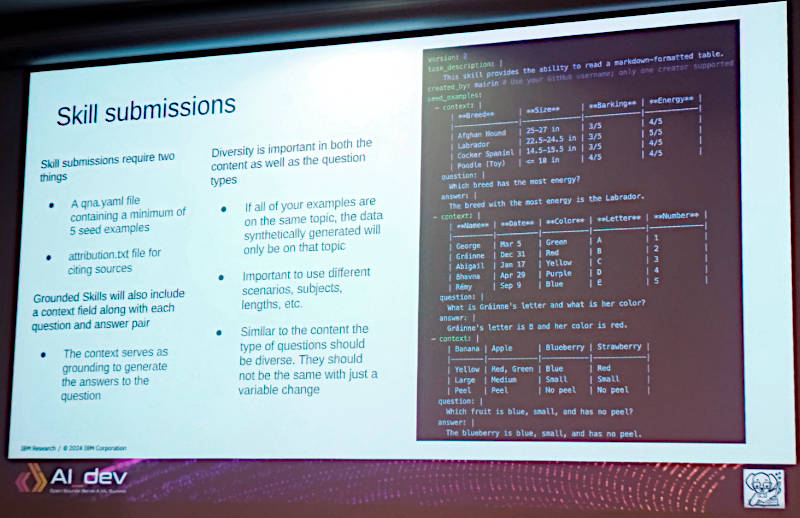
スキルの入力例を紹介
ここからはどういうデータをどのような形式で入力するのかを、CLIの画面を見せながら説明した。ここでは犬の運動量についてアフガンハウンド、ラブラドール、コッカースパニエル、プードルの例を出して、その中から最も運動量の多い種別を選べという質問に答えることでスキルを追加できると説明している。
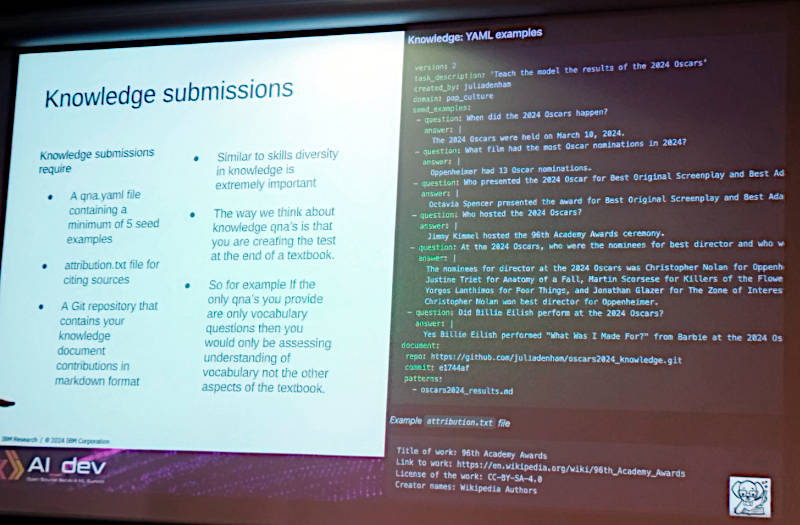
ナレッジの入力例
ここでは2024年のオスカー賞の結果について質問を行うことで事実(ナレッジ)を教えるという内容になっている。どちらの入力にはその情報のソースとなるリンクを追加できるようになっている。この質問と回答はGitのプルリクエストの形で承認待ちとなり、承認を得ないとモデルには反映されない。
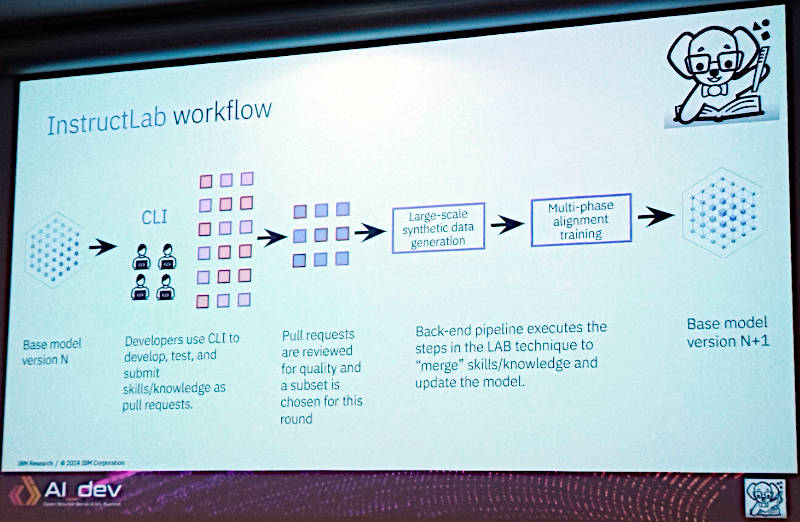
InstructLabのワークフロー
そして追加されたナレッジとスキルはマークダウン形式のデータとしてCLIを通じてプルリクエストの形でモデルに対するファインチューニングとして使われ、結果としてクローンではなく新しいバージョンのモデルとして更新されると解説した。

InstructLabのCLIの流れ
そしてInstructLabで使われるCLIのワークフローを説明した。「ilab init」「ilab download」「ilab serve」「ilab chat」などの具体的なコマンドが列挙され、すでに稼働していることが示されている。実際にRed Hat Summitの会場ではInstructLab専用のハンズオンスペースが設けられており、参加者が実際にプルリクエストを行うまでを体験することが可能になっていた。
最後にInstructLabのバックエンドについても簡単に紹介を行った。ここではプルリクエストが承認した後の工程をVELAというバックエンド側のソフトウェアが行うこととなっている。
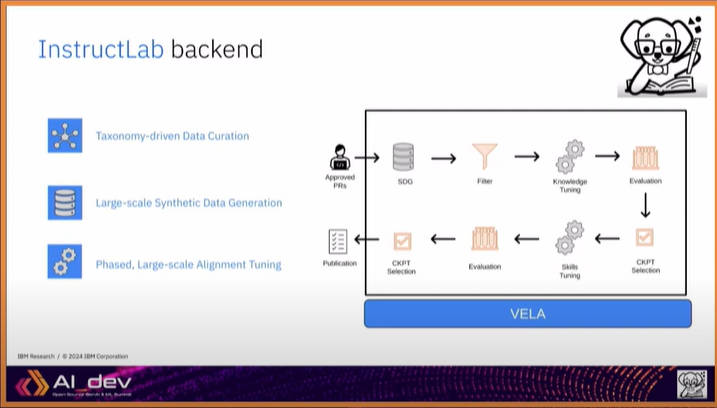
InstructLabのバックエンドについても簡単に紹介
セッションの前半で紹介した「実験~貢献~トレーニングとマージ~定期的なリリース」のサイクルを、オープンソースプロジェクトのように回すという部分の回答が次のスライドだ。
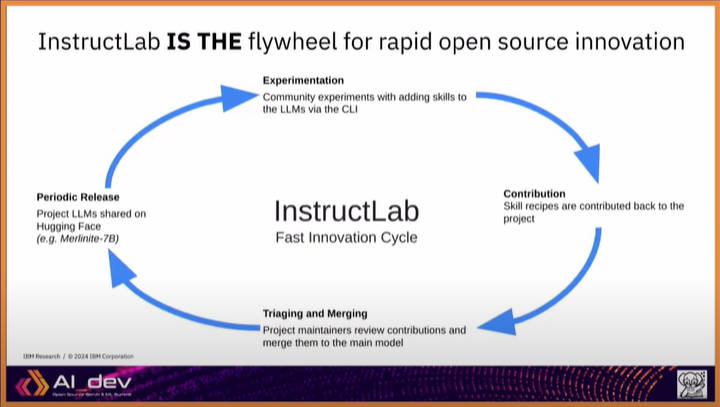
オープンソースLLMの開発サイクルを具体的に実装したのがInstructLab
Red HatとIBMがオープンソース的な方法論でLLMを開発したいという意図がはっきりと伝わってくるセッションとなった。

InstructLabのブース。いつも参加者で賑わっていた
しかしオープンソースによる開発では誰でも参加できるコミュニティであるがゆえに、悪意を持ったコントリビューターがコミュニティの信頼を得た後に悪意のあるコードを意図的に挿入してしまう事例もある。同様に、コードよりも安易にナレッジとスキルを追加できることで、バイアスのあるモデルを生成しようとする層が存在することは容易に想像できる。今後はLLMに付随するコミュニティのモラルが試されることになるだろう。Red HatとIBMは難しいタスクを背負ってしまったという感もあるが、他のベンダーや大学、研究機関、政府などからどれくらいの信頼を得られるのか注目していきたい。
●参考:xz-utilsの脆弱性:XZ Utilsに悪意のあるコードが挿入された問題(CVE-2024-3094)について
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
RustとWASMで開発されKubernetesで実装されたデータストリームシステムFluvioを紹介
2022年12月23日 6:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
