企業で使われるHadoop
第2回
スケール・アウトの課題
スケール・アウトの課題
スケール・アウトが情報爆発時代のコンピュータ・システムにとっていかに重要な課題であることが理解いただけたと思います。しかし、実際にスケール・アウトさせるのはそれほど簡単な問題ではありません。巨大なコンピュータ・システムには、さまざまな「ボトルネック」が存在します。
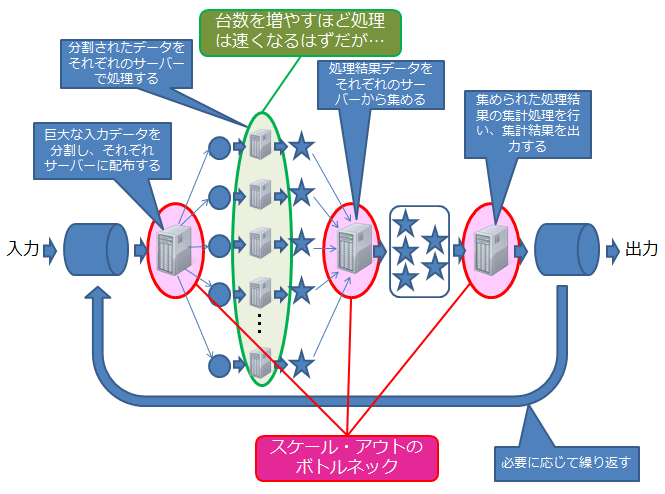
図2に、複数のサーバーでバッチ処理を行うシステムのイメージを示します。このシステムは、入力されたデータを多数のサーバーで分散処理する構成にすることで、台数を増やすほどシステムの処理性能が上がるようになっています。
しかし、ある程度台数が増えてくると、性能向上は頭打ちになります。なぜならば、
- 入力されたデータを分割して各サーバーに配る仕組み
- 各サーバーの処理結果を集める仕組み
- 集められた処理結果を集計してまとめる仕組み
が分散できる構成になっておらず、1台のサーバーで処理しなければならないからです。
こうなると、システム全体の処理性能が1台のサーバーによって制約されてしまうことになってしまいます。このように、システム全体の処理性能の向上を阻む個所のことを、「ボトルネック」と呼んでいます。
|
|
| 図2: 複数のサーバーでバッチ処理を行うシステム(クリックで拡大) |
ほかにも以下のような課題が、壁として立ちふさがってきます。
- システムの耐障害性
- サーバーの台数が増えると、システムのどこかで障害が発生する確率(障害発生率)が増えてしまいます。100台のサーバーで構成されるシステムを例にとって考えてみましょう。ここで、サーバー1台の障害発生率が年あたり5%だとします。年5%という障害発生率は決して高くない数字ですが、システム全体としてみると、障害発生率は年あたり500%となってしまいます。73日に1度は障害が発生する計算です。高い信頼性が求められるシステムでは、この障害発生率では使い物になりません。
- プログラミングが難しい
- 膨大なデータを多数のサーバーによって処理するためには、データをサーバー間で受け渡す仕組みが必要です。データを分割して多数のサーバーに行き渡らせたり、多数のサーバーによる処理結果を集約して1つにまとめたりしなければなりません。しかし、この仕組みは非常に複雑にならざるを得ません。データのどの部分をどのサーバーが持っているかを管理する必要があるほか、一部のサーバーに処理エラーが発生した場合に対処するために、複雑なプログラミングが要求されます。システム構築のたびにこのようなプログラミングを行うことは、コスト面から困難です。
- 資源の効率的な利用が難しい
- システムを構成するそれぞれのサーバーは、CPU、メモリー、ハード・ディスク空き容量などの資源を持っています。台数を増やしてシステム全体の処理能力を上げるためには、すべてのサーバーの資源をできるだけ均等に活用することが必須です。しかし、膨大なデータやタスクを多数のサーバーの間で均等に割り振ることは、かなり難しい問題です。極端なケースでは、1台のサーバーのみに処理が集中して、ほかのすべてのサーバーが遊んでしまうこともあり得ます。
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
