Hadoopのスケール・アウト戦略
Hadoopのスケール・アウト戦略
ここまで述べてきたように、スケール・アウト可能なコンピュータ・システムを構築するためには、いくつかの難しい課題を解決しなければなりません。Hadoopは、世界最大のコンピュータ・システムを運用している米Googleが発表した論文のアイディア、すなわち「Google File System」と呼ばれる分散ファイル・システムと、「MapReduce」と呼ばれる分散処理専用のフレームワークを参考にすることで、これらの問題をうまく解決しています。
図3に、Hadoopによるバッチ処理のイメージを示します。Hadoopのシステムは、親分にあたる1台のマスター・サーバー(NameNodeといいます)と、子分にあたる多数のスレーブ・サーバー(DataNodeといいます)によって構成されています。
それぞれのスレーブ・サーバーに搭載されているハード・ディスクが束ねられて、HDFS(Hadoop Distributed File System)と呼ばれる1つの仮想的な分散ファイル・システムとして扱われます。巨大なデータ・ファイルの入出力と処理は、すべてHDFSを中心にして行われます。
マスター・サーバーは、システム全体のデータの流れをコントロールする役割を果たしていて、データ自体のやりとりはスレーブ・サーバーに任せています。図2と違って、1台のサーバーにデータの流れが集中しない構成になっていることに注目してください。すなわち、Hadoopのシステムには「ボトルネック」になりやすい個所が存在しないのです。
|
|
| 図3: Hadoopによるバッチ処理の仕組み(クリックで拡大) |
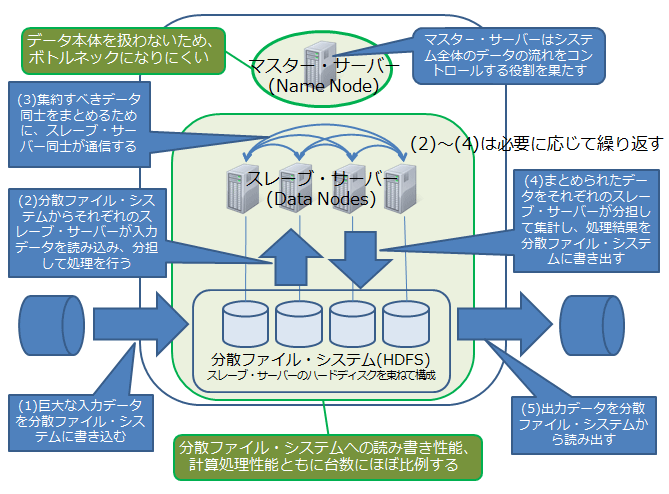
また、スケール・アウトにあたって直面する課題、
- 耐障害性
- プログラミングの難しさ
- 資源の効率的な利用
を、以下の方法の組み合わせで解決しています。
- 分散ファイル・システムにおける多重書き込み
- HDFSは、通常のファイル・システムと同様にファイルをブロック単位で管理していますが、いくつか異なる点があります。障害が発生してもデータが失われないように、ブロックを書き込むときはそのコピーが必ず複数台のスレーブ・サーバーに書き込まれるようになっています。もしいずれかのスレーブ・サーバーが故障した場合には、残っているスレーブ・サーバーの間で失われたブロックが自動的に復元されます。また、ブロックの書き込みは、スレーブ・サーバー間の空き容量が偏らないように、均等に行われます。
- MapReduceフレームワーク
- MapReduceとは、巨大なデータ・ファイルを分散処理するために米Googleによって提案されたフレームワークです。HadoopもMapReduceフレームワークを実装しています。MapReduceフレームワークには、分散処理に必要とされる共通機能(巨大なファイルを分割して多数のスレーブ・サーバーに配布する機能、処理結果を集めて集計する機能、障害が発生した場合に処理をやり直す機能など)がシステム側にあらかじめ実装されています。Hadoopのユーザーは、「map関数」と「reduce関数」という2種類の関数を記述するだけでよいため、複雑なプログラミングをすることなく、大規模な分散処理を実現することができるようになっています。
- タスクの分割
- Hadoopは、MapReduceフレームワークで記述されたバッチ処理を、自動的に多数の小さなタスクに分割し、スレーブ・サーバーにて順番に実行します。1つのタスク処理が終わったスレーブ・サーバーには次のタスクがすぐに割り当てられるため、すべてのスレーブ・サーバーのCPUがフルに活用されます。タスクには、map関数を実行する「Mapタスク」と、reduce関数を実行する「Reduceタスク」の2種類がありますが、このうちMapタスクは、バッチ処理の入力として与えられたデータ・ファイルのブロックに対応しています。それぞれのMapタスクは、可能な限り、対応するブロックを持っているスレーブ・サーバーに割り振られるようになっていて、サーバー間の通信量が小さくなるように工夫されています。また、タスクを実行中のスレーブ・サーバーが故障したときは、失敗したタスクが自動的にほかのスレーブ・サーバーで再実行されます。
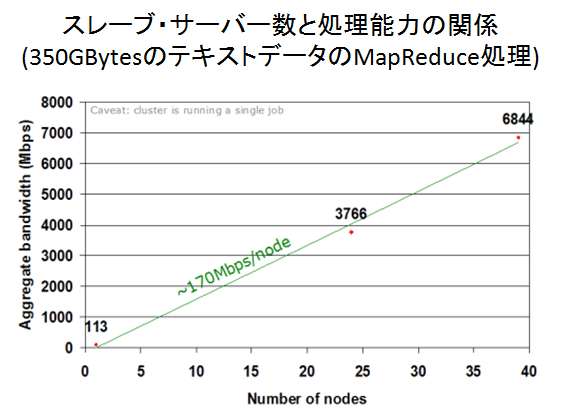
Hadoopが極めて巧妙な仕組みでスケール・アウト性を実現していることがお分かりいただけるかと思います。図4に、Hadoopを構成するスレーブ・サーバーの台数と処理性能に関する実験結果を示します。Hadoopの性能が台数にほぼ比例していることがわかります。
|
|
| Bitqull: Data harvesting with MapReduce(http://www.bitquill.net/blog/?p=17)より引用 |
| 図4: スレーブ・サーバーの台数と処理性能 |
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
