正しいシステム運用のための監視要件定義

「予防」と「原因特定」
前項で、「サービスの監視」を実施していれば、サービスの継続性は監視できていると定義した。それでは、なぜ「サービスの監視」だけでなく、「インフラの監視」が必要なのだろうか。
「インフラの監視」は「、予防」と「原因特定」のために存在する。「サービスの監視」でエラーを検知するということは、エンドユーザーへのサービス提供が不可能な状態を意味するのだ。こうなると、機会損失は計り知れず、サービス継続のためには「障害の前兆を検知する」予防が必要となってくる。
「予防」と「原因特定」の具体例として、図3を示す。
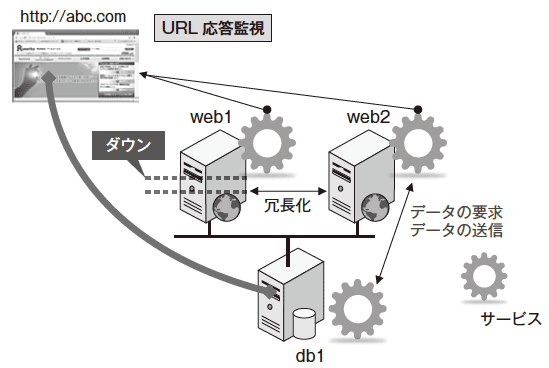
図3では、web1とweb2は冗長化されており、通常は、web1とweb2の2台にアクセスが割り振られる。web1とweb2は、ともにアクティブであり、片側がダウンした場合、1台での運用となる。また、http://abc.comのコンテンツを表示するためには、WebサーバーからDBサーバーへ、格納されたデータを取得しなければならない。
「予防」
図3のような、webサーバーが冗長化された構成のシステムにおいて、web1サーバーがダウンしたことを検知することは、「予防」となる。web1とweb2のどちらかかが稼働していれば、http://abc.comへのアクセスは可能なため、直接的な影響は発生しない。
しかし、web1、web2の両系で稼働していたシステムで、web1がダウンした場合、http://abc.comは、web2のみでサービスを提供する片系の稼働になる。図4は、web1がダウンしたため1台での運用となり、http://abc.comを提供するサービスは継続可能となっている。そうなるとweb2サーバーは、web1サーバーの負荷も担わねばならず、web2の負荷状況に、サービス継続性が左右されてしまうことになる。
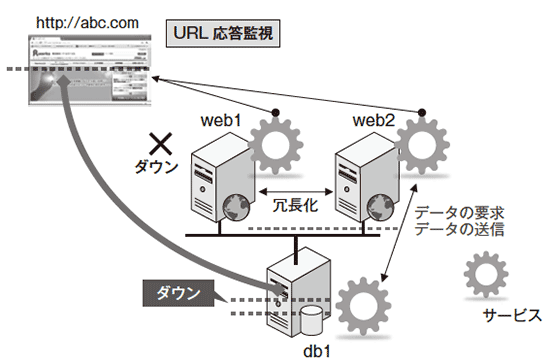
このような、「現状ではサービスの継続はできているが、安定したサービスの継続が難しい」という状況は、「サービスの監視」のみでは検知できないため、「インフラの監視」が必要となるのだ。
「原因特定」
一方、冗長化していないDBサーバーであるdb1がダウン(図4の下部)した場合には、WebサーバーとDBサーバーの連携が崩れることになり、データの同期に問題が生じ、http://abc.comにアクセスしてもエラーとなる。その結果、「サービスの監視」においてエラーが発生したという事実はつかめる。しかし、検知時点では、http://abc.comへのアクセスが不可であるということ以外の情報は判明しない、とも言える。
これでは、復旧作業にとりかかる前に、原因は外部の回線にあるのか、それとも内部の回線なのか、Webサーバーなのか、あるいはDBサーバーなのか、内部プロセスなのか、ハードウェア自体なのか、などなど、すべて検証して「原因特定」に努めなければならない。サービスの継続ができていない状態から、障害原因ポイント、復旧作業の特定のためにも、適切な監視ポイントを設けた「インフラの監視」は必要となる。
監視ポイントの特定
ここでは、監視ポイントの特定について説明する。適切な監視ポイントは、次の手順で特定していく。
- 何のサービスをどう監視するのかを特定する。
- サービスを提供するために必要な要素は何かを特定する。
- 必要な要素はどう絡み合うのかを特定する。
何のサービスをどう監視するのか
まず、「このシステムは、最低限、何を提供しなければならないのか」を特定させなければならない。例として、前項までに説明した、Webページを表示させるシステムを、図5に示す。
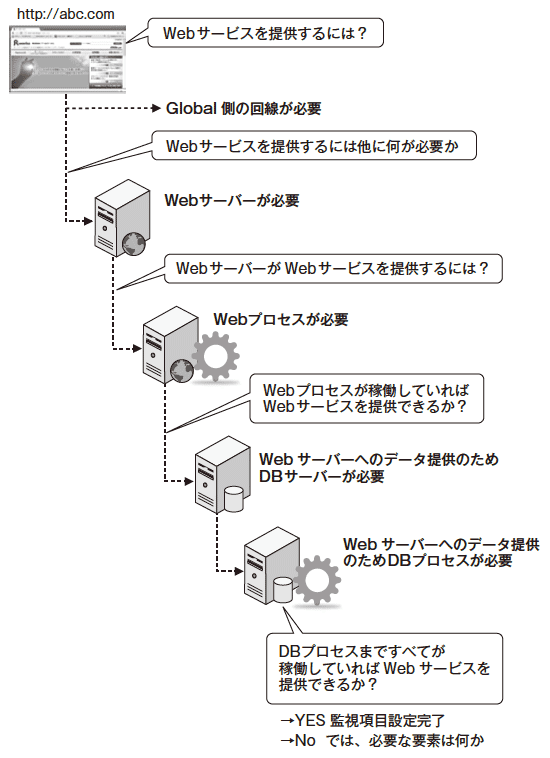
ここで、システムの役割を定義する。このシステムは、「Webページを表示させることが役割であるサービス」と定義する。ここでは、単純なWebシステムとしているが、発注システムであれば、発注を行うまでを監視すべきであり、FAX受信システムであれば、FAXを実際に送付して監視すべきである。
このケースでは「Webページを表示させることが役割」と定義したため、「サービスが役割をまっとうしていることを監視する」とは、Webページが表示されていることを確認し続けることとなる。











