NoSQL登場の背景
NoSQL登場の背景
NoSQLとはリレーショナルデータベース(RDB)以外のデータストアの総称で、その意味は「Not Only SQL」の略とされています。近年、NoSQLが開発されてきた背景として、インターネット利用の拡大に伴う、データ量およびアクセス数の増大が挙げられます。
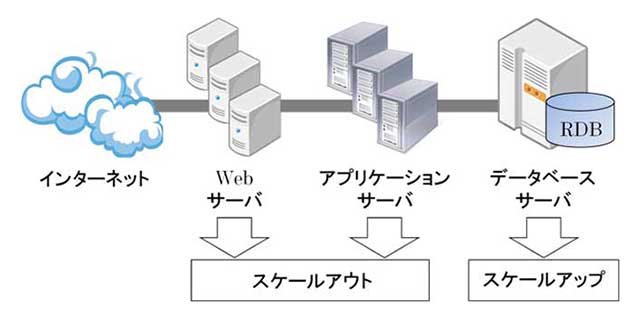
図1: Webシステムの構成(クリックで拡大)
一般的なWebシステムは図1のような3階層アーキテクチャを採っています。Webシステムへの負荷が増大した場合、Webサーバやアプリケーションサーバは物理マシンの追加(スケールアウト)により負荷分散するのが一般的です。これに対してデータベースサーバ(RDB)では、物理マシンが持つハードウェアリソースの追加・増強(スケールアップ)が一般的です。
しかしハードウェアリソースの追加・増強には限界があり、日々増大していくデータ量・アクセス数に対して、スケールアップで対応を続けるのは困難でした。そこで、この問題に対応可能なスケールアウト型のデータストアとして、NoSQLは開発されてきました。
NoSQLの特徴
| データストアの課題 | NoSQL | RDB | ||
|---|---|---|---|---|
| 1) 大量データの蓄積 | ○ | スケールアウト型アーキテクチャ | △ | スケールアップ型アーキテクチャ |
| 2) 高速な書き込み処理 | ○ | 高速なデータアクセス | △ | 速度よりもデータ整合性を重視 |
| 3) 非構造データの保存 | ○ | スキーマレス | △ | スキーマ定義が必要 |
表1: センサーデータのデータストアの課題に対するNoSQLおよびRDBの適合性
NoSQLは様々なものが開発されてきており、現在では100以上の実装が存在すると言われています(参考:NOSQL Databases)。それぞれに特徴が異なるため、共通する特徴を列挙することはできませんが、概ね次の特徴を備えているようです。
1.スケールアウト型アーキテクチャ
上述の開発背景からスケールアウト型のものが多いです。複数の物理マシンでクラスタを構成し、全体として1つのデータストアを作ります。冗長化構成をとれるものが多く、高い可用性を持ちます。
2.高速なデータアクセス
メモリ活用によりディスクアクセスを抑え、データアクセスを高速化しています。また、トランザクションやSQLなどの高度な機能を使わず、独自APIによる限定的な機能を使うことで、データアクセスのオーバーヘッドを小さくしています。分散構成やデータ複製を利用してアクセスを並列化し、速度を向上させるものもあります。
3.スキーマレス
RDBではデータ保存に先立って、保存予定のデータ構造の定義が必要です(スキーマ定義と呼ばれます)。運用開始後は、通常はスキーマの変更はできません。それに対してNoSQLでは、運用開始後にスキーマ変更できるものや、スキーマ定義が不要なものがほとんどです。異なる構造のデータを区別せずに保存できるため、非構造データの保存にも適しています。
表1に示したとおり、RDBはセンサーデータの蓄積というユースケースには、あまり適していないと言えます。一方でNoSQLは、その特徴がデータストアの要件と適合しており、センサーデータ蓄積に適していると言えます。
NoSQLの分類
上述のとおりNoSQLには様々な実装があります。ここでは主要な3つのデータモデル(アプリケーションから見たデータ構造)に分類されるNoSQLをご紹介します。
| データモデル | Key-Valueストア(KVS) | カラム指向 | ドキュメント指向 |
|---|---|---|---|
| データ構造のイメージ | 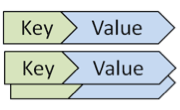 | 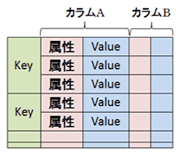 | 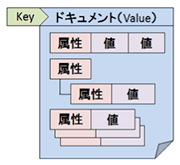 |
| 特徴 | ・データアクセスが高速 ・小さい多数のデータの蓄積が得意 | ・一部のものはスキーマ定義が必要 ・カラム指定での範囲検索・集計処理が得意 | ・ドキュメント毎に異なるデータ構造を持てる ・属性に対する検索・集計が可能 |
| 活用例 | ・キャッシュサーバ ・ログ蓄積 ・オブジェクトストレージ | ・ログ蓄積 ・ログ分析 ・大規模データ処理 | ・ログ分析 ・Webシステム ・オンラインゲーム |
| OSS例 | ・okuyama ・Riak ・memcached ・Redis | ・Cassandra ・HBase ・Hypertable | ・MongoDB ・CouchDB ・Couchbase Server |
表2: データモデルによるNoSQLの分類
1.Key-Valueストア(KVS)
データストア内で一意なKey(識別子)と実際に保存するデータであるValue(値)の、ペア形式でデータを持ちます。Valueの中に複数のサブキーを持たせてグルーピングができるKVSもあります。
2.カラム指向
Keyに対して複数のカラムを持ち、リレーショナルモデルに近いデータ構造を持つことができます。カラムにネスト構造を持たせられるものもあります。また、テーブルやカラムのスキーマ定義が必要なものもあります。KVSと比較して検索・集計処理を得意としており、ログデータの分析などに適していると考えられます。
3.ドキュメント指向
Keyに対して、「ドキュメント」と呼ばれるJSONやXMLなどの形式のデータを持ちます。ドキュメント内はネスト構造や配列などの複雑なデータ構造を採ることができます。スキーマレスであり、ドキュメントによって異なるデータ構造を持てます。
データ構造の自由度が高く、アプリケーションから使いやすい形式でデータを保存できるため、Webシステムのバックエンドなどに適していると考えられます。
これらの中でKVSは構造が最もシンプルであるため、センサーデータ蓄積システムのような小さくて大量のデータの蓄積や、高速なデータアクセスが必要な用途に最適と考えられます。
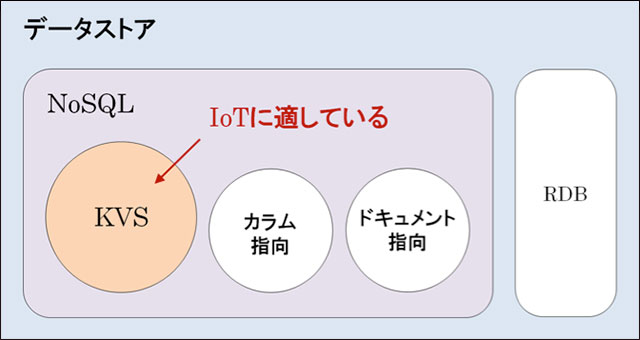
図2: KVSの位置づけ(クリックで拡大)
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
