本連載では、5回にわたってスプレッドシートを使用したGoogle DriveとApp Engineのデータ交換について紹介しました。今回は、特別編として連載第2回で少し触れたApp EngineのDatastoreをBigQueryと連携する方法について説明します。具体的には、Datastoreに書き込まれたSpreadデータをCloud Storage経由でGoogle BigQuery(以降、BigQuery)へデータロードします。BigQueryは巨大なデータを様々なフォーマットで格納し、SQLライクなクエリーを超高速に実行できるGoogle提供のツールです。
App EngineのCloud Datastoreに書き込まれたデータは、アプリケーションによってはビッグデータとなり、その内容を解析することで企業等にとって有用な情報を得られます(注)。そのためにはビッグデータ処理システム(ここではBigQuery)へのデータロードが必要ですが、Google Drive経由、またはApp EngineのUIからCloud Datastoreに書き込まれたデータはプログラムの記述が不要で、マウス操作と簡単なキー入力のみでBigQueryにデータロードできます。
注)ビッグデータの解析は、マーケティングにおける評判分析(自社製品の強み弱み)、需要の抽出、ナレッジの自動蓄積(顧客電話対応センターで頻出するQ&Aの分類)、リスク管理(故障、不具合の関連情報)などの他、高度にはゲノム(遺伝情報)解析などにも有効利用できます。
1.システム構成とデータロードの準備
ここから、BigQueryへのデータロードについて具体的な手順を見ていきますが、今回の処理内容は図1右の「BigQueryロード」で示す部分です。AppEngineから書き込まれたCloud Datastoreのデータを一旦Cloud Storageにロードし、そのデータをBigQueryにロードする必要があります。ただし、その手順は前述したようにプログラム記述は必要なく、マウス操作が主体で補助的にキー入力を行う程度です。
1.1 連携システムの構成
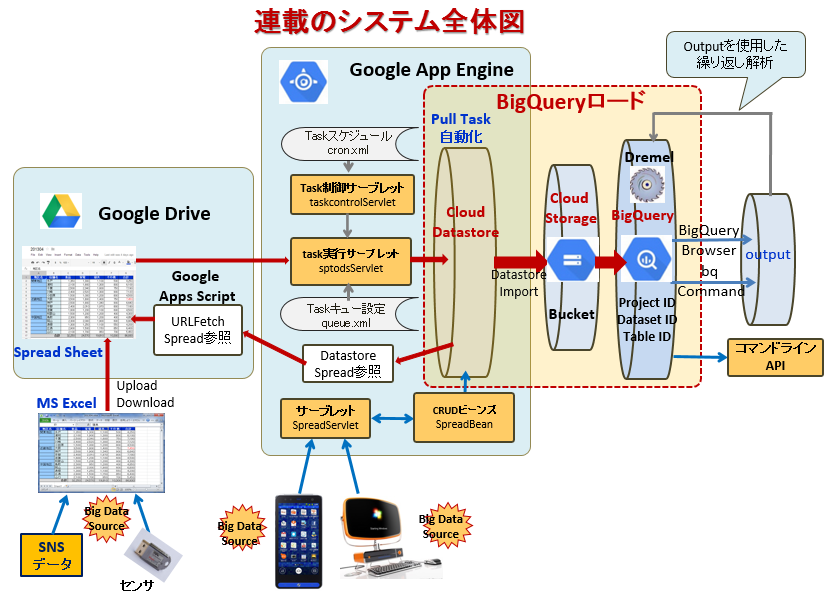
図1:連載のシステム全体図とCloud DatastoreからBigQueryへのデータロード
図1では、App Engineで受注管理システムのようなアプリケーションを作成し、そのデータをApp Engine標準のCloud Datastoreに書き込む動作を想定しています(コラム1)。Cloud Datastoreにはアプリケーションで作成されたデータをEntity単位で、理論的にはデータ量の制約なく追加登録できるため、大量のデータを保存できます。Cloud Datastoreに書き込まれたデータをEntity単位で一括してCloud Storageにロードし、同様にCloud StorageからBigQueryへロードすることで大量のデータを処理できます。
また、本連載でも見てきたように、センサの出力データなども処理対象のビッグデータとして大変有効です。TwitterやFacebookといったSNSの書き込みデータを自動で収集してくれるツールなどもあり、ExcelやCSV形式で出力してそのままデータソースとして使用できます。
なお、ここからの処理手順では、Googole Developers Console(以下、Developers Console)とGoogle App Engineの管理者画面(以下、App Engine管理者画面)を使用します。
例えば、大手コンビニの売り上げ情報がどの程度のデータ量になるかを考えてみます。国内総店舗数を12,000店、店舗毎の商品点数を3,000点とすると、
- 店舗別年データ数 3,000 * 365 = 1,095,000
- 総店舗年データ数 1,095,000 * 12,000 = 13,140,000,000
- 1項目で10バイト必要とすると 13,140,000,000 * 10 = 131,400,000,000バイト
- 10年分のデータとすると 13,140,000,000 * 10 = 1,314,000,000,000バイト = 1.314テラバイト
1.314テラバイトは非常に多いデータ量です。しかし、ビッグデータの処理対象としては厳密に言えば少ないかもしれませんが、解析には売上以外の項目のデータも必要になるため、それらのデータも含めれば充分にビッグデータシステムの処理対象と言って良いでしょう。
1.2 BigQueryを使用するための設定を行う
BigQueryにデータロードするための事前準備として、下記の設定を行う必要があります。
(1)Googleアカウントを取得する
本連載を読まれている方であればGoogleアカウントを取得されていると思いますので、ここでは省略します。取得されていない方は連載第1回「3.3.1 Geogleアカウントを取得する」(http://thinkit.co.jp/story/2013/10/01/4472/page/0/1)を参照してください。
(2)Google Developer Consoleで新規プロジェクトを作成する
次に、BigQuery用に新規プロジェクトを作成します。初めてBigQueryを使用する場合は、使用料が300ドルまで課金されない無料体験版を利用できます(図2)。
図2:Google Cloud PlatformのBigQueryページ(https://cloud.google.com/bigquery/?hl=ja)
無料体験版を利用する場合は、図2の画面左下「今すぐ試す」、または右上「無料体験版」をクリックして、ユーザー登録を行います。Google Cloud Platformを使ったことがある人は、https://console.developers.google.com/projectをクリックしてGoogleアカウントにログインし、Google Developer ConsoleのProjects画面からプロジェクトを選択します。
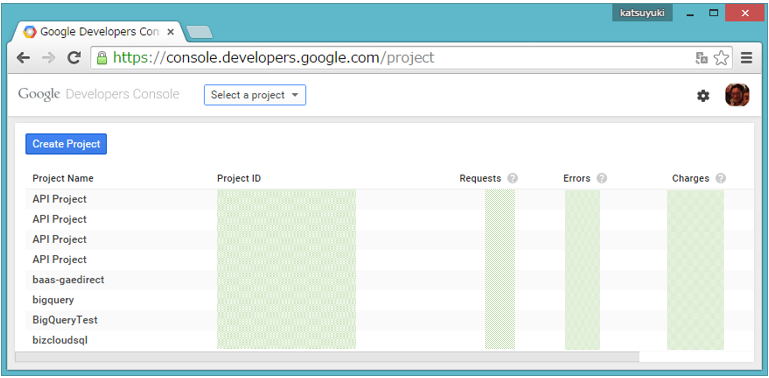
図3:Google Developer ConsoleのProjects画面
筆者の場合、すでに多くのプロジェクトが登録されており図3のような画面表示になりますが、最初の登録ではブランク画面になっているはずです。なお、登録済のProject ID等は見えないようにグレイの枠で囲ってあります。新たなプロジェクトで処理を行う場合は、図3の画面左上「Create Project」(青色)をクリックするとプロジェクト作成用の画面(New Project)が表示されるので、この画面から「Project name」と「Project Id」、「Billing account」を指定してプロジェクトを作成します。
BigQueryにデータロードする場合は、課金登録をしてテーブルを作成する必要があります。上記で作成したプロジェクトを選択し、画面左ペインのメニューから「Billing」をクリックすると表示される画面で「Enable billing」をクリックし、カード情報を入力します。無料体験版であればユーザー登録時に入力したカード情報が適用されますが、300ドルまでは課金されません。また、無料体験版でなくても月1テラバイトまでの使用には課金されず、他のビッグデータ処理システムと比べて使用料がかなり安くなっています(コラム2)。
次に、画面左ペインのメニューから「BigData」の下にある「BigQuery」を選択すると、図4のように左ペインに予め用意されているサンプルデータが表示されます。「gdelt-bq-full」などは Dataset名で、その下のeventsなどはTable名です。
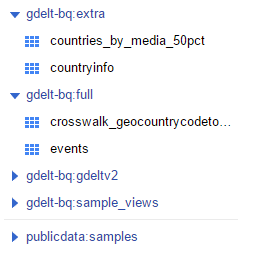
図4:サンプルテーブル
例えば、「events」を選択して画面右の「Query Table」をクリックすると、画面上部にクエリー文の入力フィールドと基本構文が表示されます(図5)。
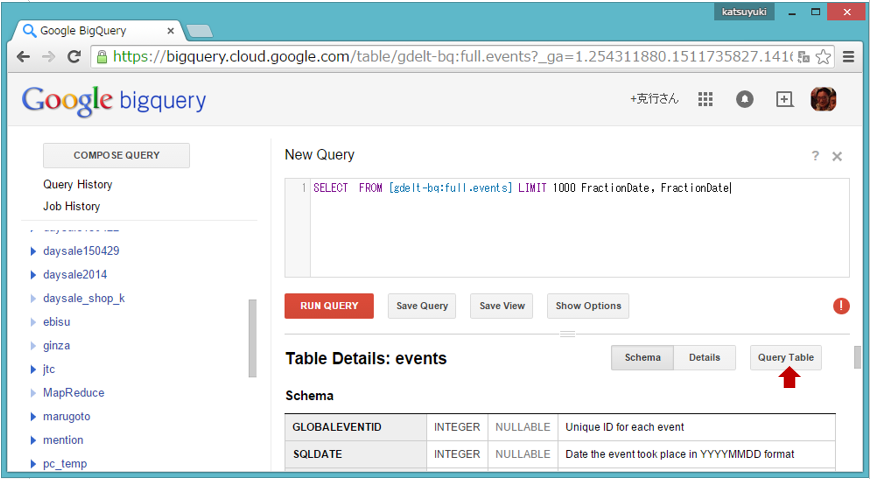
図5: 「Query Table」クリックでの画面表示
画面上部の入力フィールドに表示されているクエリー文に「*」を追加して
SELECT * FROM [gdelt-bq:full.events] LIMIT 1000とし、「RUN QUERY」(赤色)をクリックすると、図6のようにクエリーの実行結果が表示されます。これで、BigQueryが動作していることを確認できます。
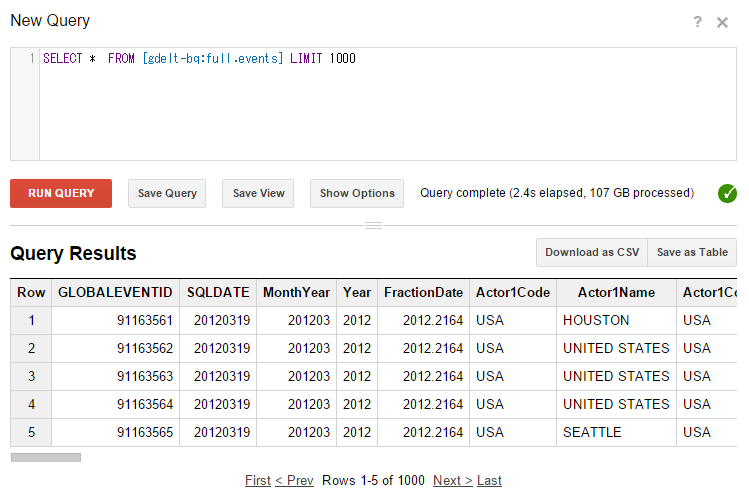
図6:クエリー実行結果の表示
本記事執筆時点におけるBigQueryのデータ使用量と料金は、下記のようになっています。
| リソース | 料金 |
|---|---|
| データロード | 無料 |
| データエクスポート | 無料 |
| ストレージ | $0.020(GB単位/月) |
| 会話型クエリー実行 | $5(処理容量単位: TB) ※月毎処理データ1TBまでは無料 |
| バッチでクエリー実行 | $5(処理容量単位: TB) ※月毎処理データ1TBまでは無料 |
| ストリーミングインサート | 2015年7月1日まで無料 |
- この記事のキーワード
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
