コンテナの作成
コンテナの作成
今回はApache SparkをBay上にデプロイする。Apache SparkはUC BerkeleyのAMPLabによって開発された、高速でインタラクティブな言語統合クラスタコンピューティング基盤である。今回作成するクラスタの構成図を図3に示す。
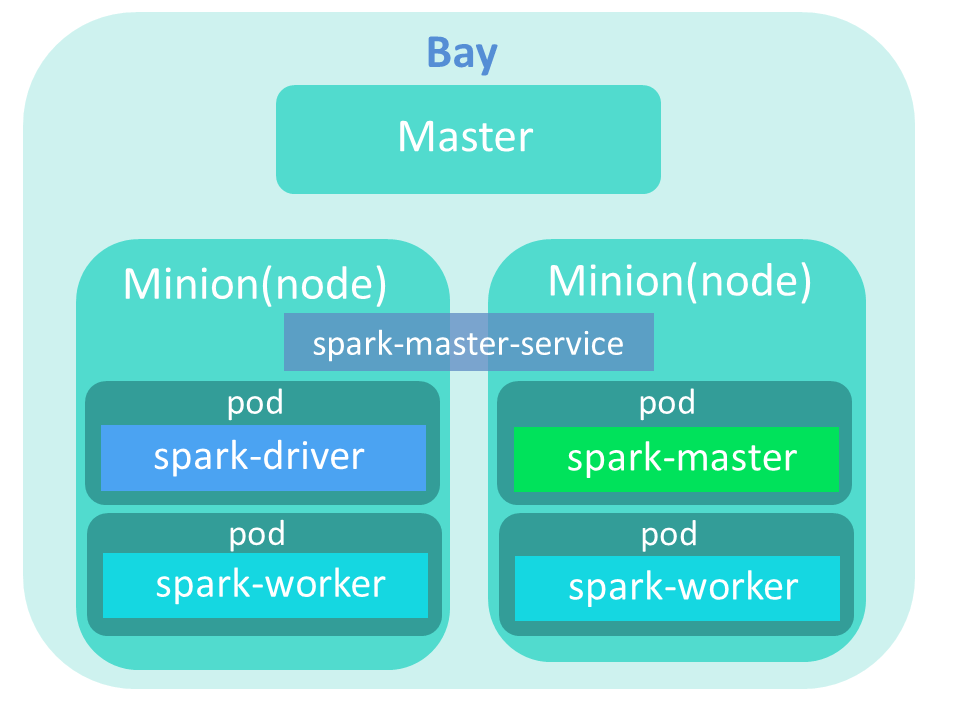
図3:作成するクラスタの構成図
作成するコンテナは、以下の4つである。
| spark-master | Sparkのマスターノードが入っているコンテナ |
|---|---|
| spark-worker×2 | Sparkのワーカノード(スレイブノード)が入っているコンテナ |
| spark-driver | Sparkアプリケーションを起動するためのdriverが入っているコンテナ |
今回はKubernetesをエンジンとして使用しているため、コンテナはPodというものに内包して作成される。Podとは、複数のコンテナの集まりを示した単位である。今回の場合は一つのPodに対して一つのコンテナとしているが、本来は複数のコンテナをまとめることができる。また、Serviceとしてspark-master-serviceを登録する。ServiceはL3プロキシのような、ネットワークをつかさどる役割を持つ。また設定されたPodに対して、ラウンドロビンのアクセス分配が可能である。今回の作成例では、Podの数が一つしかないspark-masterがServiceに設定されているため、アクセス分配は発生しない。Kubernetesに関しては、以前の連載記事「注目すべきDockerの周辺技術 PanamaxとKubernetes」で詳しく解説されているので、参考にしてほしい。
Sparkのexampleを使用するために、Kubernetesをダウンロードして解凍する。
$ cd
$ wget https://github.com/kubernetes/kubernetes/releases/download/v1.1.0-alpha.1/kubernetes.tar.gz
$ tar -xvzf kubernetes.tar.gz
spark-masterのPodを作成する。
$ cd kubernetes/examples/spark
$ magnum pod-create --manifest ./spark-master.json k8sbay
Serviceを作成する。
$ magnum coe-service-create --manifest ./spark-master-service.json --bay k8sbay
manifestファイルの記述を変更して、Replication Controllerを作成する。今回は、ノードの数に合わせてreplicasの数を2に変更する。Replication Controllerは対象のPodをreplicasの数になるように管理してくれる。管理対象のPodはspark-workerとしている。今回はreplicasの数を2としたので、何らかの要因でPodの数が増減した場合はPodの数が2になるように調整される。
$ sed -i 's/(\"replicas\": )3/2/' spark-worker-controller.json
$ magnum rc-create --manifest ./spark-worker-controller.json --bay k8sbay
Sparkの動作確認
まず、作成したBayを確認する。
$ magnum bay-show k8sbay
+--------------------+------------------------------------------------------------+
| Property | Value |
+--------------------+------------------------------------------------------------+
| status | UPDATE_COMPLETE |
| uuid | c1a2ee79-adc7-425d-ad62-906377b4ee89 |
| status_reason | Stack UPDATE completed successfully |
| created_at | 2015-09-28T07:40:25+00:00 |
| updated_at | 2015-09-28T07:52:19+00:00 |
| bay_create_timeout | 0 |
| api_address | 172.24.4.4:8080 |
| baymodel_id | b1496fcc-05cc-4ca7-b471-dd806e598897 |
| node_count | 2 |
| node_addresses | [u'172.24.4.6', u'172.24.4.7'] |
| master_count | 1 |
| discovery_url | https://discovery.etcd.io/11a1b540f86420e7f3369afc36a02e23 |
| name | k8sbay |
+--------------------+------------------------------------------------------------+
今回はノードが2つあり、作成したコンテナはKubernetesによって、どちらかのノードに割り当てられている。まず、node_addressesに書かれている2つのIPアドレスに対して接続を行い、spark-driverがどちらのノードに割り当てられているかを確認する。docker psコマンドにおけるIMAGEの項目に「gcr.io/google_containers/spark-driver」と記載されているものが、spark-driverのコンテナである。
まず、一方のノードをIPアドレスで指定して、sshでログインする。
$ ssh minion@172.24.4.6
ノード内のコンテナを確認する。
$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STA
90b83253cf33 gcr.io/google_containers/spark-worker:1.4.0_v1 "/start.sh" 2 minutes ago Up er-controller-gv0nt_default_48378678-7154-11e5-be23-fa163ed643ba_c71039c7
bdf6adb9bf6d gcr.io/google_containers/pause:0.8.0 "/pause" 2 minutes ago Up ller-gv0nt_default_48378678-7154-11e5-be23-fa163ed643ba_d1ffafea
b90ade19891a gcr.io/google_containers/spark-master:1.4.0_v1 "/start.sh" 29 minutes ago Up er_default_2a982590-7150-11e5-be23-fa163ed643ba_ac8bfd61
71e8827bb519 gcr.io/google_containers/pause:0.8.0 "/pause" 31 minutes ago Up t_2a982590-7150-11e5-be23-fa163ed643ba_cc982738
spark-driverがノードに存在しなかったらノードから抜ける。
$ exit
続いて、もう一つのノードも確認する。
$ ssh minion@172.24.4.7
$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STA
2dc1adbe3855 gcr.io/google_containers/spark-driver:1.4.0_v1 "/start.sh" 2 minutes ago Up er_default_674d685b-7154-11e5-be23-fa163ed643ba_92f6e3d1
c3259cc5efc8 gcr.io/google_containers/pause:0.8.0 "/pause" 2 minutes ago Up _674d685b-7154-11e5-be23-fa163ed643ba_c45dd5f8
952e8851a0d9 gcr.io/google_containers/spark-worker:1.4.0_v1 "/start.sh" 3 minutes ago Up er-controller-xnyg2_default_4837549c-7154-11e5-be23-fa163ed643ba_2ea06215
e4fe6ca02616 gcr.io/google_containers/pause:0.8.0 "/pause" 3 minutes ago Up ller-xnyg2_default_4837549c-7154-11e5-be23-fa163ed643ba_09e3d738
IMAGEの項目に「gcr.io/google_containers/spark-driver」というimageがあることを確認する。spark-driverが存在している場合は、引き続き作業を行うので、ログインしたままにしておく。
まず、spark-driverのコンテナに入る。-itの後にはspark-driverのCONTAINER IDを指定する。
$ sudo docker exec -it 2dc1adbe3855 bash
root@spark-driver:/#
次に、pysparkを起動する。
root@spark-driver:/# pyspark
Python 2.7.9 (default, Mar 1 2015, 12:57:24)
[GCC 4.9.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
15/10/13 02:49:17 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Python version 2.7.9 (default, Mar 1 2015 12:57:24)
SparkContext available as sc, HiveContext available as sqlContext.
以下のコードを実行して、Sparkのクラスタに所属しているspark-workerをリスト形式で表示する。
>>> import socket
>>> sc.parallelize(range(1000)).map(lambda x:socket.gethostname()).distinct().collect()
['spark-worker-controller-gv0nt', 'spark-worker-controller-xnyg2']
このように2つのspark-workerコンテナがSparkのクラスタに所属していることが確認できた。
まとめ
今回は、OpenStack Magnumの環境構築およびコンテナの制御を行った。実際に触ってみて、いくつかメリットとして感じたことがある。
オーケストレーションツールの選択が可能
今回はKubernetesを使用したが、そのほかにもDocker SwarmやMesosなどにも対応している。今後は、Magnumで対応するオーケストレーションエンジンが、さらに増えることを期待したい。
オーケストレーションツールの導入が不要
Kubernetesのようなツールは、導入するだけでも多くの時間を必要とする可能性があるので、OpenStackの導入さえ乗り越えればツール導入の手間を省けるのはありがたいと感じる。
クラスタのテナント管理
MagnumでBayを作成する際は、OpenStackの認証機能であるKeystoneの認証を通して行う。Kubernetes単体ではクラスタに認証をかけることはできなかったが、Magnumで扱うクラスタはテナントごとに管理されているため、セキュアなものとなる。
今後、連携してほしい機能としては感じたのは、ネットワーク関連の機能である。現時点ではエンジンにKubernetesを指定した場合、ノード内およびノード間でコンテナに対して接続することはできるが、OpenStackの外からコンテナに対して接続することができない(現時点ではMagnumのプロジェクトにBlueprintsとして登録されている)。今後、この辺の問題をNeutronなどと連携して解決してほしいと思う。
Support the kubernetes service external-load-balancer feature
https://blueprints.launchpad.net/magnum/+spec/external-lb
OpenStack Magnumはまだまだ発展途上で、実用に供するためには、もう少し時間がかかると思われる。特に、Magnumの内部で動いているコンテナオーケストレーションツールの動作が不安定に感じられた。今後、Magnumに対する機能追加や内部で動作しているエンジンの動作が安定することで、Magnumが多くの人に使われ始めることを期待している。
- この記事のキーワード
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
