目次
- はじめに
- 大量の質の良いデータが必要
- 学習データを用意する方法
- データのクレンジング
- データの水増し(Data Augmentation)
水増しというとなんだか不正請求のような悪いイメージがつきまといますね。でも、機械学習におけるデータの水増しは少ないデータでも学習精度を上げるためのテクニックで、特にCNN(畳み込みニューラルネットワーク)などを使った画像処理で効果を発揮します。
水増しは、元の学習データに線形変換を加えてデータの数を増やすことを言います。線形変換とは、左右反転したり、位置をずらしたり、ノイズを増やしたり、コントラストを変えたり、ズーム・変形したりする処理です。
図4を例に説明しましょう。バラとボタンの花の画像が各々1000枚あったとき、通常なら学習データ各700枚、評価データとテストデータ各100枚ずつ配分するところを、学習データを4倍に水増しして各2800枚用意します。ここでは左右反転、コントラスト変換、位置ずらしの3パターン用意したとしましょう。その結果を通常の認識率と比較して、認識率が高まっていれば”水増し成功”です。図4:少ないデータでも認識率を高められる水増しただし、やみくもに水増しして数を増やせば良いかと言うと、そう簡単な話ではありません。実際に判定する画像にないような学習データを食わせてしまうと、かえって認識率が下がってしまいます。例えば、手書き文字認識のためのデータセットMNISTを使って文字認識を学習する際に、左右反転などの水増しを使うのはおバカさんということになります。 また、データが少ないのにオリジナルと似たような画像をたくさん学習させ過ぎると過学習(Over Fitting)に陥りやすいです。過学習とは、社会適応力がないガリ勉君のようなもので、学習に使ったデータ認識に特化し過ぎて、汎用的なデータの認識率(汎化性能)が落ちてしまうことでしたね。<<メモ>>ドロップアウトとアンサンブル学習過学習を防ぐためにドロップアウト(Dropout)と呼ばれる機能がよく使われます。これはInput−Hiddun(隠れ層)−Outputというディープラーニングの構造において、学習を繰り返す際に隠れ層のノードの一部を無効にするものです。 1つの学習器で学習する代わりに、別々に学習した学習器の結果を統合して汎化性能を高める技術をアンサンブル学習(Ensemble Learning)と言います。ドロップアウトは疑似的なアンサンブル学習です。学習を繰り返すたびにランダムにノードの一部が非活性となるので、学習器の構造が毎回少しずつ違います。それらを総合して学習する方が、ガチガチに同じ構造の学習器で学び続けるよりも汎化性能がアップするのです。
- 転移学習(Transfer Learning)
- アクティブラーニング
はじめに
前回までは、現在の人工知能の基礎的な技術を理解するためにハードウェア、ライブラリ、AIプラットフォームといったベーシックな要素を見てきました。さて、今回からはいよいよ第2部に入ります。第1回でも紹介したように、第2部では「これからのAI」について語っていきます。今回は、機械学習の仕組みや人工知能をビジネスに活用するためのポイントについて解説します。
大量の質の良いデータが必要
現在、多くの人が「AIを使って何かをやりたい」と考えています。本来は「これをやりたいのでAIを使う」という順番で考えるべきですが、今の局面は”人工知能の活用”を前面に出してものを考えても良いと思います。
その際に最初にぶち当たる壁が大量な学習データの用意です。AIも最初は赤ん坊のように無垢で無知です。きちんと学習させることによって初めて役に立つ存在になります。そのため、とにかくそれなりのボリュームの、それも質の良いデータがなければ学習できません。図1に機械学習を行う際に心得ておくべき3つのことを掲げています。今回は1番目の「データの準備、クレンジング」を中心に説明します。

図1:機械学習を行う際に心得ておくべきこと
学習データを用意する方法
まず、どのようにして大量データを用意するかを考えてみましょう。一般に学習データを用意する方法としては、図2のような手段が考えられます。
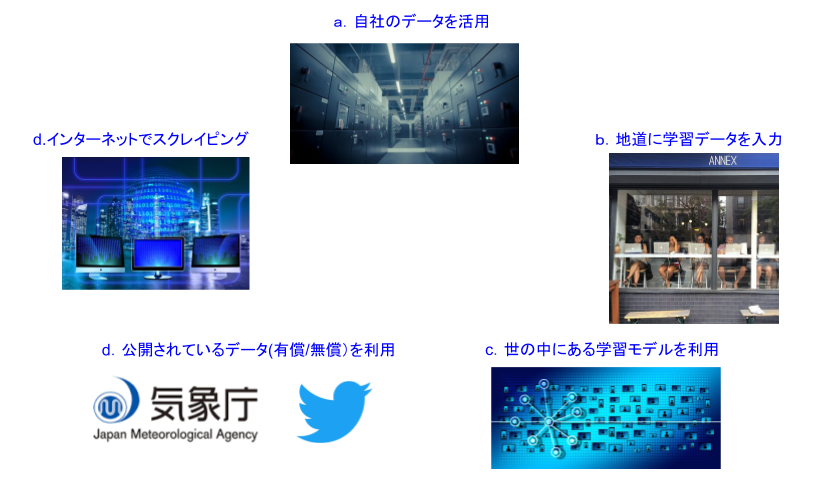
図2:学習データを用意する方法
(1)自社のデータを活用する
既に自社の中にそれなりのデータがあるので、これらを使って有益なことをやれないか。まずは、そういう発想でAIを活用することを考えるのが基本でしょう。
(例1)小売業の需要予測
3年間の販売データのうち、2年分で学習して直近1年間の需要予測と実績の近似性を確認します。このとき、d.の公開されている気象庁のデータなども組み合わせます。因子要因をきちんと把握して近似性が高くなれば、今後の需要予測に使えます。
(例2)製造業の品質検査
過去4年に発生した品質不良品のデータが一定量あるならば、そのうち80%と正常画像を混ぜて教師あり学習を行います。そして残り20%をテストデータとして判定精度を確認し、認識精度が高ければ今後の自動品質チェックに利用できるようになります。
(2)地道に学習データを入力する
AIの仕組み(分類器)を作成するために、手動または自動で学習データを地道に作成してゆく方法です。すぐに利用できるデータがない場合は、この正攻法しかありません。
(例)パーソナルアシスタント
自社で蓄積したナレッジへの問い合わせ回答を行うパーソナルアシスタントを作成する際に、 まずは地道に応対の言葉、業界用語、自社製品などの言葉を教えます。アクティブラーニングも組み合わせて学習させ続けるうちに、少しずつ応答が高度化され役に立つ存在になっていきます。
(3)世の中にある学習モデルを使う
画像認識や自然言語理解などでは、さまざまな学習済みモデルが用意されているので、これらを使わない手はありません。イチから学習させる場合においても、学習済みモデルを使った転移学習を使えば少ないデータで学習できます。
(例)作業場所での点呼
第2回で紹介したResNetやInceptionなどの学習済みデータを使えば、人物の検出や特定などをすぐに覚えてくれます。写真の顔写真を覚えさせることにより、いちいち点呼を取らずとも誰が出勤しているか一瞬で記録できます。
(4)公開されているデータ(有償/無償)を利用する
人工知能の活用方法のうち、予測(Prediction)では自分たちのデータだけでなく、過去の市場のデータや気象のデータなどを利用して学習します。
(例)イベントの来場者予測
過去のイベント来場者データに気象庁が公開している気象データやTwitterが提供しているつぶやきのデータを重ね合わせて因子要因を見つけ出し、今後のイベントの来場者を予測します。
(5)インターネットでスクレイピングする
スクレイピングとは、インターネット上の各サイトをクロール(順繰りにWebサイトにアクセス)して、サイト上の情報を抽出するソフトウェア技術です。
(例)ナレッジデータベース作成
インターネット上のホームページをクロールして、欲しい情報をテキスト解析して取得するようなスクレイピングでナレッジデータベースを作成します。
データのクレンジング
日本の女性なら誰でも知っているクレンジング(Cleansing)という言葉は、洗顔の前に化粧を落とす意味の和製英語ですね。一方、データクレンジング(Data Cleansing)は海外でも一般に使われている英語で、データを利用する前にデータを変換・整理したり不適切なデータを除去したりする前処理を意味します(図3)。

図3:データクレンジングで不適切なデータを除去
機械学習においては、このデータクレンジングが非常に重要です。なぜなら、学習データは単に量が多ければ良いというものではないからです。不適切な学習データをそのまま与えると、それが悪影響となり却って検出精度が低下してしまうので、学習データに対して適切なクレンジング処理を行います。
データクレンジングではどのようなことに注意すべきでしょうか。不適切なデータとはどのようなデータを言うのでしょうか。画像認識を例にして、クレンジングのポイントをいくつか説明しましょう。
(1)人間でも判定に困るデータは食わせない
一概に単に写りが悪いからと言って悪いデータとは限りません。実際のデータで写りの悪い画像を判定する必要があれば、この後説明する”水増し”などの技術を使ってきちんと学習する必要があります。ただし、人間でも判定できないような画像はAIでもうまく特徴点を見つけられません。そのような画像データで学習させると悪い影響を与えることが多いです。
(2)誤ったオブジェクトが対象になっていないか注意
例えば顔認証させているつもりなのに、AIは背景にある時計を対象にしていた、というようなミスマッチはよく起こります。きちんと対象オブジェクトを検出しているかチェックして、トンチンカンな検出しているデータは正しく検出できるように調整するか削除します。
(3)間違ってラベル付けしない
間違ったことを教えれば当然間違って覚えます。人が手間をかけて準備したデータではあまり起こらないと思いますが、どこかにあるデータをインポートして学習データに使う場合はこうしたミスが起こり得るので注意してください。
(4)間違われやすいデータも学習する
AやBがよくXに間違われるという場合、AやBの学習よりもXを正しく学習させる方が効果的な場合もあります。つまりAやBのデータだけでなくXの学習データも十分に必要となる場合があるので、Xのデータを十分確保できるかも考えてください。
(5)未知(本番)データもクレンジングする
画像認識の学習では、画像のサイズや向きなどがバラバラだと学習しにくいので、これらをクレンジングしてできるだけ揃えます。もし、これから判定する本番データにも同様のデータがある場合は、それらも自動クレンジングしてから判定させる処理が必要となります。
(6)未知(本番)データを意識する
本番のデータがどのような画像なのかを意識して学習させます。例えば、製品の外観検査なら大きさが一定の画像となるでしょうが、消費者がネット上にアップする画像ならサイズや角度、鮮明度などもまちまちです。世の中にある学習済みモデルは、特徴点を検出しやすいように少しずつ角度をずらして画像を撮ったりしています。自分で学習させる場合も、場合によってはそのような配慮が必要です。
さて、ここまで品質の良いデータが大量に必要と説明してきましたが、この1、2年で少ないデータで機械学習させるための技術が次々と出てきて、今のニューラルネットワークのライブラリには標準でこれらの技術を利用できるようになっています。その中から代表的なものを2つ説明します。
データの水増し(Data Augmentation)
水増しというとなんだか不正請求のような悪いイメージがつきまといますね。でも、機械学習におけるデータの水増しは少ないデータでも学習精度を上げるためのテクニックで、特にCNN(畳み込みニューラルネットワーク)などを使った画像処理で効果を発揮します。
水増しは、元の学習データに線形変換を加えてデータの数を増やすことを言います。線形変換とは、左右反転したり、位置をずらしたり、ノイズを増やしたり、コントラストを変えたり、ズーム・変形したりする処理です。
図4を例に説明しましょう。バラとボタンの花の画像が各々1000枚あったとき、通常なら学習データ各700枚、評価データとテストデータ各100枚ずつ配分するところを、学習データを4倍に水増しして各2800枚用意します。ここでは左右反転、コントラスト変換、位置ずらしの3パターン用意したとしましょう。その結果を通常の認識率と比較して、認識率が高まっていれば”水増し成功”です。
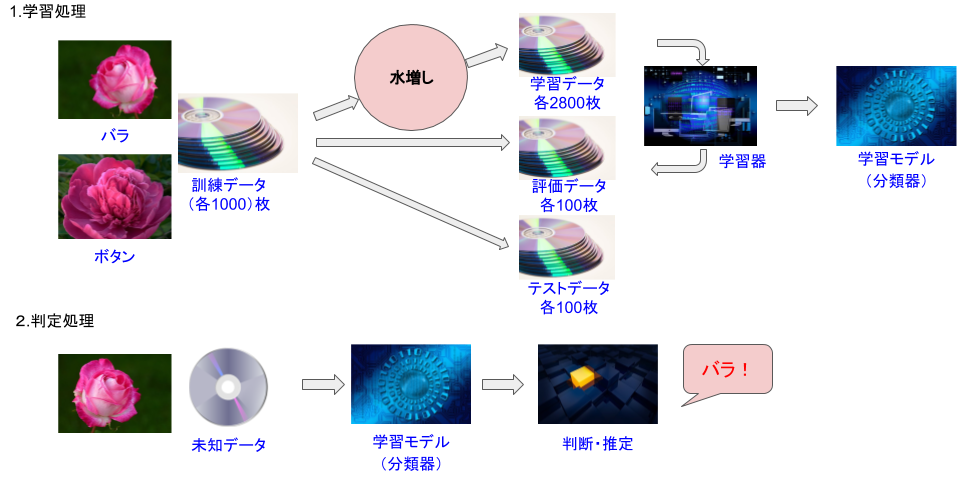
図4:少ないデータでも認識率を高められる水増し
ただし、やみくもに水増しして数を増やせば良いかと言うと、そう簡単な話ではありません。実際に判定する画像にないような学習データを食わせてしまうと、かえって認識率が下がってしまいます。例えば、手書き文字認識のためのデータセットMNISTを使って文字認識を学習する際に、左右反転などの水増しを使うのはおバカさんということになります。
また、データが少ないのにオリジナルと似たような画像をたくさん学習させ過ぎると過学習(Over Fitting)に陥りやすいです。過学習とは、社会適応力がないガリ勉君のようなもので、学習に使ったデータ認識に特化し過ぎて、汎用的なデータの認識率(汎化性能)が落ちてしまうことでしたね。
過学習を防ぐためにドロップアウト(Dropout)と呼ばれる機能がよく使われます。これはInput−Hiddun(隠れ層)−Outputというディープラーニングの構造において、学習を繰り返す際に隠れ層のノードの一部を無効にするものです。
1つの学習器で学習する代わりに、別々に学習した学習器の結果を統合して汎化性能を高める技術をアンサンブル学習(Ensemble Learning)と言います。ドロップアウトは疑似的なアンサンブル学習です。学習を繰り返すたびにランダムにノードの一部が非活性となるので、学習器の構造が毎回少しずつ違います。それらを総合して学習する方が、ガチガチに同じ構造の学習器で学び続けるよりも汎化性能がアップするのです。
転移学習(Transfer Learning)
少量データで学習させる方法として、水増しと並びよく使われる技術が転移学習です。この言葉も癌の転移などいまいちなイメージがありますが、これは既にある優秀な学習済みモデルを利用して学習するという、効果が大きい技術です。
例えば2014年の画像認識コンテストILSVRCで優勝したGoogleNetは22層のCNN(畳み込みニューラルネットワーク)モデルでしたが、これをベースにした48層のInception-v3という学習済みモデルがあります(図5)。転移学習は、訓練された特徴抽出部(ニューラルネットワーク)を再利用します。再利用させる層は指定可能で、例えば図5では45層をフリーズ(凍結)し、最後の3層を切り捨てて新たな層に置き換えています。
フリーズした層はそのまま既存モデルで固定され、最後の3層だけで追加学習しますが、すでに大量の画像で十分に学習して”出来上がっている”重みをそのまま流用できるため、少量データかつ少ない回数で学習できるのです。
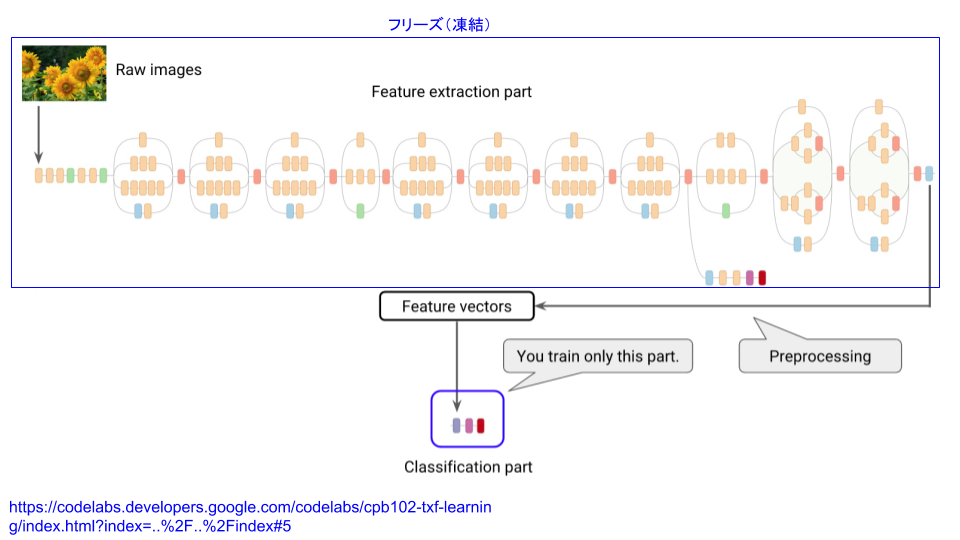
図5:Inception-v3を使った転移学習
アクティブラーニング
現代の教育では、学ぶ人が能動的かつ参加型で学べるアクティブラーニングという学習スタイルがブームです。やっと響きの良い言葉が出てきましたね。でも、ここで言うアクティブラーニングは、それとは全く別で機械学習における学習スタイルを指しています。
機械学習の基本スタイルは、図4のように最初に学習させて学習モデル(分類器)を作成し、それを使って未知のデータの判断・推定を行うものです。この判断結果をそのまま100%信頼する場合もありますが、人間が確認を行って最終的な判断を行うことも多いです。そして、AIが判断したものが誤っていた場合に、人間が正しく修正したデータを追加の学習データとして学ばせるのが機械学習におけるアクティブラーニングです。
アクティブラーニングのパターンには、次の2種類があります(図6)。
a. すべて人間がチェックする
人間がAIの判断結果をすべてチェックし、誤りを見つけて修正したデータを学習データとして利用する。
b. AIが自信ないもののみ人間がチェックする
人間はAIの確信度(Confident)が低いもののみをチェックし、誤りを見つけて修正したデータを学習データとして利用する。
アクティブラーニングでは、リアルタイムで追加学習させることも考えられますが、人間が修正したデータを一定期間(量)ためてからバッチで学習させるのが普通です。
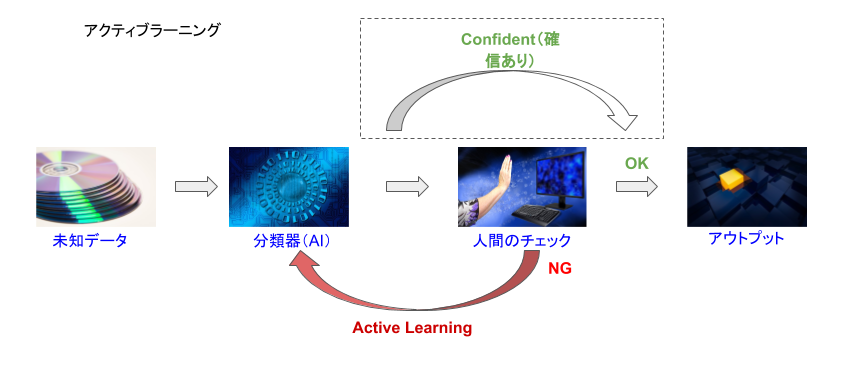
図6:機械学習におけるアクティブラーニング
今回は、機械学習の仕組みを理解し、学習データの重要性やデータクレンジング、少量データで学習する技術などを説明しました。次回は、機械学習と深層学習でよく使われるアルゴリズムについて解説します。
- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
