KubeCon North America 2025、BloombergによるAIをマルチクラスターで実装したKarmadaのセッション
KubeCon North America 2025にて、BloombergによるAIをマルチクラスターで実装したKarmadaのセッションを紹介する。
2月11日 5:59
KubeCon+CloudNativeCon North America 2025から、Bloombergがマルチクラスター管理のためのツールKarmadaをAIワークロードのために実装したユースケースのセッションを紹介する。登壇したのはBloombergのTessa Pham氏とWei-Cheng Lai氏だ。予定されていたKarmadaのメンテナーであるHuaweiのHongcai Ren氏は参加できなかったとして、2名でのプレゼンテーションとなった。タイトルは「Karmada in Action: Scaling AI Workloads Across Multi-Cluster at Scale」意味としてはKarmadaを使ってAIワークロードをマルチクラスターにスケール可能な形で実装したというユースケースの解説である。動画は以下のリンクから参照可能だ。
●動画:Karmada in Action: Scaling AI Workloads Across Multi-Cluster at Scale

本来参加を予定していたHuaweiのエンジニアは参加せず、Bloombergのエンジニア2名で実施
BloombergはキーノートでMailchimpやAirbnb、ByteDanceとともに、クラウドネイティブなシステムの実装を紹介している。そこではKubernetesを初期バージョンから継続して利用していること、Kserveを使ってAIワークロードを実行していることなどを紹介していたが、ここではさらに踏み込んでマルチクラスターでのスケジューリングを解説するという内容となった。ちなみにクラスターを跨いだスケジューリングとしてKarmada、クラスター内のスケジューリングとしてKueue、学習などのバッチジョブ管理のためにはVolcano、この3つのソフトウェアはCNCFのエコシステムにおいてAIワークロード実行のためのオープンソースソフトウェアとして存在している。それぞれのソフトウェアについては以下の記事を参照されたい。
●Karmada:KubeCon China 2025、Bloombergによるマルチクラスター抽象化のセッションを紹介
●Kueue:KubeCon North America 2024からAIワークロードのスケジューリングに関するセッションを紹介
●Volcano:KubeCon China 2025開催、中国ベンダーによるキーノートを紹介
後半で解説されることになるが、バッチジョブに関してはKarmadaからVolcanoに制御を渡してマルチクラスター内でのバッチジョブがスケジューリングされていることがわかる。それ以外にもApache SparkやApache Flink、Apache Trinoなどが使われていることが、2025年開催のKubeCon Chinaでのセッション(https://thinkit.co.jp/article/38558参照)で解説されている。Bloombergにとってはすでに何度も解説を行っているユースケースであることがわかる。軸を変えて何回も紹介するほど、Bloombergにとっては自信のある成功例ということだろう。

プレゼンテーションを行うPham氏とLai氏
最初はPham氏による、マルチクラスターの上でAIワークロードを実行する背景を解説する部分からプレゼンテーションが始まった。

マルチクラスターでのAIワークロード実行環境を必要とする背景を解説
ここではベンダーロックインなども挙げられているが、最も重要なポイントは高可用性と耐障害性、そしてレイテンシーの削減などであろう。Bloombergはマルチクラスターを分散学習とリアルタイムの推論のために利用しているため、レイテンシーは大きな課題であることがわかる。もうひとつのポイントはハードウェアが統一されておらずさまざまなサーバーを抽象化してデベロッパーに提供したいというもので、クラウドネイティブなシステムらしいポイントと言えるだろう。ここではオンプレミスのH100やAWSのインスタンスが例として挙げられているように、必ずしも最新最速のハードウェアだけが提供可能であるわけではなく、優先順位によってコストと処理時間をマルチクラスター上で最適化したいという発想は多くのAI、機械学習エンジニアが感じている思いだろう。

一般的なマルチクラスター運用の課題とAIのためのマルチクラスターの課題を解説
このスライドでは一般的なマルチクラスターの課題と、それをAIに使った場合のBloombergが考える課題を解説している。レイテンシーに加えてどのCPU/GPUが使えるのか? を可視化することが必要であり、ここでも多種多様なハードウェアを使いこなすことが課題であることが挙げられている。

Karmadaの概要を紹介
このスライドではKarmadaの特徴を紹介しているが、Kubernetesをマルチクラスター環境でスケジューリングしたいというニーズに合わせて開発されているため、なるべくKubernetesの作法に合わせて使えるように設計されているところがポイントだろう。複数のKubernetesクラスターを束ねる中央に位置するコントローラー自体がKubernetesで実装されている。デベロッパーはカスタムリソースを使って必要とするリソースを定義し、それをインタープリターと呼ばれる変換メカニズムを使って配下のKubernetesのリソースに変換した上で、Podのスケジューリングを行うというのが主なメカニズムだ。当然、クラスターの状態を常に監視するヘルスチェックが実装され、それによって高可用性が実現できていることが後半に解説される。
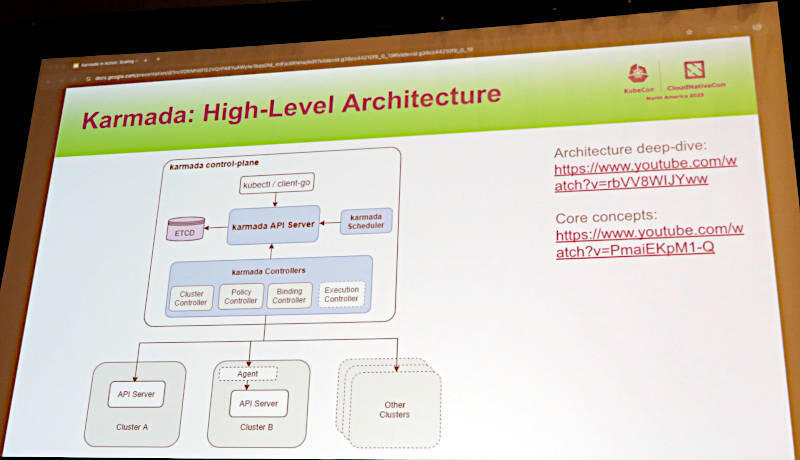
配下のクラスターを制御するKarmadaのコントロールプレーン
ここからはマルチクラスターのスケジューリングの内部を解説し、デベロッパーが記述したリソースを変換するインタープリターの動きについても解説している。
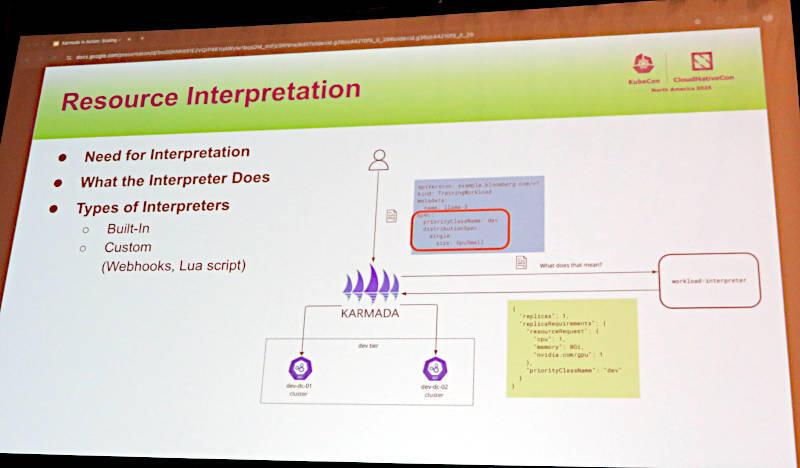
Karmadaが理解できるようにリソースを変換する仕組みを解説
Podのスケジューリングについては、Podが要求するリソースとクラスターが提供するリソースを突き合わせるために、ポリシーとして定義された条件に従って実行されることを解説。ここでは学習のためのPodがAWSからAzureに再スケジュールされた例を使って解説を行った。
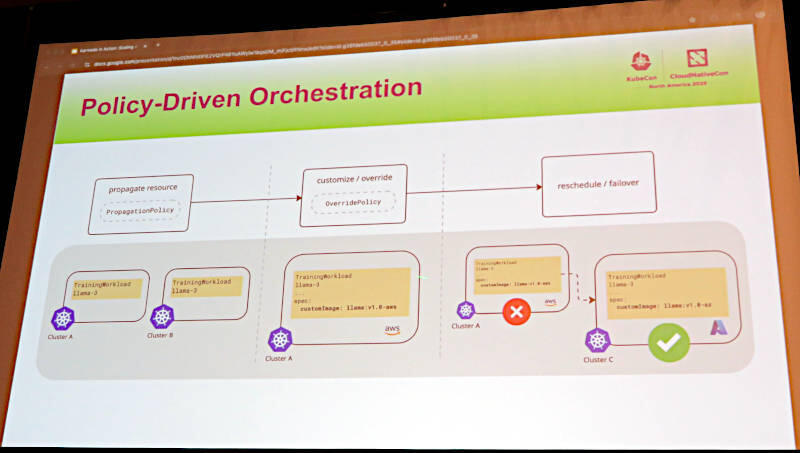
リソースの定義をKarmadaが解釈することで実行可能なクラスターに再スケジュールする例
また推論ジョブの例を使って「どこで何を実行するのか?」をKarmadaのスケジューラーが理解して配下のクラスターからリソースを割り当てるという動作を解説した。
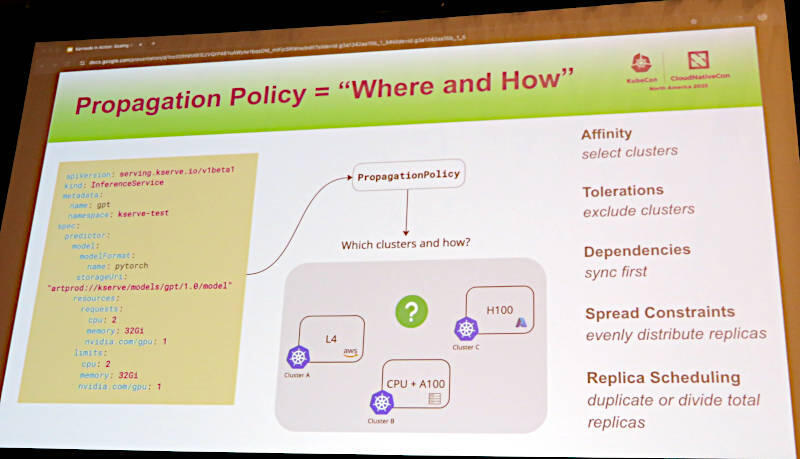
どのクラスターで何を実行するのか? をKarmadaが割り当てることでオーケストレーションを実行
ここではPropagation Policyと呼ばれているが、高可用性と低レイテンシーを優先した割り当てやハードウェアを限定したPodの割り当て、優先度によってレプリカ数を増やす割り当て方法などが紹介された。ポリシーには複数の種類が存在しており、Propagation Policyはその一つである。

クラスタースケジューリングのポリシーの例を紹介
またスケジューリングを行う際に、Podが要求するリソースを書き換えることも可能であるとしてその概要を紹介。ここではKserveによって実行されるレプリカ数を変える例が解説された。
ここでWei-Cheng Lai氏にプレゼンテーションを交代。ここからはクラスターが持つGPUなどのリソースをマルチクラスターで管理するためにはクォータ(上限)を管理する必要があることを解説した。
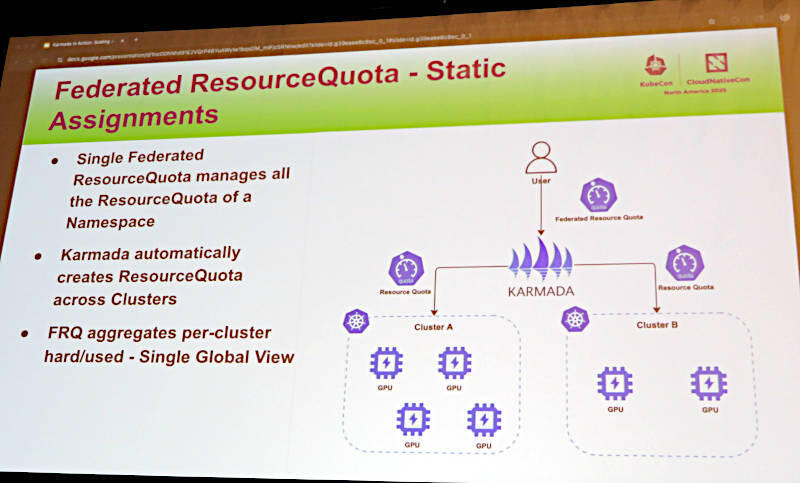
Karmadaによるクラスターの持つリソースを管理する仕組みを解説
複数のクラスターを横断する形でクォータを管理する仕組みは、FederatedQoutaEnforcementという名称でアルファバージョンとして実験的な機能実装が行われていることが記載されている。
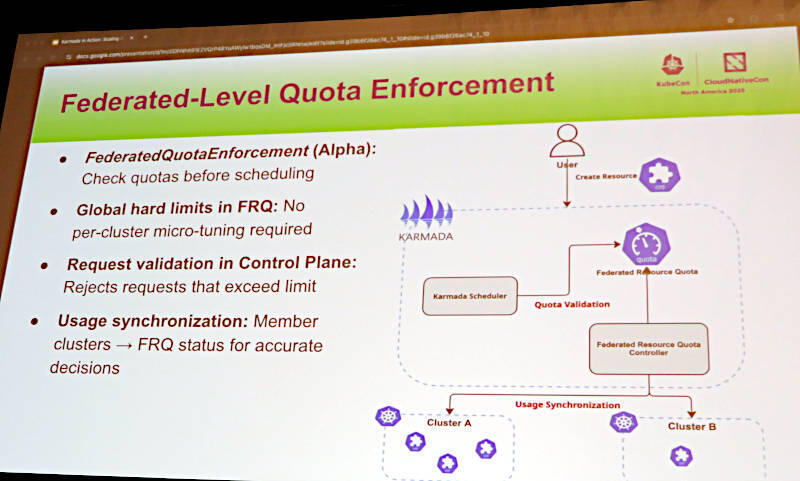
アルファバージョンのFederatedQoutaEnforcementでクラスターの持つリソースを管理
この機能によって、実際に必要とされるリソースがどのクラスターでも提供できない場合は、実行時にエラーになるのではなく実行のリクエストを送った時点で拒否されるという仕様になっているようだ。
またバッチジョブの管理ツールであるVolcanoについても、Karmadaを利用することでシングルクラスターからマルチクラスターでのバッチキュー管理が可能になったことを説明した。
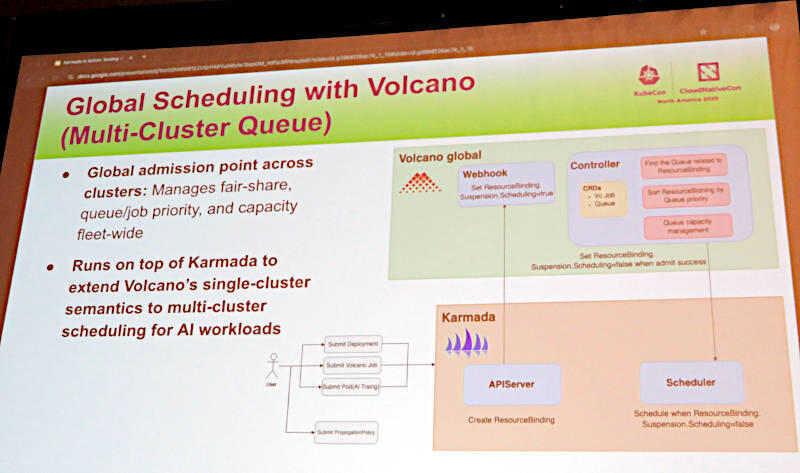
Volcanoをマルチクラスターで使えるようにKarmada上に実装
同様に高可用性についてもシングルクラスターから複数のクラスター間でPodのオートスケールができるように、Federated HPA(Horizontal Pod Autoscaler)Controllerが実装され、高い可用性が実現できていると説明。
クラスター自体が障害などで使えなくなる場合には、ワークロードを他の実行可能なクラスターにフェイルオーバーすることが可能になっていると説明した。
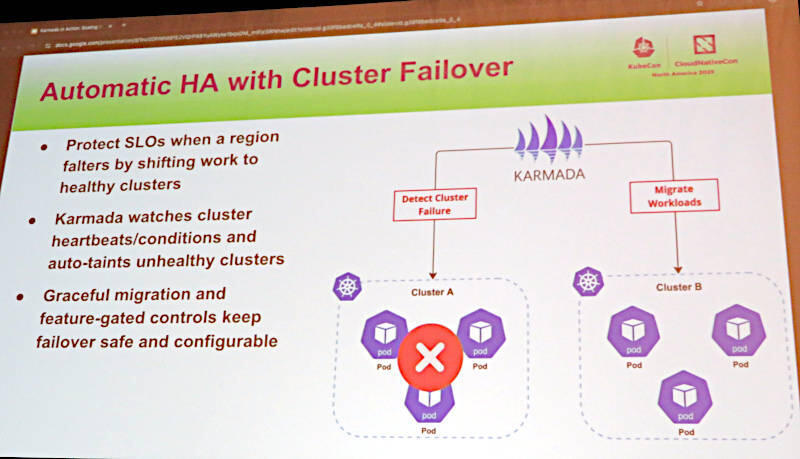
クラスターが実行不可の状態になった場合には自動的に他のクラスターにフェイルオーバー
アプリケーションレベルのフェイルオーバーについてもKarmadaで実装されていることが説明され、クラスター間の再スケジューリング/フェイルオーバー、クラスター内のオートスケール、アプリケーションレベルでのフェイルオーバーなど多くのユースケースを想定して、KarmadaがBloombergのAIアプリケーションを可能にしていることが解説された。
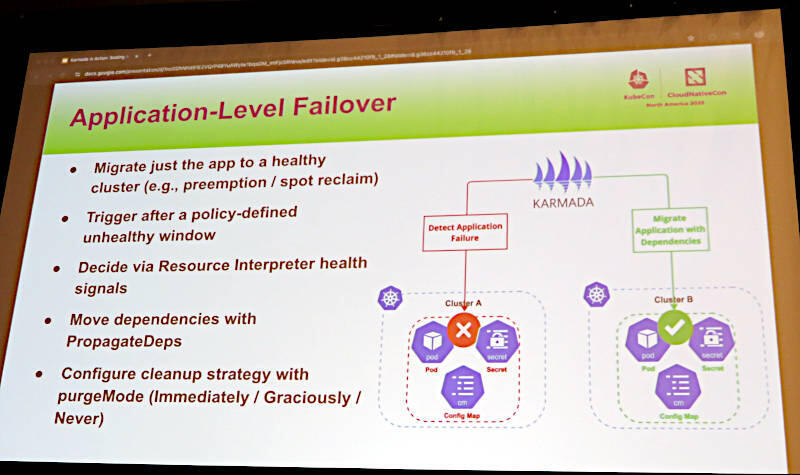
アプリケーションレベルのフェイルオーバーもKarmadaで可能に
最後にまとめとしてKarmadaの持つオーケストレーション機能、CRDを使ったリソース定義とその変換、アルファバージョンではあるが、FederatedResourceQuotaによるリソースの管理、Volcanoと連携したキュー管理、Federated HPAによるアプリケーションフェイルオーバーなどの機能を振り返って、Karmadaの持つ機能を解説した。非常に内容の濃いセッションで、Bloombergというネームバリューの割には参加者が少なかったのは残念である。

大きな会場なのに参加者の数が残念過ぎる
Karmadaについては公式ページも参照されたい。
●Karmada公式ページ:https://karmada.io/
この記事をシェアしてください
関連記事
KubeCon Europe 2025からBloombergによるLLMをKserveで実装するセッションを紹介
2025年5月22日 6:00
KubeCon NA 2024開催、前日の共催カンファレンスからAIワークロードのスケジューリングに関するセッションを紹介
2025年2月19日 5:59
KubeCon North America 2024から、P2P決済のCash Appがマルチクラスター実装を解説するセッションを紹介
2025年4月1日 6:00
KubeCon Europe 2025、GoogleとMicrosoftがSIG発の管理用ツールを紹介
2025年6月10日 6:00
KubeCon North America 2025、ユーザー4社が相乗りしたキーノートセッションを紹介
2月6日 6:00
Oracle Cloud Hangout Cafe Season 4 #5「Kubernetesのオートスケーリング」(2021年8月4日開催)
2024年5月29日 6:30
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
