AAAI-26のInvited Talkから、Sony AIのPeter Stone氏のセッションを紹介
AAAI-26のInvited TalkからSony AIのPeter Stone氏のセッションを紹介。
4月15日 6:00
人工知能の国際会議AAAI-26から、2026年1月22日のInvited Talk「From How to learn to What to learn in Multiagent Systems and Robotics」というセッションを紹介する。Invited TalkはKubeConであればキーノートという位置付けのセッションでAAAIではメンバーであるアカデミアの研究者や企業のエグゼクティブが登壇して約1時間の講演を行うというものだ。ここではテキサス大学オースティン校の教授、Peter Stone氏が自律的なAIを実現するために「どのように学ばせるかではなく何を学ばせるか?」が重要であることを解説した内容となった。
Stone氏はテキサス大オースティン校のLearning Agent Research Group所属であるが、Sony AIのチーフサイエンティストでもある。講演の最後にはSony AIが手がけているAIについても動画で紹介し、Sony AIの宣伝も怠らなかった。

Stone氏は自身の研究の領域について解説。ここでは「自律的なAIエージェントが動的に変化する環境下でリアルタイムに学習することはどこまで可能か?」というテーマが主要な課題であると説明した。ここで重要なのは単一のエージェントではなく複数のエージェントが存在し、それがチームメイトとして補助する場合や敵対するエージェントとして存在する場合も想定して、自律的に学習することでタスクをこなすことがどこまで可能なのか? ということを研究の主要なテーマとしていることだろう。
現実世界においてはエージェント(ロボット)が単体で存在するのではなく、様々な要因によって変化する状況下で補助や妨害を行う他のエージェントに対応しながら目的を達成することが求められる。その時、研究の方向としてはその学習を如何に行うか? ということに向かいがちだが、そうではなく何を学ぶか? が重要だと解説している。

ここではマルチエージェントシステム、ロボティックス、強化学習が強調されていることから分かるように、強化学習によってロボットを操作することを題材にした内容になることが想定できる。
Stone氏は自律的ロボットによるサッカーゲームであるロボカップの動画を再生し、自律的に複数のロボットが動いてゴールにボールを入れる、それを防ぐという動作が可能になっていることを例として示した。また、ロボット対人間のサッカーゲームも紹介。ここでもロボットが人間の動作を予想してゴールを決める例が紹介された。またSonyのゲーム、グランツーリスモにおいてAIが運転する車が人間が運転する車に抜かれないようにブロックする動画も紹介し、レースに勝つためには抜くだけではなく抜かれることを妨害するという動作をAIが学習可能であることを示した。

このスライドではAAAI-26の参加者の大半である学生に対してニューラルネットの研究が「どうやって学ぶか?」に集中し過ぎていることを指摘。ここでは他人と同じことをするな、AIが学ぶ方法ではなく学ぶ対象にも注目して欲しいと訴えた。

このスライドでも幼児の動画を再生し、どうやって学ぶのかと同様に何を使って学ぶのかが重要だと訴えた。

そして、ここからセッションの主なトピックを4つに分類して紹介。AIにとって問題(タスク)が難しすぎることと領域が広すぎること、未知の状況に対応すること、他のエージェントが存在する状況、人間と協調することなどを1つづつ解説した。

「タスクが難しい、領域が広いこと」についてはタスクを分解していく方法を解説。タスクを分けていくだけではなく複数のレイヤーに分離していくLayerd Learningを解説した。ここでは前出のロボカップの動作を分解するダイアグラムを例に挙げて説明を行った。またチェスのルールを学ぶAutomated Curriculum Learningも説明。そして領域が広すぎるという課題については同僚のTodd Hester氏と発表したTEXPLOREという研究を引用して解説。ここでは「現実世界では強化学習によってロボットを制御する際に何を学ばないのか?」を選択することが重要であることを説明した。
●参考:TEXPLORE: Real-Time Sample Efficient Reinforcement Learning

そして「未知の状況への対応」というトピックについてはCausal Reinforced Learningと自身の研究論文であるSLAC(Simulation-Pretrained Latent Action Space for Whole-Body Real-World RL)を紹介。ここではリアルな世界におけるロボットに正しい動作を学ばせることはコストが高いことを挙げて、それを克服するための手法、SLACを紹介した。

ここではリアルな世界に近いシミュレーターを作ることはコストが高いことを挙げ、リアルな世界にロボットをおいて実際に動作させることが近道であることを示した。例としてホワイトボードに書かれた青色の文字だけを消すというタスクを紹介。最初は多くの時間が掛かっていた作業が強化学習によって徐々に速くなり、最終的に他の色の文字を消すというタスクを容易に行えるようになったことを見せた。

SLACの動作についてはダイアグラムを使って説明を行った。状況を認識し、タスクを分解、動作の結果から報酬を計算したうえで次の動作に移るというループを解説した。
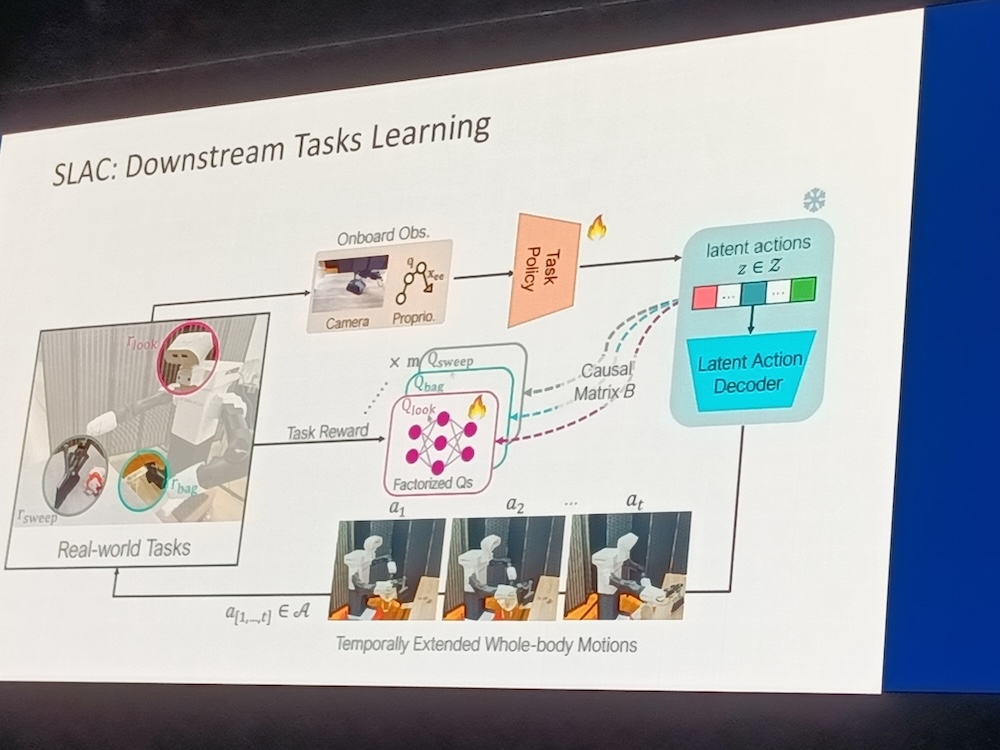
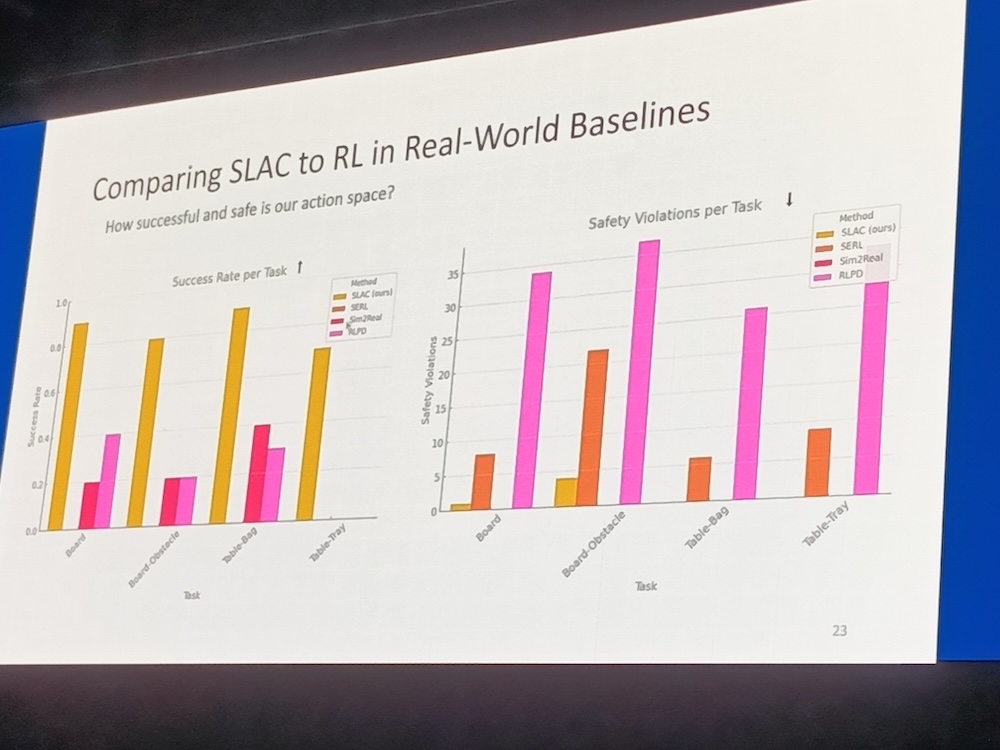
また、研究者らしくSLACと他の手法を比較したグラフを紹介し、SLACがSim2Realなどに比べて高い成功率を誇ることを示した。
次のトピックである「他のエージェントが存在する状況」についてはAd Hoc Teamworkという方法を紹介。複数のエージェントを評価してどのエージェントが補助の役目をするのか? を決める対話型の学習方法を説明した。例としてビーチサッカーを初見のメンバーと行うことを挙げて、人間が普段やっている行動をロボットに実装するという発想だ。

また、チームの中で誰と協調したら最も報酬が高くなるのかを同時に計算する研究を紹介。これはROTATEと呼ばれるフレームワークでArxivに論文が掲載されている。
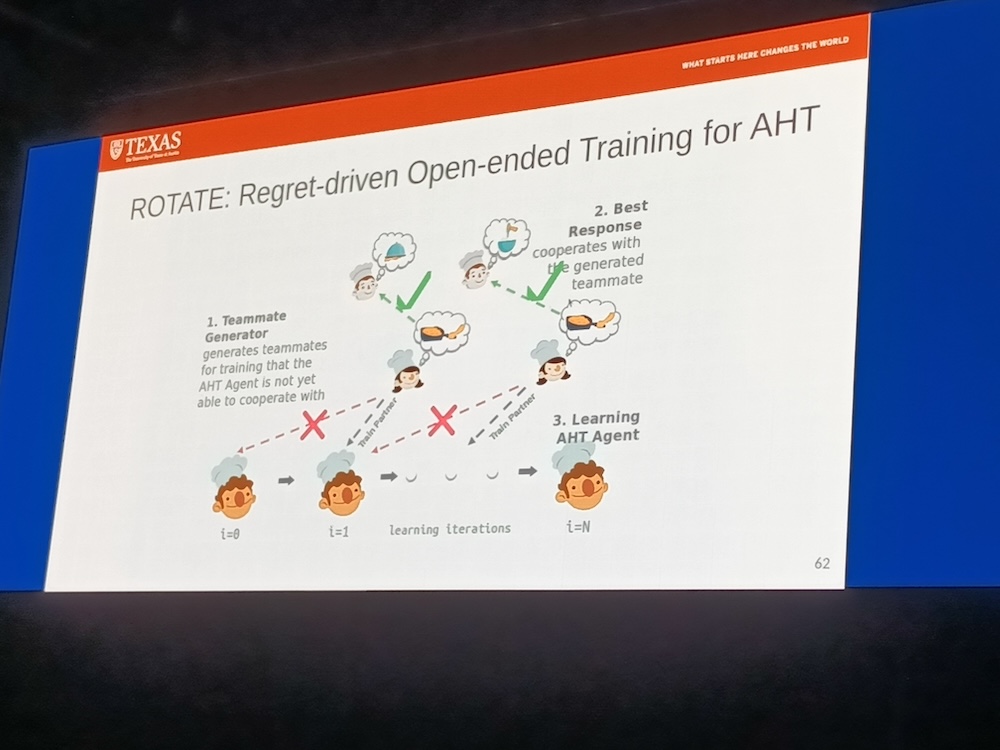
●参考:ROTATE: Regret-driven Open-ended Training for Ad Hoc Teamwork
最後のトピックとなる「人間と協調すること」についてはTAMERを紹介。ここでは人間がAIの動作を評価することで学習を改善するという発想だが、これは強化学習に人間のフィードバックを使うRLHF(Reinforced Learning Human Feedback)の最初の研究であると説明した。

自動運転においてロボットの操作が正しかったのかを乗っている人間の表情から評価するという手法も紹介し、言語や明示的な操作によって評価するよりも少ないコストで行える例を説明した。

まとめとして、再度4つのトピックを示して何を学ぶのか? の重要性を示した。Stone氏はロボティクスに特化して解説している。これをITインフラストラクチャーに移して考えれば、インフラストラクチャーの構成とオブザーバビリティの情報からシステムに何が起こっているのかをAIが認識した上で、最も報酬が高い最適な変更を行うという方向に応用できるだろう。現状の認識~最も報酬の高い動作の選択~動作の実施~変化の認識というループが可能になる。ただし現実の世界におけるロボットの動作と違うのはITインフラストラクチャーにおいては変更の結果が即座に現れずに他のソフトウェアに影響を与えた上で時間差を持って現れる可能性があることだろう。
最後に自身が所属するSony AIが公開したFHIBE(Fair Human-Centric Image Benchmark)を紹介。FHIBEは81カ国以上から同意を得て収集した1,981人の画像データを使ってAIモデルのバイアスを詳細に診断するためのデータセットである。今回のテーマとは直接関係しないがSony AIに対する貢献として宣伝する機会を最大限に使いたかったということだろう。

●参考:Sony AI
この講演の補助としては、2023年にMIT Technology Reviewで紹介されたインタビューが参考になるだろう。今回紹介された多くのトピックが日本語で紹介されている。
この記事をシェアしてください
関連記事
AAAI-26、ウェアラブル端末から医療データをAIに使うデバイス開発を解説するセッションを紹介
5月15日 6:00
ディープラーニング最前線2016レポート ~基調講演~
2016年3月10日 14:25
AAAI-26より、LLMに「忘れさせる」機能を研究しているセッションを紹介
5月8日 6:00
SIGGRAPH Asia 2025、Wayveの合成データによる強化学習に関するキーノートを紹介
4月13日 6:00
SIGGRAPH Asiaに参加した北大の小川教授にインタビュー。暗黙知をAIに実装する試みとは?
4月20日 6:30
【生成AIは組織の自立性を高めるのか?】ーTeslaとBYDに学ぶ未来型マネジメントー イベント参加レポート
2025年5月22日 6:30
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
