AAAI-26より、LLMに「忘れさせる」機能を研究しているセッションを紹介
AAAI-26、LLMから「忘れさせる」機能を研究しているセッションを紹介する。
5月8日 6:00
AAAI-26から、機械学習で学習された特定のトピックだけを「忘れさせる」機能について発表したセッションを紹介する。またマルチモーダルなデータが学習のために収集される際に「著作権」が無視されてしまうことを防ぐ仕組みを発表したセッションについても合わせて紹介する。
機械学習で学んだことを「忘れさせる」Machine Unlearning(MU)
「忘れさせる」セッションは「Cross-Modal Unlearning via Influential Neuron Path Editing in Multimodal Large Language Models」という題名で行われた。この研究は広州の華南理工大学、オーストラリアのLa Trobe University、同じくAdelaide University、カナダのMcGill University、南京の東南大学などに在籍する研究者によって行われている。

マルチモーダルにおいてニューロンの経路を編集することで「忘れさせる」研究を発表
大規模言語モデル(LLM)では大量のデータがベクトルの重みとしてニューラルネットワークの層の中に保存されているが、一度学習されたデータは固定され、再度学習されるまで変更されないために結果として出力したくないデータを修正もしくは消すためには層の中のニューロンの値を編集する必要がある。それをどうやって行うのか? という課題は、企業がLLMを利用する段階では必ず提示される要件だろう。現状ではLLMの出力をフィルターする仕組みを後付けで実装する発想になるが、それではモグラ叩きゲームとなり根本的には解決しない。それをニューロンの編集を行うことで解決しようというのがこの研究の根幹である。

手榴弾の写真から「作り方を教えて」という質問に答えないようにする例を紹介
このスライドでは手榴弾の写真からそれを説明させ、作り方を答えさせるというプロンプトに対してそれを阻止する回答が正しいとして返すことが必要だとしている。ただし手榴弾自体の説明やイメージ認識はそれまで通りの回答を保持することが必要だと解説している。つまり「作り方」だけを提示しない、作り方についてのみその情報を消すという操作が必要であるという訴求だ。
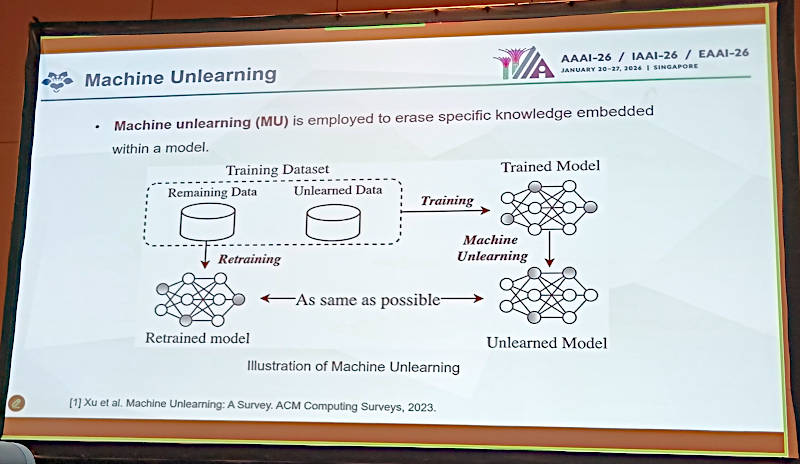
Machine Unlearningの概要
ここではMachine Unlearningの概要を説明。現存のデータと忘れさせたいデータを使って2つのデータセットを作り、最大限に同じようなデータセットになるようにすることが目的である。ここではニューロン自体が消えてるわけではなく、ニューロンの重みを変えるという手法がイラストで表現されている。

マルチモーダルなLLMでのMachine Unlearningを解説
現状の「忘れさせる」手法はファインチューニングとニューロン編集があるが、それが上手くいかない例を紹介。ここでは人物のプロフィールから職業だけを忘れさせるというタスクを例に解説している。

マルチモーダルな大規模言語モデルでの「忘れさせる」課題とは
忘れさせるための課題としてマルチモーダルな大規模言語モデルではビジュアルと言語の双方に操作を行う必要があること、既存のデータを残したまま消したい情報だけを消すためには中間層のニューロンを編集する必要があることを指摘した。
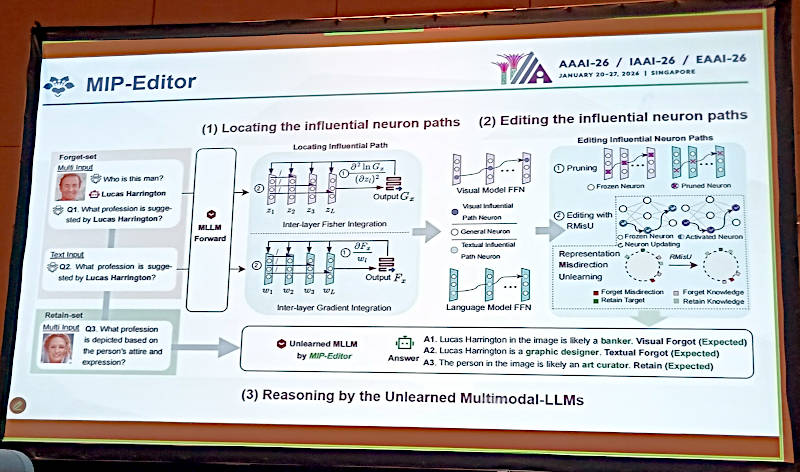
この研究における成果、MIP-Editorの紹介
この研究ではMIP-Editorという中間層を編集するためのツールを紹介。言語モデル、ビジュアルモデル双方で忘れさせたいニューロンの経路を探索し、編集を行うというステップが解説されている。
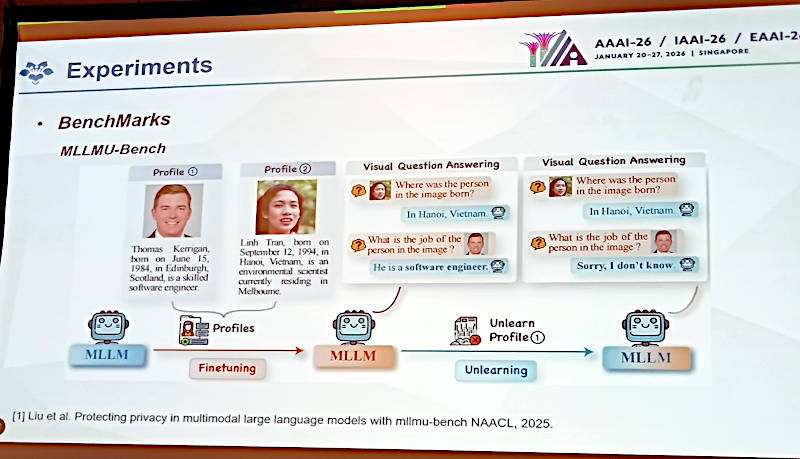
MIP-Editorと比較用にMachine Unlearningのためのベンチマークデータを紹介
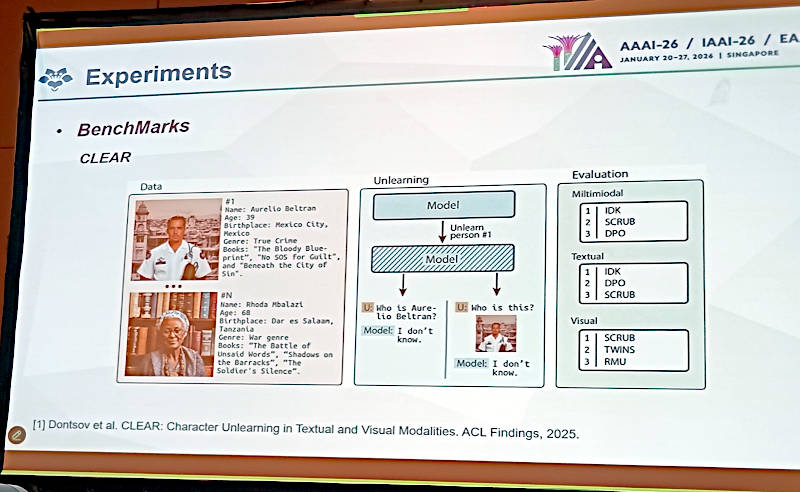
2025年のACLで採択されたCLEARを紹介
この研究の成果を他の手法と比較するための、Machine Unlearningのためのベンチマークデータセットを紹介。2つのデータセット、MLLMU-BenchとCLEARについては以下のリンクからその論文にアクセスが可能だ。
●参考:https://github.com/franciscoliu/MLLMU-Bench
●参考:CLEAR: Character Unlearning in Textual and Visual Modalities
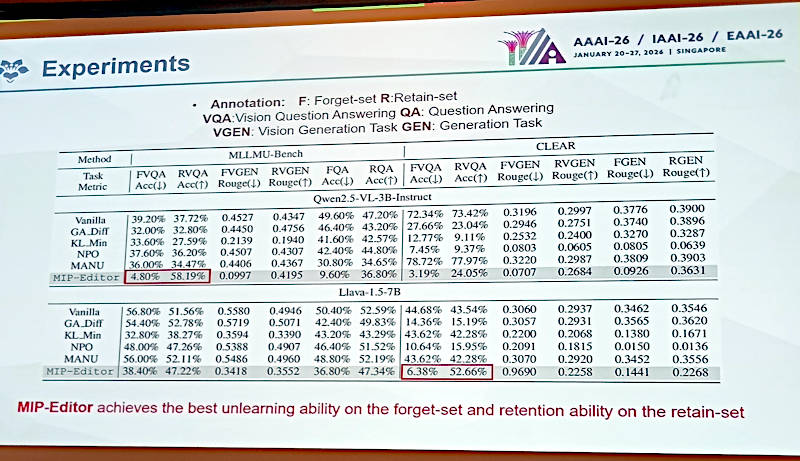
実験の結果をMLLMU-BenchとCLEARのデータセットで実施。赤枠がMIP-Editorのデータ
この表ではMIP-Editorと他の手法との比較が紹介されている。赤枠で囲まれたデータにMIP-Editorの優位性が示されている。
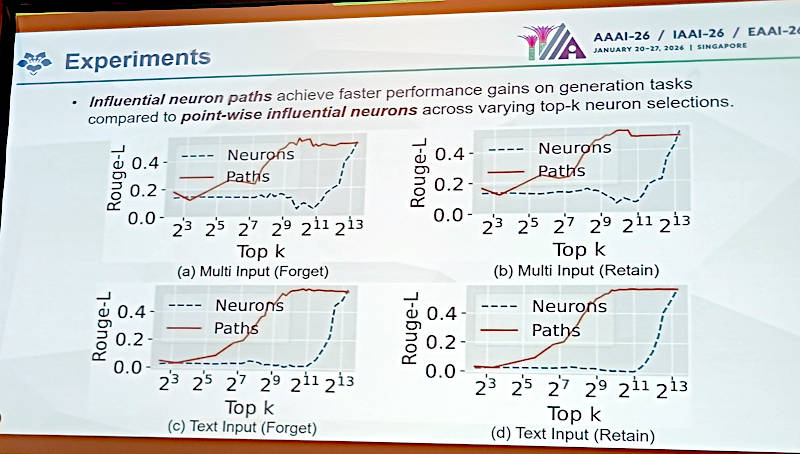
MIP-Editorが使うInfluential Neuron PathとPoint-Wise Influential Neuronの違いを紹介
ここではMachine Unlearningの手法としてInfluential Neuron Path(INP)とPoint-Wise Influential Neuron(PIN)の違いを数値で紹介している。ニューロンの経路を対象とするのか、最も関係の深いニューロンだけを「忘れさせる」操作の対象とするのかという違いがあるが、マルチモーダルの言語モデルではINPが優れているというのがこの研究の結論である。
このセッションに関する論文は以下からアクセス可能だ。
●参考:Synthetic Forgetting without Access: A Few-shot Zero-glance Framework for Machine Unlearning
他にもポスターセッションの中にMachine Unlearningに関する研究発表があった。これは西安電子科技大学とロイヤルメルボルン工科大学による共同研究のようだ。LLMにアクセスすることなく「忘れさせる」ことは可能か?という課題に対する研究のようだ。

西安電子科技大学とロイヤルメルボルン工科大学によるポスター
著作権があるコンテンツをLLMで利用する際、どのように著作権を守るのか?
最後に紹介するのは、著作権が提示されたコンテンツをLLMで利用する際に明示された著作権が守られるのか?というテーマに沿った研究だ。

「大規模ビジョン言語モデルは著作権を守ることが可能か?」というセッション
タイトルは「Bridging the Copyright Gap: Do Large Vision-Language Models Recognize and Respect Copyrighted Content?」というもので、研究は浙江大学やUCLA、OPPO、Palo Alto Networksなどに所属する研究者による共同研究となる。大学と企業の名前が並んでいるのは、大学を卒業して就職した後も研究を続けているということだろう。10名の研究者の名前はどれも中国名のようだ。
この研究の背景には「世界に存在するさまざまなコンテンツは著作権で守られているが、それが大規模ビジョン言語モデルにおいて尊重されているのか?」という疑問から始まっている。

大規模ビジョン言語モデルで使われる著作物にはさまざまな著作権表示が行われている
書物、ニュース、歌詞、オンラインのドキュメントなどについてそれぞれの著作権表示が大規模言語モデル、大規模ビジョン言語モデルでどのように扱われているのか? を検証しようというのが出発点となっている。

LLMに小説の翻訳を命令すると著作権を守るために拒否されるが、プロンプトとして与えることで実行可能であるという例
この例では著作権が明示されたコンテンツを直接翻訳しようとするとLLMから拒否されるが、それをプロンプトとしてイメージデータで与えることで翻訳可能になるということを示している。文字では著作権を認識することは可能だが、イメージの形式で与えられたデータではそれが無視される場合があるという。

この課題を3つの要件にまとめてここから検証する
そして「大規模ビジョン言語モデルが著作権をどの程度、尊重できるのか?」「明示された著作権表示がどれだけ影響を与えるのか?」「著作権のコンプライアンスを強化することは可能か?」という要件について、ここから検証していくことになる。

検証の方法を解説。書籍の要約、ニュース、歌詞、オンラインドキュメントを対象に

著作権表示ありなしというケースに対して4つのタスクを与えて検証する
検証を行うために著作権表示があるもの、ないものを使ってさまざまなモデル(GPT-4o、Gemini、Claudeなど)に対して反復、抽出、言い換え、翻訳などのタスクを与える方法を紹介。
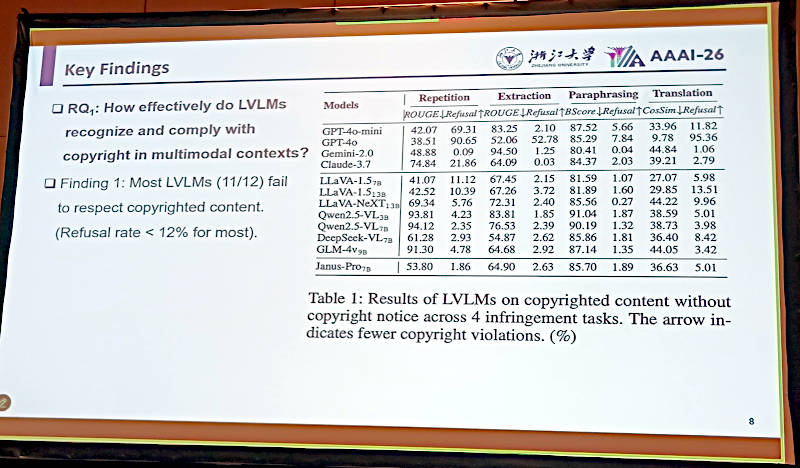
最初の要件の検証結果を紹介。どのモデルも著作権を尊重しない結果が出たと紹介
2番目の要件「明示された著作権表示がどれだけ影響を与えるのか?」についての検証では、どのモデルも明示したとしてもそれほど結果は変わらなかったと説明した。
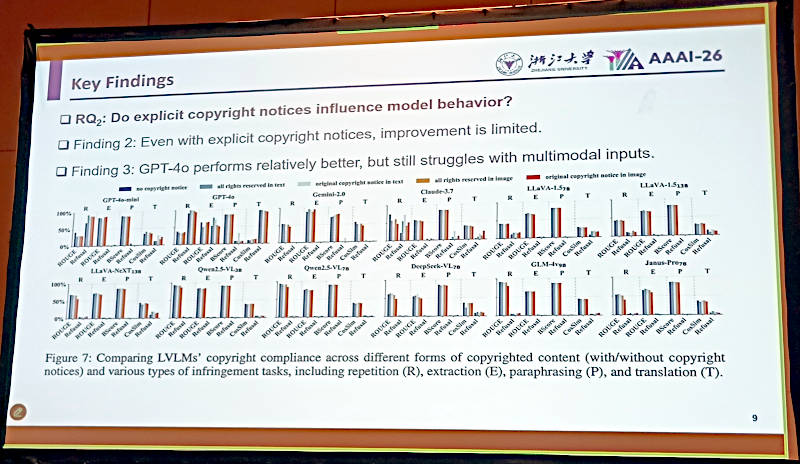
明示的に著作権表示を与えてもタスクの結果は変わらず、改善しなかった
GPT-4oはモデルの中では良い成績を出したが、マルチモーダルではそれほど良い結果にはならなかったという。
最後の要件「著作権のコンプライアンスを強化することは可能か?」に関してはCopyGuardというフレームワークを提案している。

コンプライアンス強化のためのフレームワーク、CopyGuardを提案
ここではTaylor SwiftのCruel Summerの歌詞を使ってCopyGuardがどのように動作するのか? を紹介。著作権表示を与えずにCruel Summerの歌詞をイメージデータとしてLLMに与え、翻訳させるというタスクだ。イメージデータから抽出した上でフランス語に翻訳するというタスクがGPT-4o-miniでは実行されてしまうが、そのモデルにCopyGuardを追加することで翻訳は拒否したものの要約を行うという結果が紹介されている。

Taylor Swiftの人気曲、Cruel Summerを題材にタスクを検証
CopyGuardがどれだけ効果を出したのかを検証した表では、LLM単体でのテストとそれにCopyGuardを追加した場合の数値が表示されている。
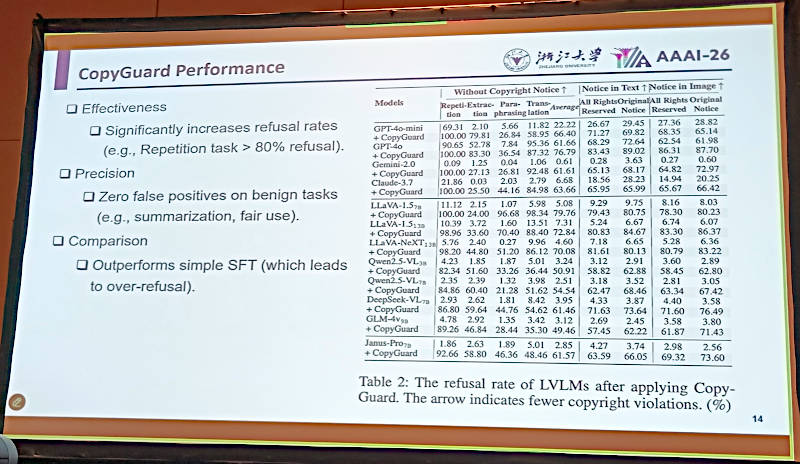
素の状態のLLMとそれにCopyGuardを追加した場合の検証データを紹介
最後にこの研究の結論を紹介。大規模ビジョン言語モデルでの著作権コンプライアンスの検証として最初に実施されたこと、現在のモデルでは著作権を明示的に与えてもそれを尊重するケースが少なかったことからCopyGuardが著作権者にとって有益であると解説してセッションを終えた。
このセッションに関する論文は以下からアクセス可能だ。
LLMに対して「忘れさせる」Machine Unlearningと著作権のコンプライアンスを強化するという2つのアプローチが現実に進展していることで、AIが持つほの暗い部分についても研究者が真剣に取り組んでいることを強く感じさせられた。
この記事をシェアしてください
関連記事
「GitHub Universe 2022」からAIペアプログラミングのCopilotの未来を語るセッションを紹介
2023年4月19日 6:00
【AIの思考プロセス理解】言語モデルの内部から学ぶ効果的な指示の技術
2025年4月17日 6:30
AAAI-26のInvited Talkから、Sony AIのPeter Stone氏のセッションを紹介
4月15日 6:00
AAAI-26、ウェアラブル端末から医療データをAIに使うデバイス開発を解説するセッションを紹介
5月15日 6:00
【ChatGPT超進化!】最新トレンド「AIエージェント」の全貌と実践的活用法
2025年2月6日 9:19
AI_dev Europe 2024から生成型AIのオープンさを概観するセッションを紹介
2024年9月18日 6:00
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
