障害や誤操作からデータを守る「MySQL」と「PostgreSQL」の「バックアップ・リカバリ」を理解する
第6回の今回は、「MySQL」と「PostgreSQL」の「バックアップ・リカバリ」について、論理/物理やホット/コールドなどの方式と設計の要点を比較しながら解説します。
6月23日 6:30
はじめに
この連載では、オープンソースのリレーショナル・データベース(RDB)の「MySQL」と「PostgreSQL」を使いこなすヒントを、両製品の共通点と違いを確認しながら解説していきます。
現在、それぞれの製品をベースとしたクラウド・データベースは複数存在しています。この連載では製品の比較を多く行いますが、製品機能や仕様の優劣についてを論ずる目的のものではないことはあらかじめご了承ください。
第6回の今回は、障害や誤操作からデータを守るうえで欠かせないMySQLとPostgreSQLの「バックアップ・リカバリ」に焦点を当てて整理していきます。
データベースにおける
バックアップの重要性を再確認する
データベースのバックアップは、単にデータをどこかへコピーしておく作業ではありません。システム障害、ストレージ故障、ソフトウェア不具合、操作ミスによるデータの誤削除や変更、アプリケーションのバグによるデータ破壊、さらにはランサムウェアなど社内外からの攻撃に備え、業務を再開できる状態をあらかじめ確保しておくための運用です。
バックアップを設計する際には「どのツールを使うか」だけではなく、「どの時点まで戻せるか」「どのくらいの時間で戻せるか」「バックアップ取得中に業務へどれだけ影響するか」を考える必要があります。一般的には、失っても許容できるデータ量を「RPO(Recovery Point Objective)」、復旧までに許容できる時間を「RTO(Recovery Time Objective)」と呼びます。例えば、「前日の夜間バックアップまで戻せれば良い」システムと、「障害直前の数分前まで戻したい」システムでは、必要なバックアップ方式が変わります。
バックアップの方式の比較
データベースのバックアップ方式を比較する際には、いくつか観点を分けて考える必要があります。MySQLとPostgreSQLでは利用できる機能やツールの名前は異なりますが、バックアップ設計で検討すべき軸は共通しています。
ここでは、以降の解説に入る前に、バックアップ方式を整理するための「3つの観点」を確認します。
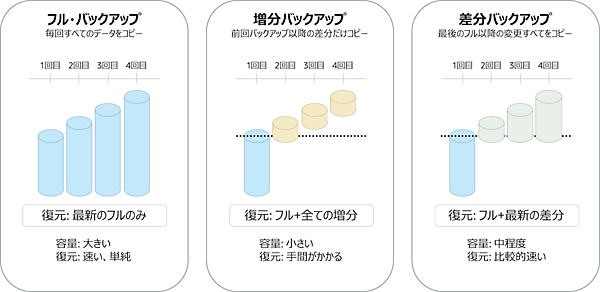
1つ目は「データの変更範囲をどのようにバックアップするか」です。この観点では、フル・バックアップ、増分バックアップ、差分バックアップに分類できます。なお、特定のスキーマやテーブルだけを対象にする部分バックアップは、取得対象の範囲に関する別の観点です。
- フル・バックアップ: データベース全体をバックアップ
- 増分/差分バックアップ: データに対する変更点をバックアップ
- 部分バックアップ: 特定のスキーマやテーブルのみをバックアップ
増分バックアップと差分バックアップの違いは、増分バックアップが全体かどうかにかかわらず、直近のバックアップ以降に更新されたデータを対象とするのに対して、差分バックアップは前回のフル・バックアップ以降に更新されたデータを全てバックアップします。
2つ目は「バックアップされたデータの形式」です。この観点では、以下の3つの方式に分類できます。
- 論理バックアップ: データベースの構造やデータをSQL文やテキスト形式として取り出す
- 物理バックアップ: データベースのデータファイルなどをコピーする方式
- ログ併用型: トランザクションが記録されたログを利用した継続的なバックアップ方式
このうち、ログ併用型は上記の増分/差分バックアップと関連しているケースが多くなっています。この内容については別途解説します。
3つ目は「バックアップ処理中のデータベースの稼働状態」です。
- ホット・バックアップ: データベースを稼働させたままバックアップを取得する方式
- コールド・バックアップ: データベースを停止してバックアップを取得する方式
また、この2つの中間的な方式をウォーム・バックアップと呼びます。
これら3つの観点は、互いに排他的な分類ではありません。例えば、論理バックアップでも稼働中に取得すればホット・バックアップといえますし、物理バックアップでもデータベース停止後にファイルをコピーすればコールド・バックアップになります。また、フル・バックアップを物理形式で取得し、その後の変更をログで補完する、といった組み合わせも一般的です。
したがって、バックアップ方式を選ぶ際には、「フルか増分か」「論理か物理か」「ホットかコールドか」を別々に考えたうえで、RPOやRTO、データ量、許容できる停止時間、復旧手順の複雑さに応じて組み合わせることが重要です。
以降では、この3つの観点を踏まえながら、MySQLとPostgreSQLで利用できる代表的なバックアップ機能を比較していきます。
取得するデータの形式による比較
論理バックアップは、テキストなど人間が中身を確認しやすい形式となるほか、特定のデータベース製品に依存しないCSVなどで出力できることもあり、異なるデータベース間での移植性が高いといえます。一方で、データ形式の変換が必要となるため処理の負荷が高めで、特に大規模なデータベースの復旧には非常に時間がかかることが多く、実用的ではありません。
これに対して、物理バックアップはデータファイルのコピーが基本となり、一部のメタデータの変更などがあったとしても復旧は相対的に大幅に高速です。ただし、同じデータベース製品でも異なるバージョンは復旧できないこともあるなど、環境面での制約は多くなります。また、データの一部分だけを復旧することは不可能か工夫が必要になってきます。
論理バックアップ
論理バックアップは、データベースの構造やデータをSQL文やテキスト形式として取り出す方式です。PostgreSQLではpg_dumpやpg_dumpallが代表的です。MySQLではこれまではmysqldumpが広く利用されてきましたが、現在はMySQL Shellのダンプ・ユーティリティが高機能なツールとして選択肢に加わっています。いずれのツールも対象のデータベース・サーバーに接続してバックアップの処理を行うため、サーバーが稼働していることが前提条件になります。
論理バックアップの利点は、取得したファイルの中身を確認しやすく、別の環境へ移行しやすいことです。テーブル単位やデータベース単位で取り出しやすく、開発環境へのデータ移送や、メジャー・バージョン・アップ時の移行にも利用できます。MySQLのドキュメントでも、論理バックアップはデータ構造と内容を保存し、別のマシン・アーキテクチャ上でデータを再作成する用途に向くと説明されています。一方で、データ量が増えるとリストアに時間がかかりやすい点が大きな弱点です。
MySQL Shellのダンプ・ユーティリティには、次の3種類が用意されています。
- インスタンス全体を対象とする
util.dumpInstance() - 指定したスキーマを対象とする
util.dumpSchemas() - 指定したテーブルやビューを対象とする
util.dumpTables()
これらで出力したダンプは、同じMySQL Shellのユーティリティであるutil.loadDump()でMySQL HeatWaveまたはMySQLサーバーへロードできます。
デフォルトではSQL形式のスクリプトとして出力するmysqldumpとは異なり、MySQL Shellのダンプ・ユーティリティではスキーマ定義を表すDDLファイルと、データを含むタブ区切りの.tsvファイルで構成され、必要に応じてDDLのみ、またはデータのみを出力できます。デフォルトでは、テーブルデータは複数ファイルに分割され、圧縮も行われます。
ダンプ処理の進捗が表示されるのも改良点です。また複数スレッドによる並列ダンプ、およびutil.loadDump()での並列ロードが可能なため、バックアップと復旧の時間の短縮が見込めます。
ダンプ・ユーティリティの制約は、トランザクションの整合性が担保されるのは対象のテーブルが全てInnoDBストレージ・エンジンを利用している場合に限られます。mysqldumpでの--lock-all-tablesオプションに該当するオプションなどは用意されていません。
また、必要となる権限もテーブルの参照権限だけではないため、マニュアルに記載された要件を確認することが求められます。
mysqldumpは小規模データの手軽なSQL形式でのバックアップ、ダンプ・ユーティリティはより大きなデータの並列バックアップ、といった使い分けができます。
PostgreSQLでは、1つのデータベースを対象とするpg_dump、クラスタ全体を対象としロールや表領域などのクラスタ全体の情報も扱うpg_dumpallが用意されています。
pg_dumpは通常のクライアント・アプリケーションとして動作するため、接続権限と対象オブジェクトへの読み取り権限が必要です。テーブル単位、データのみ、定義のみなど柔軟なバックアップの取得が可能です。また、デフォルトではSQL文の形式でダンプします。オプションによってカスタム形式と呼ばれるPostgreSQL独自の圧縮されたファイルや、テーブルおよびBLOBなどのラージ・オブジェクトごとに1つのファイルとして全体をディレクトリ構造で出力するディレクトリ形式、ディレクトリ形式をtarでまとめた形式などが選択できます。
SQL文の形式でダンプされたファイルはPostgreSQLのクライアントであるpsqlに読み込ませることでリストアできます。それ以外の形式の場合はpg_restoreを利用します。pg_restoreでは--tableオプションで選択したテーブルのみのリストアも可能となっています。
pg_dumpallは全てのPostgreSQLデータベースをまとめてダンプするユーティリティです。複数のデータベースがある場合にはそれぞれに接続し、各データベースに対して内部でpg_dumpを実行する形となっています。
ロールや表領域のようなクラスタ全体の情報をバックアップするにはpg_dumpallが必要となり、pg_dumpallの実行は基本的にスーパーユーザーを使うことになっています。なお、pg_dumpallはpg_dumpとは異なり出力形式の選択はできず、SQL文が格納された1つのスクリプトファイルに書き出す形となっています。
物理バックアップ
物理バックアップは、基本的にはデータベースのデータファイルそのものをコピーする方式です。最もシンプルな方法は、ファイルシステム・レベルでデータ・ファイルをコピーすることです。ただし、物理バックアップはデータベース内部の整合性を保った状態で取得する必要があります。
データベース・サーバーが停止していれば、データが変更されることもないためデータの整合性が崩れることを気にする必要はありません。しかし、サーバーが稼働している状態では、実行されるトランザクションによるデータの変更との競合を考慮する必要があります。
MySQLでは商用版のMySQL Enterprise Editionで提供されるMySQL Enterprise Backup(MEB)がサーバー稼働中の物理バックアップに利用できます。PostgreSQLではpg_basebackupやpg_rmanが利用できます。
MEBはコマンドライン・ツールで、mysqlbackupが実行ファイルです。実行時にはサブコマンドで具体的な操作を指示します。
MEBは2段階のバックアップを行います。まずMySQLのデータファイルをコピーし、コピー中に発生した変更点をログとして記録します。サブコマンドでbackupまたはbackup-to-imageを使用した場合はこの2段階の操作のみ行います。
前者はデータ・ディレクトリの構造でバックアップを行い、後者は1つのファイルにバックアップをまとめます。MEBのマニュアルでは、ファイルの扱いやすさやクラウド・ストレージをバックアップ先にできることなどを理由に後者の利用を推奨しています。
backup-and-apply-logは2段階の操作後変更点を記録したログの内容をバックアップされたデータに反映して、バックアップ終了時点のデータとする操作です。一方、増分バックアップを取得する場合は、backupまたはbackup-to-imageに増分バックアップ用のオプションを組み合わせます。backup-and-apply-logは増分バックアップには使用できない点に注意が必要です。また、--incrementalオプションを指定すると、増分バックアップを実行できます。
# 1つのファイルにバックアップをまとめる場合
mysqlbackup --defaults-file=/home/dbadmin/my.cnf --backup-image=/backups/sales.mbi --backup-dir=/backup-tmp backup-to-imageMEBで復旧するにはcopy-backやcopy-back-and-apply-logサブコマンドを使用します。バックアップされたデータにログが適用され、データが最新化されているかによって利用するサブコマンドの組み合わせが決まります。
| バックアップ | 復旧 |
backupまたはbackup-to-image | copy-back-and-apply-log |
backup-and-apply-log | copy-back |
PostgreSQLの物理バックアップのための標準ツールであるpg_basebackupは、PostgreSQL本体に含まれています。稼働中のPostgreSQLからフル・バックアップであるベース・バックアップを取得できます。また、PostgreSQL 17からはフル・バックアップに加えて増分バックアップも取得できるようになっています。
なお、増分バックアップはそのままでは復旧には利用できず、pg_combinebackupで過去のバックアップと結合する必要があります。復旧時には、PostgreSQLを停止した上でデータ・ディレクトリをリネーム等で退避し、バックアップしたファイルで置き換える流れとなります。
pg_rmanはPostgreSQL向けの外部バックアップ管理ツールで、物理オンライン・バックアップ、増分バックアップ、バックアップカタログによる世代管理、検証、削除、リストアをまとめて扱えます。標準のpg_basebackupがベース・バックアップ取得の基本機能であるのに対し、pg_rmanはバックアップ運用全体を管理するためのツールと位置づけられます。バックアップ世代やアーカイブWALを含めた運用管理をツールに任せたい場合はpg_rmanが候補になります。
| 観点 | pg_basebackup | pg_rman |
| 位置づけ | PostgreSQL標準ツール | 外部ツール |
| 主な目的 | ベース・バックアップ取得、PITRやスタンバイ構築の起点 | 物理バックアップ運用全体の管理 |
| 対象 | クラスタ全体 | クラスタ全体、アーカイブWAL、サーバーログ |
| 増分バックアップ | PostgreSQL 17で対応。pg_combinebackupで結合が必要 | 増分バックアップに対応 |
| 世代管理 | 基本的には利用者側で管理 | バックアップ・カタログで管理 |
| 検証 | pg_verifybackupを利用 | validateコマンドを利用。未検証バックアップは利用不可 |
| リストア支援 | 取得したバックアップを手順に従って配置・復旧 | restoreコマンドで復旧処理を支援 |
| 向いている用途 | 標準機能でシンプルにベース・バックアップを取りたい場合 | 世代管理や検証、増分、WAL管理まで含めて運用したい場合 |
ログを利用した継続的なバックアップと
ポイント・イン・タイム・リカバリ
バックアップは、ある時点のスナップショットを取るだけでは不十分な場合があります。例えば、深夜0時にバックアップを取得し、翌日15時に障害が発生した場合、深夜0時時点に戻すだけでは15時間分の更新が失われます。
そこで重要になるのが、ログを利用した差分の保存と、任意の時点まで戻すポイント・イン・タイム・リカバリ(PITR / Point-in-Time Recovery)です。
MySQLでは、バイナリログを利用してバックアップ取得後に発生した変更を追跡できます。PostgreSQLでは、ベースバックアップとWALアーカイブを組み合わせることで継続的アーカイブとPITRを実現します。
MySQLでポイント・イン・タイム・リカバリを行うには、フル・バックアップとバイナリログを組み合わせます。まずフル・バックアップを取得し、その後に発生した更新をバイナリログとして保持します。復旧時には、バックアップを戻したあと、必要な位置または時刻までバイナリログを適用します。MySQLのマニュアルでは「増分バックアップはバイナリログを有効化して実現し、復元時にはそれらのバイナリログを適用する」と説明されています。
PostgreSQLでは、ベース・バックアップとWALアーカイブを組み合わせます。WALはデータ変更の履歴を記録するログで、継続的に保存しておくことでベースバックアップ取得後の任意の時点まで復元できます。PostgreSQLの継続的アーカイブでは、ベース・バックアップに加えて、バックアップ開始時点までさかのぼれる連続したWALファイルが必要です。
この領域で重要なのは、MySQLでもPostgreSQLでも「ログだけではリカバリできない」という点です。ログはあくまで、ある時点のフル・バックアップやベース・バックアップに対して、その後の変更を適用するためのものです。したがって、ポイント・イン・タイム・リカバリを実現するには、定期的なフル・バックアップとログの継続保存を組み合わせて設計する必要があります。
レプリケーションを使ったバックアップ取得
本番サーバーへの負荷を抑えるために、レプリケーションを利用してレプリカからバックアップを取得する構成もよく使われます。PostgreSQLでもpg_basebackupはプライマリだけでなくスタンバイから取得できます。
ただし、スタンバイから取得する場合にはスタンバイ側でレプリケーション接続を受けられるように設定しておく必要があり、プライマリ側のfull_page_writesなどの前提も確認が必要です。
レプリカからバックアップを取る場合も、レプリカ遅延やレプリケーション構成情報の扱いに注意が必要です。MySQLのマニュアルでは「レプリカをバックアップする場合には、復元後にレプリケーションを再開するため、接続メタデータや適用メタデータもバックアップすべきだ」と説明されています。
なお、レプリケーションはプライマリ側の変更をレプリカへ反映する仕組みであるため、誤削除や誤更新のような論理的な破壊も伝播します。そのため、レプリカは可用性向上やバックアップ取得元としては有用ですが、過去の時点へ戻すためのバックアップの代替にはなりません。「レプリカをバックアップとして扱う」運用は避けるようにしましょう。
データベースの稼働状態による比較
データベースを稼働させたまま取得するか、停止して取得するかという観点でも分類できます。この観点でよく使われるのが、ホット・バックアップとコールド・バックアップです。
ホット・バックアップは、データベースを稼働させたまま取得するバックアップです。サービス停止を伴わない、または停止時間を最小限にできるため、本番環境では重要な方式です。ただし、バックアップ取得中にも更新処理が行われるため、データベースとして一貫性のある状態を保つ仕組みが必要になります。MySQL Enterprise Backupでは、データベース稼働中に取得するバックアップがホット・バックアップとして整理されており、InnoDB中心の環境でサービスへの影響を抑えてバックアップを取得できます。
コールド・バックアップは、データベースを停止した状態で取得するバックアップです。サーバーが停止しているため、データ・ファイルの整合性を保ちやすく、方式としては単純です。一方で、バックアップ取得中はデータベースを利用できないため、停止時間を許容できるシステムや、メンテナンス時間帯を確保できる環境で使われます。PostgreSQLのファイルシステム・レベルでのバックアップでは「有効なバックアップを取得するには原則としてデータベース・サーバーを停止する必要がある」と説明されています。ただし、ファイルシステムが整合性のあるスナップショットを正しく取得できる場合は、稼働中のバックアップも選択肢になります。
この2つ以外に、ホットとコールドの間ということで「熱くも冷たくもなく温かい」という意味でウォーム(Warm)・バックアップと呼ばれる方式も存在します。データベース・サーバーは稼働中ではあるものの、データの変更によりバックアップ・データの不整合が起こることを防ぐため、一部の処理に制約やロックが入る方式となります。
| 方式 | 概要 | MySQLの例 | PostgreSQLの例 | 向いている用途 |
| ホット・バックアップ | データベースを稼働させたまま取得 | 物理: MySQL Enterprise Backup 論理: mysqldump --single-transaction | 物理: pg_basebackup、pg_rman論理: pg_dumpその他: WALアーカイブ | 本番環境、停止時間を短くしたいシステム |
| ウォーム・バックアップ | DBは稼働しているが、一部処理に制約やロックが入る | 物理: MySQL Enterprise Backupで一部ストレージ・エンジンや操作に制約があるケース 論理: mysqldump --lock-all-tables | 物理: ファイルシステムのスナップショット前後に短時間の制御を入れる構成など | 停止は避けたいが、一時的な制約は許容できる環境 |
| コールド・バックアップ | データベースを停止して取得 | 物理: MySQL停止後のデータ・ディレクトリのコピー | 物理: PostgreSQL停止後のデータ・ディレクトリのコピー | 小規模環境、保守時間を確保できる環境、単純な復旧手順を優先する場合 |
バックアップ設計で確認すべきポイント
バックアップ方式を選ぶ際には、次の観点を整理しておく必要があります。
第1に「復旧単位」です。テーブル単位で戻したいのか、スキーマやデータベース単位なのか、クラスタ全体なのかによって、適する方式は変わります。論理バックアップは部分的な取り出しに向きますが、物理バックアップは基本的にインスタンスやクラスタ全体の復旧に向きます。
第2に「RPOとRTO」です。1日1回のバックアップで良いのか、数分前まで戻す必要があるのか、復旧に数時間かけられるのか、数十分以内に戻す必要があるのかを決めます。RPOを短くしたい場合は、ポイント・イン・タイム・リカバリのためにMySQLではバイナリログ、PostgreSQLではWALアーカイブを組み合わせる必要があります。
第3に「バックアップ取得時の業務影響」です。ホット・バックアップやレプリカからのバックアップを活用すれば、本番のワークロードへの影響を抑えられます。ただし、バックアップ処理自体はI/OやCPUを消費するため、取得時間帯、保存先、圧縮の有無、ネットワーク転送量を考慮する必要があります。
第4に「バックアップの保護」です。バックアップには本番データと同じ、場合によってはそれ以上の機密情報が含まれます。第3回で扱ったデータ暗号化と同様、バックアップ・ファイルの暗号化、アクセス制御、保存先の分離、不要になった世代の削除は重要です。第2回でも、NIST CSFの復旧やデータ保護の観点から、バックアップ暗号化が検討項目に含まれると整理しています。
第5に「復旧試験」です。バックアップは取得しただけでは意味がありません。実際に復元できること、必要な時点まで戻せること、復元後にアプリケーションが動作することを定期的に確認する必要があります。特にポイント・イン・タイム・リカバリは、ベース・バックアップとログの両方がそろってはじめて成立するため、運用手順の訓練が不可欠です。
まとめ
今回は、MySQLとPostgreSQLのバックアップとリカバリについて、方式ごとの考え方と代表的な機能を比較しました。論理バックアップは扱いやすく移行性に優れ、物理バックアップは大規模環境の短時間復旧に向きます。さらに、MySQLのバイナリログやPostgreSQLのWALアーカイブを組み合わせることで、障害直前に近い時点まで戻すポイント・イン・タイム・リカバリも実現できます。
重要なのは「どれか1つの方式を選べば十分」ということではありません。多くの本番環境では、日常的な論理バックアップ、定期的な物理バックアップ、ログを使った継続的なリカバリ手段を組み合わせることもあります。バックアップは取得することが目的ではなく、必要な時に、必要な時点へ、確実に戻せることが目的です。
次回は、バックアップやリカバリとも密接に関わる可用性設計やレプリケーション構成について解説していきます。
この記事をシェアしてください
関連記事
[DBA] バックアップおよびリカバリ
2017年4月4日 1:05
【CNDS2025】つくって壊して直して学ぶDB on Kubernetesの実践で見つけた、PostgreSQL運用の勘所
2025年8月7日 6:00
row-level security controlとpg_rewindの実装
2016年6月7日 0:00
MySQL Clusterにおけるレプリケーション環境構築例
2015年11月19日 7:00
「MySQL」と「PostgreSQL」のセキュリティ機能を比較する
1月21日 6:30
Apache Kuduのシステム構成と内部アーキテクチャ
2019年4月17日 6:30
バックナンバー
この記事の筆者
筆者の人気記事
「MySQL」と「PostgreSQL」を安全に使い続けるための「バージョン管理」を理解する
5月20日 6:30
「MySQL」と「PostgreSQL」の「データの暗号化」機能を比較する
2月19日 8:40
「MySQL」と「PostgreSQL」の基本的な情報と導入方法
2025年12月16日 6:30
「MySQL」と「PostgreSQL」のセキュリティ機能を比較する
1月21日 6:30
「MySQL」と「PostgreSQL」の各種セキュリティ要件への対応を比較する
4月16日 5:00
障害や誤操作からデータを守る「MySQL」と「PostgreSQL」の「バックアップ・リカバリ」を理解する
6月23日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
