TopHatenarのデータベース構造
TopHatenarのデータベース構造
TopHatenarとHatenarMapsは、データベースとして、パフォーマンスに定評のあるMySQLを使用しています。また、テーブルのストレージエンジンにはInnoDBを選択しています。アプリケーションの機能がシンプルであることから、そのデータベース構造もまた、非常に簡潔なものとなっています。
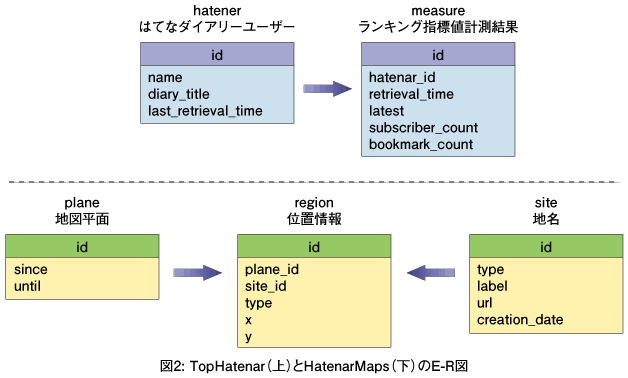
TopHatenarが扱うテーブルは、はてなダイアリーユーザーを示すhatenarテーブルと、ランキングの指標値となるフィード購読者数とブックマーク数を記録するmeasureテーブルの2つです。
hatenarテーブルとmeasureテーブルは、1対多の関係にあります。時間の経過とともに、クローラの情報収集が進行し、measureレコードが時系列に沿って蓄積されていきます。したがって、TopHatenarは、現時点のユーザーランキングを計算するだけでなく、任意のユーザーについて、過去から現在に至る購読者数とブックマーク数の推移を求めることができます。
2008年6月現在、hatenarテーブルの行数は約6万です。つまり、計測対象のはてなダイアリーユーザー数はおよそ6万人ということになります。仮に1人のユーザーにつき、1日1回のペースで指標値の計測を行い、その度にmeasureテーブルに新規レコードを挿入するとすれば、measureテーブルの行数は、1年間で実に2190万にも達してしまいます。このようなテーブルの肥大化を防ぐために、TopHatenarでは、ブログユーザーの「ロングテール性」に着目し、若干の工夫を施しています。
TopHatenarで実際に調べてみると分かりますが、購読者数や被ブックマーク数が頻繁に変動するユーザーの層は、実はごく一部に限られており、大半のユーザーの計測値は長期間にわたって変化しません。そこで、指標値を計測する際に、前回の計測結果から変化がなかったユーザーの記録を省略することで、レコードの増加率を大幅に抑えることができるのです。
HatenarMapsのデータベース構造
次に、HatenarMapsのデータベース構造について説明します。
HatenarMapsは、キーワードの入力や地図上でのマウスのダブルクリックによって、特定のブロガーや記事に対応する地図中のスポットを検索できる機能を持っています。この機能を実現するために、3つのテーブルが用意されています。planeテーブルとsiteテーブル、そしてregionテーブルです。
planeテーブルは、「全期間の地図」「2007年上半期までの地図」といった、異なる基準に基づく1つ1つの地図平面を表すテーブルです。また、siteテーブルは、ブロガーのユーザー名や記事のタイトルといった、HatenarMaps上での「地名」を表すテーブルです。
そしてregionテーブルは、各地名に対応する座標データを保持しています。領土の配置は、地図平面の種類に応じて変わりますので、planeレコードとsiteレコードの各組み合わせに対し、別々のregionレコードが必要です。したがって、regionテーブルは、planeテーブルとsiteテーブルに対して、それぞれ多対1の関係を持つことになります。
- この記事のキーワード
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
