| ||||||||||||
| 1 2 3 次のページ | ||||||||||||
| はじめに | ||||||||||||
前回に引き続きデータベースのスケールアウトについて解説します。今回はデータを分割するメリットと、その実現性について検討します。 | ||||||||||||
| 分割すると何がうれしいのか? | ||||||||||||
さてデータを分割すると、特定のサーバで膨大なデータを一手に読み書きする必要はなくなります。 一方、図1に示すように、このままではSQLの処理を行う際には、すべてのデータをいったんSQLの処理をするサーバに送らなければならなくなります。 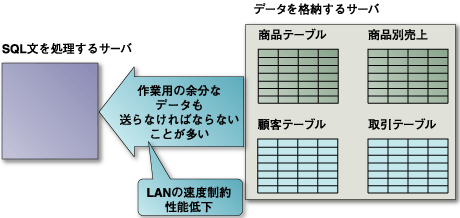 図1:データだけを分割した場合 そこで、SQLの処理の内部構造に着目してみます。この内部構造を非常に単純にモデル化したものを図2に示します。 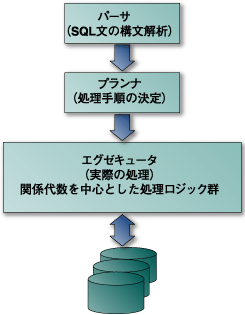 図2:SQL文の処理の流れの概要 SQLの結果を受け取るデータはわずかでも、何百万何千万のレコードから必要なデータを持ってくるために、エグゼキュータでは作業の多くのデータをディスクから読み書きする必要があります。これが、SQLの処理で最も時間がかかる部分になります。 この効率を上げるために、図2のプランナとエグゼキュータの間で処理を分け、図3のように、SQL処理部にはパーサとプランナを置き、エグゼキュータはデータを格納しているサーバで実行するようにできます。 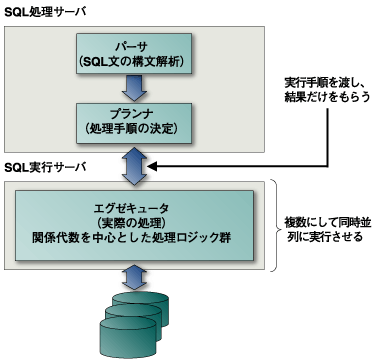 図3:SQL実行部を2つに分ける つまり複雑な実行手順を多くのサーバのCPUに分け、それぞれが扱うデータを小さくし、それが並列に実行できるようになるのです。 SQL処理側では、これらの結果を集め、最終的な結果にまとめればよくなります。このように、「大きなSQLを小さくし、それらを同時に実行する」ことができるのです。 このような並列分散データベースは、多くの可能性を持っています。現在でも1TBのデータベースを作るのは非常に困難です。これを数10台のサーバに分割できれば、1台のサーバでは数10GBのデータを管理すればよくなるのです。 現在のディスクデバイスの容量が数100GBであることを考えると、これは不思議な気がしますが、単位容量あたりのデータの転送速度はたいへん遅いのです。 データベースに課せられた性能要件は、データベース全体から必要なデータを迅速に見つけ、アプリケーションに渡すこと、アプリケーションから指示されたデータベースのデータ変更を迅速に行うことであり、数にすると毎秒数千のSQL文を処理することに相当します。 しかし、いくらがんばっても1秒の間にディスクが読み書きできるデータの量は100MBのオーダーであって、例えば1TBのデータベース全体を集計しようとすると、データを読むだけで3時間もかかってしまうことになります。 バックオフィスなどで、普段使用するテキストなどを格納するのに大容量のディスクは大変便利ですが、だからといってデータベースの容量をそのまま大きくできるわけではないのです。 実際には、データベースの処理はディスクの入出力以外にも、トランザクション(後述参照)の処理に多大な時間がかかるので、1TBのデータを3時間で読むことすらも、実現には程遠い理想的な性能なのです。 データ格納の単位を小さくして、必要な処理の規模が大きくならないようにすることが重要であることがおわかりいただけると思います。 | ||||||||||||
| 1 2 3 次のページ | ||||||||||||
| ||||||||||||
| ||||||||||||
| ||||||||||||
-
人気記事ランキング
-
-
連載


新着記事
「Proxmox VE」とは? 製品群の全体像と仮想化基盤として注目される理由 7月31日 6:30 LFがOSSの脆弱性協調対応イニシアティブ「Akrites」を発足、CRA準備状況レポートは改善どころか悪化、ほか 7月31日 6:20 NVIDIAら37社が「Open Secure AI Alliance」設立――AIエージェントのセキュリティは重みの非公開では守れない 7月30日 6:20 【クラウドネイティブ会議】厳格な統制と開発者体験を両立する、Wiz Baseにおけるゴールデンパスの実践 7月30日 6:00 その「ソーシャルログイン」は大丈夫? OAuth/OIDC実装の3つの落とし穴 7月29日 6:30