本連載では、実際に「MySQL Cluster」を利用するためのチュートリアルとなるように、その特徴と基本的なアーキテクチャからインストール方法、基本的な操作などをコマンド付きで解説していきます。第7回の今回は、MySQL Clusterにおけるレプリケーションのメリットや仕組み、注意事項について解説します。
前提となる環境
記事中のコマンド例は、第2回でインストールした環境に第5回で紹介したサンプルデータベース(worldデータベース)を作成した状態を前提としています(追加設定としてmysqlユーザーの環境変数"PATH"に"/home/mysql/mysqlc/bin"も追加した状態を前提)。
レプリケーションのメリットと主な用途
MySQL Clusterでは、通常のMySQL Serverと同様の仕組みでマスターからスレーブへバイナリログを転送してレプリケーションを構築できるため、MySQL Serverのレプリケーション運用ノウハウを活かせます。また、MySQL ClusterからMySQL Clusterへレプリケーションするだけでなく、MySQL Clusterから通常のMySQL Serverへレプリケーションを行なうこともできます。
MySQL Clusterでレプリケーションを使用する主な用途は、次の通りです。
- ディザスタリカバリサイトを構築する(MySQL ClusterからMySQL Clusterへのレプリケーション)
- MySQL Clusterが苦手なクエリをMySQL Serverで処理する(MySQL ClusterからMySQL Serverへのレプリケーション)
ディザスタリカバリサイトを構築する
例えば東京と大阪のような地理的に離れた場所にそれぞれMySQL Clusterを構成し、それらをレプリケーションで連携することで実現できます。
MySQL Clusterが苦手なクエリをMySQL Serverで処理する
通常のMySQL Serverと比べた場合にMySQL Clusterが苦手なクエリとは、範囲検索やテーブルの全件データを検索するようなスキャン系の処理、複数テーブルを結合するJOIN処理です。MySQL Clusterは内部で自動的にデータをシャーディング(分割して複数のサーバーに分散)しているため、クエリの実行結果を返すノード間のネットワーク通信時間もレスポンスタイムに影響を与える要因となります。そしてスキャン系の処理やJOIN処理を実行した場合は、SQLノードが複数のデータノードと通信したり、データノード間で通信したりする必要があるため、1件だけデータを取り出す処理と比べてネットワーク通信時間がレスポンスタイムに与える影響が大きくなります。また、多重処理を実行する環境ではノード間のデータ処理がネットワーク帯域を圧迫してしまい、ボトルネックとなるケースもあります。
そこでMySQL ClusterからMySQL Serverにレプリケーションを構成し、このようなクエリをMySQL Serverで処理することで、それぞれのノード間でのネットワーク通信時間に依存したレスポンスタイムの悪化を改善したり、ネットワーク帯域の圧迫によるボトルネック発生を防いだりできるようになります。
MySQL Clusterのレプリケーションの仕組み
前述したように、MySQL ClusterのレプリケーションにはMySQL Serverのレプリケーション運用ノウハウを活かせますが、MySQL Cluster固有の仕組みや注意事項もあります。
MySQL Clusterのバイナリログ出力
バイナリログはデータベースの更新内容を記録しているログファイルです。通常のMySQL Serverでデータベースを更新できるのはMySQL Serverが稼働しているサーバー1台だけですが、MySQL Cluster環境では複数のSQLノードがあり、それぞれのSQLノードからデータベースを更新できるため、バイナリログを出力しているSQLノードは自ノード以外で実行した更新内容もバイナリログに記録する必要があります。
そのための仕組みが「Binlog Injector」と呼ばれる、通常のMySQL ServerにはないMySQL ClusterのSQLノード固有のスレッドです。MySQL Clusterを構成しているSQLノードでバイナリログを出力すると、そのSQLノード上にあるBinlog Injectorスレッドがデータノードでの更新内容を受け取り、直列化(Epochでソート)してバイナリログに書き込みます(図1)。
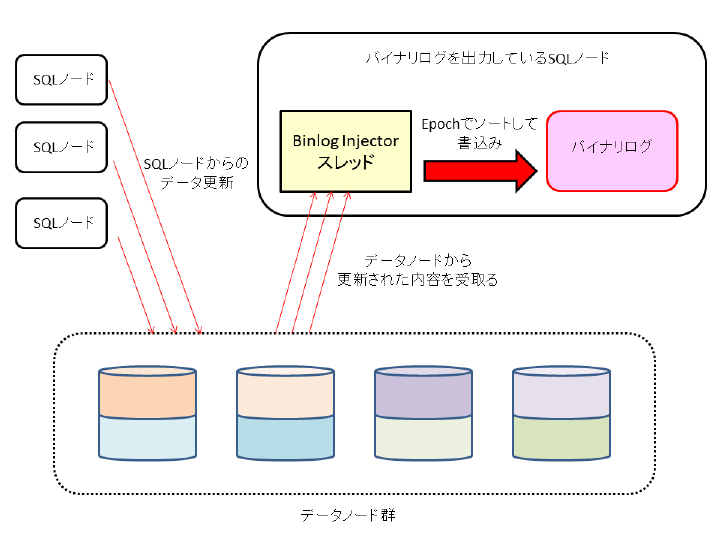
第4回で解説したように、同じEpochの更新内容は同じ時間帯に更新された内容となるため、Epochでソートしてバイナリログに書き込むことで、スレーブにレプリケーションした際も同じ内容(順番)でデータを更新できます。
Epochとの対応を記録しているテーブル(表1)
MySQL Clusterのレプリケーションでは、Epochを基準にバイナリログのファイル名やポジションを判断するケースがあります。その際に参照するEpochとの対応を記録しているテーブルがndb_binlog_indexです。また、スレーブ側でバイナリログの内容をどこまで(どのEpochまで)反映しているかを記録するテーブルがndb_apply_statusです。いずれもmysqlデータベース内のテーブルです。
表1: Epochとの対応を記録しているテーブル
| 名称 | 存在場所 | ストレージエンジン | 内容 |
|---|---|---|---|
| ndb_binlog_index | マスター | MyISAM | Epochとバイナリログファイル/ポジションの対応関係を記録 |
| ndb_apply_status | スレーブ | NDB | スレーブ側でバイナリログの内容をどのEpochまで反映したかを記録 |
MySQL Clusterでレプリケーションを構成する場合、通常はマスター側の2~3台のSQLノードでバイナリログ出力を有効にします(理由は後述)。そのためSQLノード毎にEpochとバイナリログポジションの対応を確認できるように、ndb_binlog_indexテーブルのストレージエンジンはNDBではなくMyISAMになっています。
一方、スレーブ側でバイナリログの内容をどのEpochまで反映したかを確認する際は、全SQLノードから同じ情報を確認できる必要があるため、ndb_apply_statusテーブルはNDBストレージエンジンを使用しています。
SQLノード1、2でバイナリログ出力を有効にし、データ更新後にそれぞれのSQLノードでndb_binlog_indexを確認した例がリスト1〜リスト4です。Epochを基準に情報を確認すると、同じEpochの情報が異なるバイナリログファイルに出力されています。
まず、SQLノード1に接続して現在のバイナリログ出力とEpochを確認します(リスト1)。
リスト1: 現在のバイナリログ出力とEpochを確認
# SQLノード1に接続 $ mysql -u root -h 127.0.0.1 # バイナリログの出力状況を確認 mysql> SHOW MASTER LOGS; +---------------+-----------+ | Log_name | File_size | +---------------+-----------+ | binlog.000001 | 120 | +---------------+-----------+ 1 row in set (0.00 sec) # 現在のEpochを確認(latest_epochが現在のEpoch) mysql> SHOW ENGINE NDB STATUS\G <中略> *************************** 15. row *************************** Type: ndbcluster Name: binlog Status: latest_epoch=103671920590854, latest_trans_epoch=103633265885196, latest_received_binlog_epoch=103671920590854, latest_handled_binlog_epoch=103671920590854, latest_applied_binlog_epoch=103568841375758 15 rows in set (0.01 sec)
次にデータを追加(INSERT)し、SHOW ENGINE NDB STATUSの結果からデータ追加時のEpochを確認します(リスト2)。latest_trans_epochには、このSQLノードで実行された最後のトランザクションのEpochが出力されるため、latest_trans_epochの値からデータ追加時のEpochを判断できます。
リスト2: データを追加し、データ追加時のEpochを確認
# データを追加 mysql> INSERT INTO world.City VALUES(10000,'TEST','JPN','TEST',0); Query OK, 1 row affected (0.00 sec) # データ更新時のEpochを確認(latest_trans_epoch= 103779294773259) mysql> SHOW ENGINE NDB STATUS\G <中略> *************************** 16. row *************************** Type: ndbcluster Name: binlog Status: latest_epoch=103809359544320, latest_trans_epoch=103779294773259, latest_received_binlog_epoch=103809359544320, latest_handled_binlog_epoch=103809359544320, latest_applied_binlog_epoch=103779294773259 16 rows in set (0.00 sec)
続いて、ndb_binlog_indexからEpochとバイナリログ出力の対応を確認します(リスト3)。リスト2で確認したEpoch(103779294773259)の情報が、SQLノード1ではbinlog.000001のポジション120に記録されていることが判断できます。
リスト3: ndb_binlog_indexの確認例(SQLノード1)
mysql> SELECT * FROM mysql.ndb_binlog_index WHERE epoch=103779294773259\G
*************************** 1. row ***************************
Position: 120
File: ./binlog.000001
epoch: 103779294773259
inserts: 1
updates: 0
deletes: 0
schemaops: 0
orig_server_id: 0
orig_epoch: 0
gci: 24163
next_position: 504
next_file: ./binlog.000001
1 row in set (0.00 sec)
最後に、同じEpochの情報がSQLノード2においてどのバイナリログに出力されているかを確認します(リスト4)。リスト3と同様の手順でndb_binlog_indexを確認すると、Epoch(103779294773259)の情報がSQLノード2ではbinlog.000004のポジション187648に記録されていること、同じEpochの情報がSQLノード毎に異なるバイナリログファイル/ポジションに出力されていることが確認できます。
リスト4: ndb_binlog_indexの確認例(SQLノード2)
# SQLノード2に接続
$ mysql -u root -h 127.0.0.1 -P 3307
# バイナリログの出力状況を確認
mysql> SHOW MASTER LOGS;
+---------------+-----------+
| Log_name | File_size |
+---------------+-----------+
| binlog.000001 | 1284 |
| binlog.000002 | 504 |
| binlog.000003 | 204 |
| binlog.000004 | 188032 |
+---------------+-----------+
4 rows in set (0.00 sec)
# ndb_binlog_indexから、Epochとバイナリログ出力の対応を確認
mysql> SELECT * FROM mysql.ndb_binlog_index WHERE epoch=103779294773259\G
*************************** 1. row ***************************
Position: 187648
File: ./binlog.000004
epoch: 103779294773259
inserts: 1
updates: 0
deletes: 0
schemaops: 0
orig_server_id: 0
orig_epoch: 0
gci: 24163
next_position: 188032
next_file: ./binlog.000004
1 row in set (0.00 sec)
マルチマスターレプリケーション構成時の競合検出ロジック
2組のMySQL Clusterがマスター/スレーブで双方向にレプリケーションを行うマルチマスターレプリケーションを構成した場合に、同じデータを両方のMySQL Clusterで更新した場合のデータ競合の検出や、検出したデータ競合を自動解決するためのロジックがあらかじめ用意されています(通常のMySQL Serverではこのようなロジックは用意されていないため、マルチマスターレプリケーションを構成した場合は競合検出ロジック自体をアプリケーション側に組み込む必要がある)。
MySQL Clusterでマルチマスターレプリケーションを構成した場合の競合検出の詳細については、下記のマニュアルを参照してください。
18.6.11. MySQL Cluster レプリケーションの競合解決
https://dev.mysql.com/doc/refman/5.6/ja/mysql-cluster-replication-conflict-resolution.html
レプリケーションの注意事項
MySQL Cluster環境でレプリケーションを使用する場合の注意事項について解説します。
レプリケーションチャネルを多重化する必要がある
SQLノードのBinlog Injectorスレッドは、SQLノードがデータノードに接続している時のみ機能します。つまり、SQLノードが停止していたり、再起動したりしている間に他のSQLノードから行われた更新内容はバイナリログに記録されません。予期せぬ障害やローリングリスタートなどで特定のSQLノードが停止する可能性に備えて、あるSQLノードが停止している間の更新内容を別のSQLノードで記録するため複数のSQLノードでバイナリログ出力を有効にし、レプリケーションチャネルを多重化する必要があります。
バイナリログ出力を有効にしているSQLノードが再起動すると、データに欠落が生じた可能性があることを示す「LOST_EVENTS」がバイナリログ内に記録されます。そして、このイベントを受け取ったスレーブはエラーとしてレプリケーションを停止します。
リスト5〜リスト8はLOST_EVENTSの確認例です。明示的にSQLノードを停止していますが、障害によりSQLノードが停止した場合でも、同様のLOST_EVENTSがバイナリログ内に記録されます。まず、現在のバイナリログのポジションと内容を確認します(リスト5)。現在のポジションはbinlog.000001の120です。
リスト5: 現在のバイナリログ出力を確認
# 現在のバイナリログを確認 $ mysql -u root -h 127.0.0.1 mysql> SHOW MASTER LOGS; +---------------+-----------+ | Log_name | File_size | +---------------+-----------+ | binlog.000001 | 120 | +---------------+-----------+ 1 row in set (0.00 sec) mysql> SHOW BINLOG EVENTS IN 'binlog.000001'; +---------------+-----+-------------+-----------+-------------+-------------------------------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +---------------+-----+-------------+-----------+-------------+-------------------------------------------------------------+ | binlog.000001 | 4 | Format_desc | 1 | 120 | Server ver: 5.6.24-ndb-7.4.6-cluster-gpl-log, Binlog ver: 4 | +---------------+-----+-------------+-----------+-------------+-------------------------------------------------------------+ 1 row in set (0.00 sec)
次にSQLノードを再起動してバイナリログの出力状況を再度確認すると、自動的にバイナリログがローテーションされてbinlog.000003まで出力されていました。またbinlog.000001の内容を"SHOW BINLOG EVENTS"で確認しましたが、特別なイベントは含まれていませんでした(リスト6)。
リスト6: SQLノードを再起動し、再度バイナリログの出力状況を確認
# SQLノードを再起動 $ mysqladmin -u root -h 127.0.0.1 shutdown $ mysqld --defaults-file=/home/mysql/mysqlc/my1.cnf & # 再度、バイナリログの出力状況を確認 $ mysql -u root -h 127.0.0.1 mysql> SHOW MASTER LOGS; +---------------+-----------+ | Log_name | File_size | +---------------+-----------+ | binlog.000001 | 143 | | binlog.000002 | 204 | | binlog.000003 | 120 | +---------------+-----------+ 3 rows in set (0.00 sec) mysql> SHOW BINLOG EVENTS IN 'binlog.000001'; +---------------+-----+-------------+-----------+-------------+-------------------------------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +---------------+-----+-------------+-----------+-------------+-------------------------------------------------------------+ | binlog.000001 | 4 | Format_desc | 1 | 120 | Server ver: 5.6.24-ndb-7.4.6-cluster-gpl-log, Binlog ver: 4 | | binlog.000001 | 120 | Stop | 1 | 143 | | +---------------+-----+-------------+-----------+-------------+-------------------------------------------------------------+ 2 rows in set (0.00 sec)
続いてbinlog.000002の内容を確認すると(リスト7)、LOST_EVENTSが記録されていることが確認できました(binlog.000003には特別な出力はなかった)。
リスト7: LOST_EVENTSが記録されているバイナリログ
mysql> SHOW BINLOG EVENTS IN 'binlog.000002'; +---------------+-----+-------------+-----------+-------------+-------------------------------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +---------------+-----+-------------+-----------+-------------+-------------------------------------------------------------+ | binlog.000002 | 4 | Format_desc | 1 | 120 | Server ver: 5.6.24-ndb-7.4.6-cluster-gpl-log, Binlog ver: 4 | | binlog.000002 | 120 | Incident | 1 | 160 | #1 (LOST_EVENTS) | | binlog.000002 | 160 | Rotate | 1 | 204 | binlog.000003;pos=4 | +---------------+-----+-------------+-----------+-------------+-------------------------------------------------------------+ 3 rows in set (0.00 sec) mysql> SHOW BINLOG EVENTS IN 'binlog.000003'; +---------------+-----+-------------+-----------+-------------+-------------------------------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +---------------+-----+-------------+-----------+-------------+-------------------------------------------------------------+ | binlog.000003 | 4 | Format_desc | 1 | 120 | Server ver: 5.6.24-ndb-7.4.6-cluster-gpl-log, Binlog ver: 4 | +---------------+-----+-------------+-----------+-------------+-------------------------------------------------------------+ 1 row in set (0.00 sec)
別の確認方法として、mysqlbinlogコマンドを使用した場合の例がリスト8です。出力結果に"Incident: LOST_EVENTS"が含まれていることを確認できます。
リスト8: mysqlbinlogでの確認例
$ mysqlbinlog binlog.000002 /*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/; /*!40019 SET @@session.max_insert_delayed_threads=0*/; /*!50003 SET <中略> # at 120 #151005 10:17:48 server id 1 end_log_pos 160 CRC32 0x27fcc2f5 # Incident: LOST_EVENTS RELOAD DATABASE; # Shall generate syntax error <中略> # End of log file ROLLBACK /* added by mysqlbinlog */; /*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/; /*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=0*/;
LOST_EVENTSによりレプリケーションが停止した場合は、マスターのバイナリログ出力を継続している別のSQLノードに接続し直してレプリケーションを再開します。スレーブのndb_apply_statusを参照して反映済みのEpochを確認後、マスターのndb_binlog_indexを参照してバイナリログのファイル名とポジションを確認します。ndb_apply_statusやndb_binlog_indexを参照してレプリケーションを開始する方法の具体例は、次回で解説予定です。
バイナリログ出力を有効にするとノード間の通信量が増大する
SQLノードでバイナリログ出力を有効にすると、データノードでの更新内容をSQLノードに伝達するためノード間の通信量が増大します。その分他の処理に使用できる帯域が減りパフォーマンスの悪化につながる可能性があるため、バイナリログを出力するSQLノード数は必要最低限にします。一般的には2~3つのSQLノードでバイナリログ出力を有効にすると良いでしょう。
バイナリログのフォーマットはROWにする(ROWになる)
MySQL Clusterのバイナリログはデータノードで更新された内容をSQLノードに伝達して書き込まれますが、データノードではどのようなステートメント(SQL文)によりデータが更新されたのかを把握していません。そのためバイナリログのフォーマットは必然的にROWとなり、行ベースのレプリケーションが行われます。my.cnfの設定値として"binlog_format=MIXED"や"binlog_format=STATEMENT"のほかデフォルト設定(binlog_format=MIXED)で使用することもできますが、自動的に行ベースレプリケーションが行われます。混乱を避けるためにも、明示的に“binlog_format=ROW”を指定する方が良いでしょう。
おわりに
今回は、MySQL Clusterのレプリケーションのメリットや仕組み、注意事項について解説しました。第8回では、MySQL Clusterのレプリケーション環境構築の具体例について解説する予定です。
※本稿において示されている見解は、私自身の見解であって、私の所属するオラクルの見解を必ずしも反映したものではありません。
- この記事のキーワード
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
