4つのタイプから想定する、適切なシステム運用のサイクル
正しいシステム運用のかたち前回に続き、「大規模システムやクラウド環境に適した運用設計」と題して、将来を見据えたシステムの改善や、次の開発につなげることができるような運用設計手法について説明する。 システム運用においては、いくつかのキーワードに分割することができる。表1のように、大きく4つに分類でき
2014年4月16日 3:00
正しいシステム運用のかたち
前回に続き、「大規模システムやクラウド環境に適した運用設計」と題して、将来を見据えたシステムの改善や、次の開発につなげることができるような運用設計手法について説明する。
システム運用においては、いくつかのキーワードに分割することができる。表1のように、大きく4つに分類できるが、4番目の項目は択一で、これを、
のように回し続けることが肝要だ(図1参照)。
| キーワード | 内容 |
|---|---|
| 1 監視 | 監視がないとシステムに問題が発生しても、すぐに気づかない。情報収集がないと問題の原因追究ができないので、監視は情報収集を必須とする。 |
| 2 対応 | 事前に用意した対応マニュアルに基づき障害対応を実施。復旧しない場合は責任者へエスカレーションする。 |
| 3 分析 | 予期せず発生した障害は、収集した情報を分析して根本原因を明らかにする。同時に、対応に問題はなかったかも分析する。障害はなくても定期的に収集した情報を分析し、障害の兆候がないかを確認。 |
| 4-1 改善 | 根本原因が設定調整によって解消可能な場合。パッチの適用や設定ファイルの変更、ネットワークの設定調整などを行う。わからない場合は、次に備えて収集する情報を増強しておく。 |
| 4-2 拡張 | 根本原因が部分的なシステムリソースの不足にある場合。 サーバーのー増設やアプリケーションの機能拡張などを行う。 |
| 4-3 刷新 | 根本原因がシステム全体のリソース不足や老朽化にある場合。 新システムを設計・構築し、旧システムと入れ替える。 |
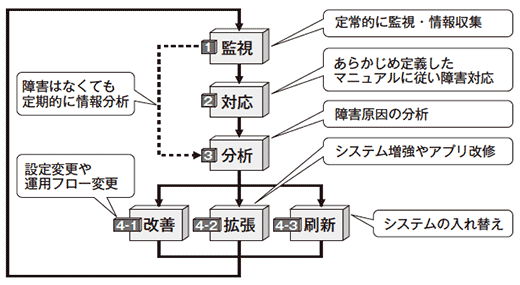
必要最小限の運用サイクル:「監視」⇒「対応」⇒「分析」⇒「改善」
ここで、必要最小限のシステムのライフサイクルを具体的に見ていこう。
まず、最低限必要な「監視」を開始する。例えば、ブラウザーで閲覧するようなサービスであれば、トップページが表示できるかどうかを、5分おきに確認するくらいで、十分にその要件を満たす。当然、「手動でブラウザーを開いて確認する」作業は、継続できるわけではないので、障害発生時の通知を含めて、何らかの自動化を行うことになる。それと同時に、どのくらいの時間で表示できたのかという情報は、保存するようにしておくことを忘れないようにしていただきたい。このことは、後の「分析」の段階で必須の情報となる。
次に「対応」だが、事前に「誰が対応するのか」を決定しておけば、最低限の要件を満たす。「対応」完了後、あらかじめ収集しておいたデータで障害時の状況を「分析」し、原因を特定する。このとき、特定に至らない場合は推定する。
最後に、「改善」を実施するが、原因が明らかになった場合にはその対応を実施し、そうでない場合は推定した原因に基づいて、新たな監視ポイントを追加設定する。その際、情報収集も忘れないようにすることが大切だ。また、同様の現象が発生した場合の対応手順を作成し、次回はより迅速に復旧できるよう、備えておく。
これらの運用のサイクルを回すにつれ、監視や情報収集ポイントが増えてゆき、次第に問題の原因が絞り込まれていくことになる。最終的には原因は判明し、解決できるだろう。
障害ありきのサイクルからの脱却:「監視」⇒「分析」⇒「改善」
確かに最低限のサイクルは前項の通りだが、これではほとんど障害待ちであり、本当の意味で障害に備えているとは言えない。障害はなくとも、定期的に収集した情報を分析しよう。
「障害発生時」という、明確に注目するポイントがないため、やや難易度が高いが、例えば簡単な方法として、収集しているすべてのグラフを、当月分と前月分とを並べて比較してみるといい。まったく同一であれば何の対処も必要ないが、当月が前月よりもページの表示速度が遅くなっているなどの差異があるのであれば、その原因を追究していくことになる。
次に、突き止めた原因に基づいて設定調整を行う。原因が明らかにならなければ、監視・情報収集ポイントを増やすよう、「改善」を実施しておく。
以上のサイクルを回すことにより、障害は未然に防がれるようになっていく。
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
