Amazonが解説する次世代の対話インターフェース、Alexaの仕組み
Alexa開発のマネージャーが製品を支える様々なテクノロジーを解説する。
2018年1月9日 6:00
オライリー主催のAI Conferenceシリーズの第6弾は、Amazonが開発し、アメリカではスマートスピーカーという製品として販売が進んでいるAlexaに関するセッションをお届けする。発表を行ったのはAshwin Ram氏。経歴を見ると、「Alexaを支えるAIテクノロジーのシニアマネージャー」とあるが、PARCで自然言語とAIを研究し、その前はジョージア工科大学の教授であるロジャー・シャンクが指導教授であったという経歴からして、AI、それも自然言語処理に大きな実績を持っている人物であることがわかる。Alexaの開発をリードするには最適な人物と言えるだろう。
Ram氏はEcho Tapを壇上に持ち込んで実際に音声の認識を行いながら、Alexaのコアとなっているテクノロジーやハードウェアの特徴などについて解説を行った。

Alexaを解説するAshwin Ram氏
最初に出てきたスライドは「これまでのタッチ操作はもうすぐ終わる。次に来るのは音声による操作だ」という内容で、スマートフォン、スマートウォッチ、スマートホームのためのデバイス、さらには車に搭載されるインフォテイメントシステムにおいては、音声による操作が当たり前になるとAmazonが考えていることがわかる。
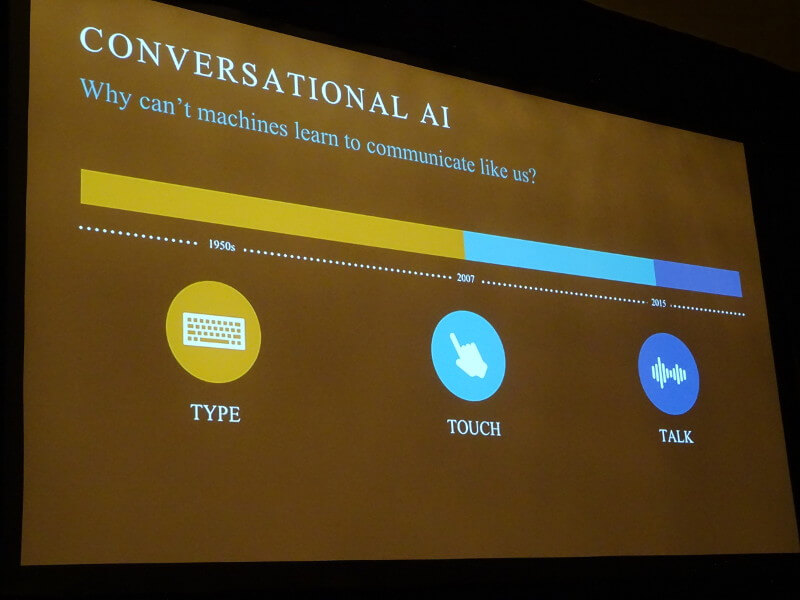
タイピングからタッチ、そして音声に移ってきたことを説明
しかし、未だにコンピュータが人間同士のようにコミュニケーションを行えるようにはなっていないと説明し、そこにAlaxaが登場したと語り、この領域で先行するAmazonのEchoに関して、まずはハードウェアの概要を解説した。

9月19日現在のEchoはこんな感じ
実際にはAmazonは9月27日にEcho関連の新製品を発表しているため、この記事が公開される頃にはこのスライドはあまり意味がないものになってしまっている。
Ram氏はAmazon Echoが広いアメリカの住宅で使われることを想定して、どの角度からの音声命令も受け取れるような構造になっていること、複数のEchoが存在する場合に、どうやって発声した人に一番近いEchoを選んで返事をさせるのか? などを充分に想定した構造になっていることなどが紹介された。

複数のマイクを装備してどの角度からも聞き取れるようになっている
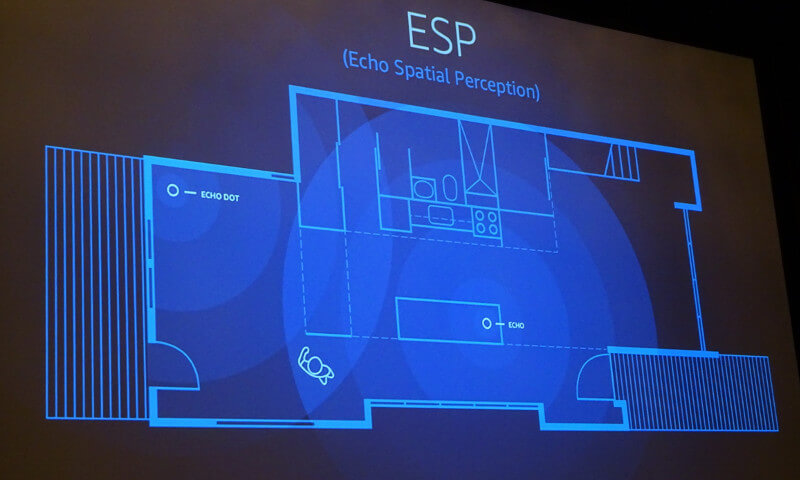
反響を利用した空間認識を行っているという
またタッチやタイピングと違う難しさについて「バラク・オバマは誰?」「彼の妻は誰?」「彼はいつ生まれたの?」という一連の質問を、Alexaが「彼=バラク・オバマ」という文脈を保持しながら代名詞を認識するということについて解説を行った。ここでは「何を聞いているのか」を理解する音声認識、「質問の意味は何か?」を理解する自然言語理解、そして質問者とAlexaが同じ文脈について話をしているという文脈のモデリングという、それぞれ非常にレベルの高い処理を数秒でこなすというAlexaの凄さについて解説を行った。

人間との会話なら当たり前のことをやれるAlexaの凄さ
その高速な処理を行うためにデバイス側とクラウド側での処理の分担について解説したのが、次のスライドだ。
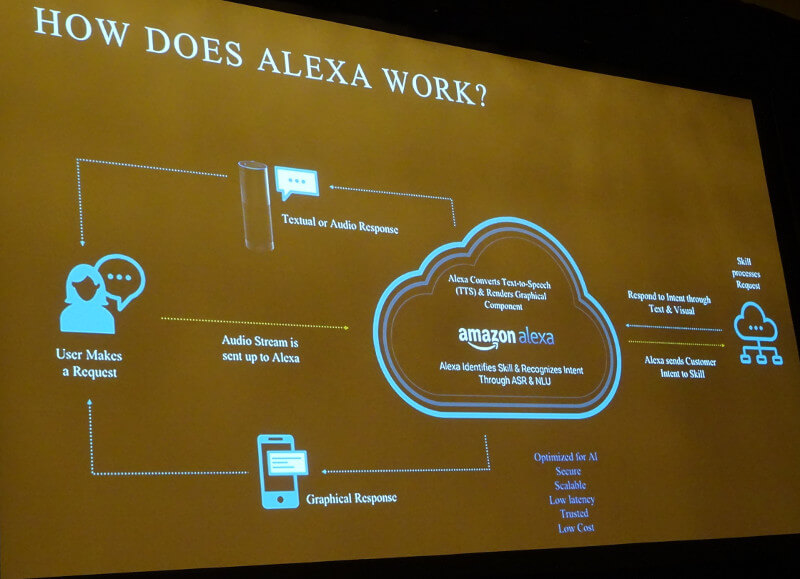
デバイスとクラウドが連携したAlexaの処理
デバイス側で音声信号の処理と起動ワードの認識を行い、残りの部分は全てクラウドに存在するアプリケーションが処理を行うという。「今日、外は暑いの?」という質問に対して文章を組み立てて、「暑い」という単語から天気について質問をしていることを理解し、それを音声として組み立ててデバイスにストリームする、という一連の流れが解説された。
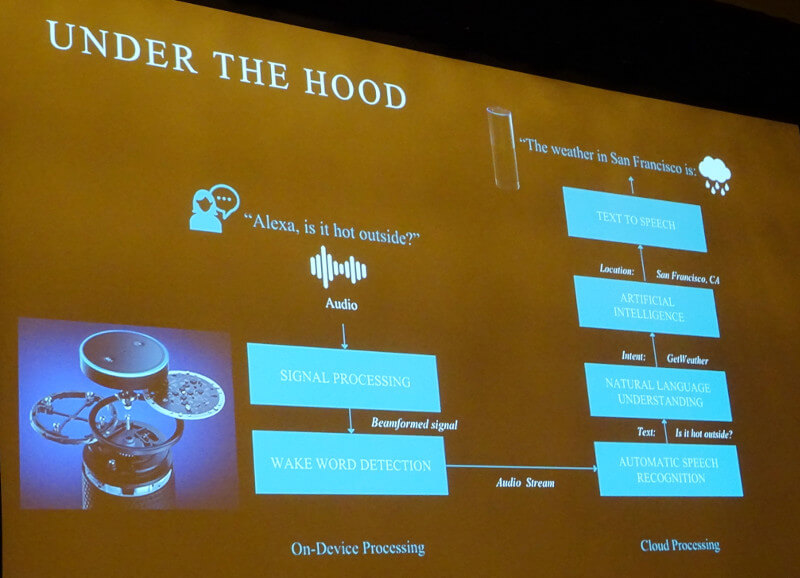
Alexaにおける詳細な処理の流れ
人工知能の部分についてもデータ駆動型の機械学習を使っていることが紹介され、ノイズや曖昧さに対して有効であること、様々なドメインの知識や多言語に対応がし易いことなどが挙げられた。

Alexaにおける機械学習の概要
さらに、音声認識についてのモデリングの概要についても解説を行った。この部分は、これから音声認識の組み込みを計画している様々な企業にとって参考になるのではないだろうか。
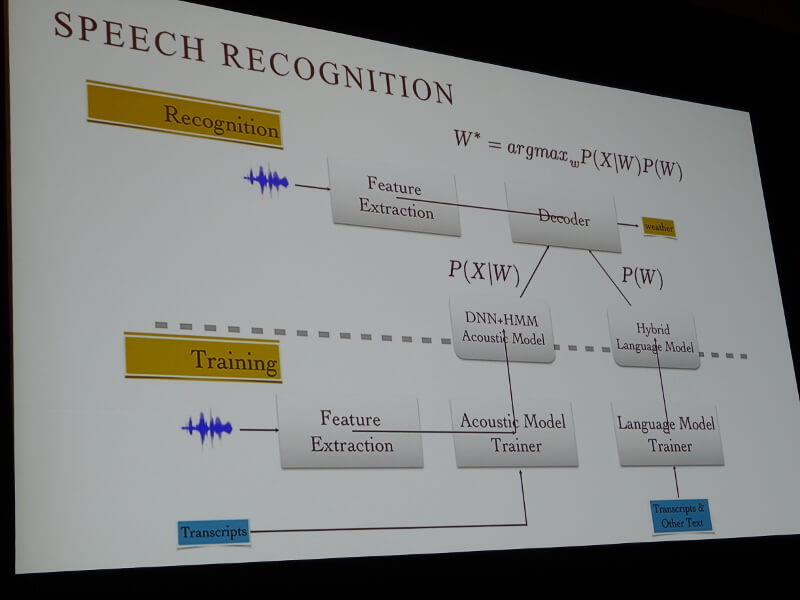
Alexaの音声認識モデル
そして同じ単語であっても、文脈に寄って発音が異なるものをどう処理するのか(例:「Live」におけるライブとリブの使い分け)、利用者が意味することを過去の認識の結果に従って学習すること(「P!nkの音楽をかけて」という命令を、この場合は「P!nk」という固有のシンガーであり、一般的な形容詞の「pink」ではないという意味を理解すること)の難しさを例に挙げて解説した。
また高速な処理を可能にするために、AWSにおけるEC2のGPUインスタンスを利用していることを紹介した。この例では、80台のGPUによって深層学習が行われることによって、高速なトレーニングが可能になったという。

EC2とS3を活用したAlexaのバックエンド
「音声によるインタラクションがタッチを超える」という未来を実現するために、Amazonが「対話」という機能を重要視していることは「Amazon Alexa Prize」という大学を対象にしたコンペティションを実施していることでも理解できるだろう。これは20分間、Alexaとの対話を行うChatBotをそれぞれの大学が開発し、その内容を競い合うもので、総額250万USドルという賞金、開発に必要なデバイス、Botを実行するAWSのリソースなどをAmazonが提供するものだ。アメリカからだけではなく、スコットランド、チェコ、ドイツ、韓国などの大学も参加しており、最終的な勝者は12月にラスベガスで開催されるre:INVENT2017で発表されるという。これがユニークなのは、各大学のチームを指導する教授が、錚々たる自然言語処理の専門家が揃っていることと、Alexaのユーザーであれば「Alexa, Let's chat」という命令を与えることで、誰でも学生たちが開発したChatBotを評価できるという点だろう。ここであえて企業を対象とせず、大学に限定した競争を企画したあたりに人間との「対話」を深めようとするための意図を感じた。
潤沢なコンピューティングリソースと安価なデバイス、そして世界中の大学を巻き込んで「次世代の対話インターフェース」を追求するAmazonの凄みを感じたセッションであった。日本市場でもAmazon Echoの展開が発表され、いよいよ日本語による自然言語処理に一定のメドが立ったということだろう。すでにドコモなどがパートナーとして公表されており、今後の進化に期待したい。

Amazon Alexa Prizeの概要
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
