OpenShift AIの事例
OpenShift AIの事例
次に紹介するのは2024年2月にRed HatのOpenShift AIのチームが来日した時にインタビューを行ったChristopher Nuland氏と、ELOTLのVP of EngineeringであるSelvi Kadirvel氏がKubernetesのマルチクラスターを管理するFleet Managerを使って実装した事例に関するセッションだ。

プレゼンテーションを行ったのはELOTLの Kadirvel氏とRed HatのNuland氏
ちなみにFleet ManagerはAWSのシステム管理の機能としても知られているが、この場合はELOTLのマルチクラウド用コントロールプレーンであるNovaの機能を指している。
●参考:Nova: A Policy-Driven Multi-Cloud Multi-Cluster Orchestrator
マルチクラウドを利用する上で一般的なWebアプリケーションではなく、機械学習に使われることを想定して大量のデータをオンプレミス、パブリッククラウドで使い分ける際にクラスターの選択をFleet Managerで行い、クラスター内のワークロードの管理はKubernetesに任せるという発想だろう。

Fleet Managerの解説。ここではクラスターを管理する役割がFleet Managerの仕事
その上で実装段階において必要な仕事とシステムが立ち上がった後で運用として必要な仕事について解説し、ワークロードの処理時間がWebアプリとは異なる性格を持つことを指摘。特にポイントとなるのが、ジョブに必要なリソースをどうやって確保するのか? だと説明した。

生成型AIのアプリケーション実装のためのパイプラインを説明
ここで機械学習においてはデータの整備、モデルの学習、モデルのチューニング、データの埋め込み、推論、モデルの評価などのプロセスが、パイプラインとして整備されていることが必須となることを説明した。
そして新薬開発のためのユースケースを想定して、エンドユーザーであるリサーチャーが対話型のアプリケーションを通じて生成型AIを使う場合のフローを紹介した。
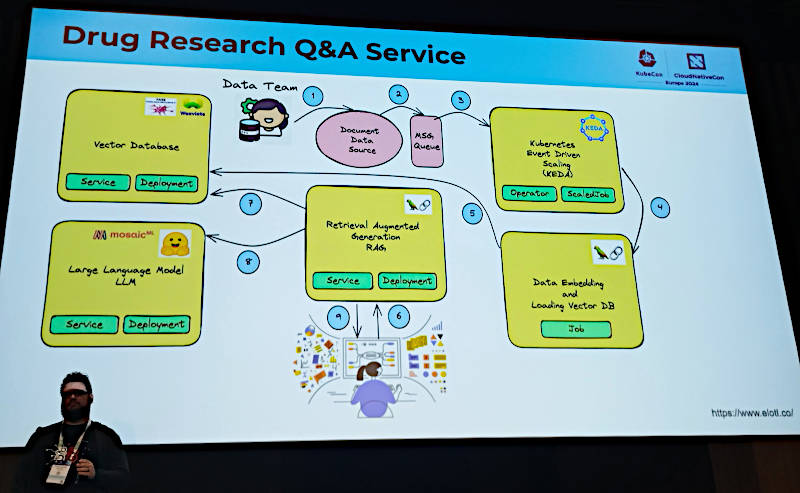
新薬開発のためにRAGアプリケーションのフローダイアグラムを解説
その際にデータベースが集約されているWebアプリケーションとは違い、その都度、大量なデータセットを用意する必要がある生成型AIのアプリケーションにおいてはデータがどこにあるのか? が重要になるとして、Data Gravityについて解説。ここではアプリケーションが必要とするデータをどうやって近接に持ってくるのか? が重要だという論点だ。

生成型AIにおける「データの近さ」をData Gravityとして説明
他の業界のアプリケーションと比べて、医療関連のシステムにおいて「データの近さ」が重要になることを業界の識者だと思われるTony Bishop氏のコメントを引用して説明している。遅延を想定すればどのアプリケーションでも遅延が少ないほうが好ましいのは当たり前だが、どうして医療関係においてそれが重要になるのか? という部分については特に説明がなかったのは残念である。

RAGアプリケーションにおいてデータが近くにあることが重要と説明
対話型で実行されるRAGアプリケーションにとって遅延は少ない方が良く、そのためにはデータの整備から始まるパイプラインも同様に近いデータセンターで処理されるほうが良いと説明。
そのためには1つのデータセンターに集約するのではなくマルチクラウド、オンプレミスとパブリッククラウドを想定して実装されることが重要だというのがRed Hatの論点だ。そのため透過的に複数のクラウドを操作できるFleet Managerのようなツールが必要となるというのがこのプレゼンテーションのゴールということだろう。

医療関係のRAGアプリケーションにはFleet Managerが必要
そして複数のクラウドを使い分ける簡単なデモを実施。ここではコマンドラインから操作し、複数のクラウドを使い分けていることを示した。
最後にまとめとしてELOTLのFleet ManagerのダウンロードサイトのURLを示しながら、複数のクラウドを使い分けることが遅延の少ないRAGアプリケーションにおいては重要であり、ELOTLのNovaはその候補になり得ることを説明してセッションを終えた。
全体としてELOTLのFleet Managerを使うことを前提として組み立てられており、単一のパブリッククラウドを使った場合との速度比較などがなかったのが残念だったと言えよう。RAGアプリケーションのようにユーザーが即座にその結果を手にすることができることが重要なアプリケーションの特性と、データのロケーションとの相関関係についてもっと深い解説をして欲しかった。
セッションの動画は以下から参照できる。
●動画:Gen-AI at Scale: Simplifying Orchestration of Healthcare Applications Across Multi-Cluster
- この記事のキーワード
関連記事
KubeCon Europe 2025から、Red Hatが生成AIのプラットフォームについて解説したセッションを紹介
6月19日 6:00
KubeCon Europe 2024のキーノートからツァイスのWebAssemblyを使った事例を紹介
2024年5月24日 6:00
KubeCon North America 2024からAIワークロードのスケジューリングに関するセッションを紹介
3月13日 6:00
KubeCon Europe 2024併催のCloud Native Wasm Dayから、FA機器にWebAssemblyを適用したセッションを紹介
2024年5月20日 6:00
Kubernetesで機械学習を実現するKubeflowとは?
2018年6月1日 6:00
KubeCon EU 2022からバッチシステムをKubernetesで実装するVolcanoを紹介
2022年9月15日 6:00
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
RustとWASMで開発されKubernetesで実装されたデータストリームシステムFluvioを紹介
2022年12月23日 6:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
