プラットフォームが育つ4つのシナリオで見る「Helm」「KubeVela」「Crossplane」「Kro」の違い
第2回の今回は、Application Modelに関わるツール群「Helm」「KubeVela」「Crossplane」「Kro」がどのような設計思想を持つのか、同一のワークロードをデプロイしながら比較します。
5月12日 6:30
はじめに
前回はOAMの歴史を辿りながら「開発者が何を知らなくて済むべきか」がApplication Modelの核心だと論じました。「自分たちの開発者にとって、何を知らなくて済むべきか。この問いに対する各組織の回答が、そのままその組織のApplication Modelになる」という結論でした。
では、具体的にどう実装するのか。ここで各ツールの答えが大きく割れます。「Kubernetesの概念をパラメータ化すれば良い」というアプローチもあれば「Kubernetesの存在自体を隠すべきだ」というアプローチもあります。
抽象の深さ、プラットフォーム側の構築コスト、例外への耐性。どこに設計の重心を置くかで、ツールの性格は根本的に変わります。
本稿ではまず3つの設計思想を整理し、その後、同一のWebアプリケーションを段階的に拡張する4つのシナリオで比較します。比較の軸は「Definition(定義)の設計」に絞っています。ドリフト検出、ロールバック、デバッグ体験、RBAC設計など運用面での比較は第3回以降の各ツール深掘りで扱います。すべてのマニフェストはGitHubリポジトリで公開しており、kind clusterで動作確認済みです。
比較するツール
今回の比較対象は、素のKubernetesを含む5つの実装パターンです。
- Helm(v4, 2025年11月): Kubernetesのデファクトパッケージマネージャ。Go templateベースのチャートでマニフェストを生成する。CNCF Survey 2024で約70%のKubernetesユーザーが利用と報告
- KubeVela(v1.10, CNCF Incubating): 前回で取り上げたOAMの唯一の実装。CUEベースのDefinition層でアプリケーション抽象を定義する。2023年半ば以降の開発活動は大幅に鈍化している
- Crossplane(v2.2, CNCF Graduated): インフラ管理のコントロールプレーンとして出発し、2.0でアプリケーション管理にも拡張。XRDとCompositionで「組織独自のAPI」を作る
- Kro(v0.9, Alpha): AWS・Google・Microsoftが共同開発するオープンソースプロジェクト(kubernetes-sigs傘下)。ResourceGraphDefinition(RGD)でスキーマとリソーステンプレートを記述すると、Kroコントローラがそのスキーマに対応するカスタムリソース(例: WebApplication)をクラスタに登録する。開発者はそのカスタムリソースのインスタンスを書くだけでよい
Application Modelの設計フロー
ツールの比較に入る前に、Application Modelがどのような流れで設計・運用されるのかを整理します。どのツールを使っても、やるべきことの構造は共通です。
二者の責任
Application Modelには必ず2つの役割があります。
プラットフォームチーム(定義する側):
- 「開発者に何を見せ、何を隠すか」を決める
- 抽象の裏側でKubernetesリソースを生成するロジックを書く(Helm template、CUE Definition、Composition等)
- 組織のセキュリティポリシー、リソース制限、可観測性の設定をデフォルトとして埋め込む
- 開発者からの要望に応じて、公開パラメータを追加・修正する
開発者(利用する側):
- プラットフォームチームが用意したインターフェース(values.yaml、Application CR、XR等)にパラメータを書く
- Kubernetesリソースの詳細は知らなくてよい(が、デバッグ時には見る必要がある場合もある)
- 「こういう設定が欲しい」とプラットフォームチームにフィードバックする
前回で述べたOAMの「Definition層(Infrastructure Operator)」と「Application層(Developer)」の分離はOAM固有の設計ではなく、Application Model一般に共通する構造です。
設計の流れ
Application Modelの構築は、一般的に以下のステップで進みます。
- スコープを決める:「何を隠すか」を決めます。全サービス共通で固定する設定(セキュリティポリシー、リソース制限のデフォルト等)と、サービスごとに変えられるパラメータ(イメージ名、ポート、レプリカ数等)の境界を引きます
- 定義を書く: プラットフォームチームがツールに応じた形式(Helm template、CUE、Composition、RGD)で「パラメータ → Kubernetesリソース」の変換ロジックを実装します
- 開発者が使う: 開発者は用意されたインターフェースにパラメータを書いてデプロイします
- フィードバックで育てる:「この設定も変えたい」「この要件に対応できない」といったフィードバックに応じて、定義を拡張していきます
この4番目のステップが重要です。Application Modelは一度作って終わりではなく、Platform as a Productとして継続的に改善するものです。本稿のシナリオ3(ポリシー追加)やシナリオ4(例外対応)は、まさにこのフィードバックループで起きることです。
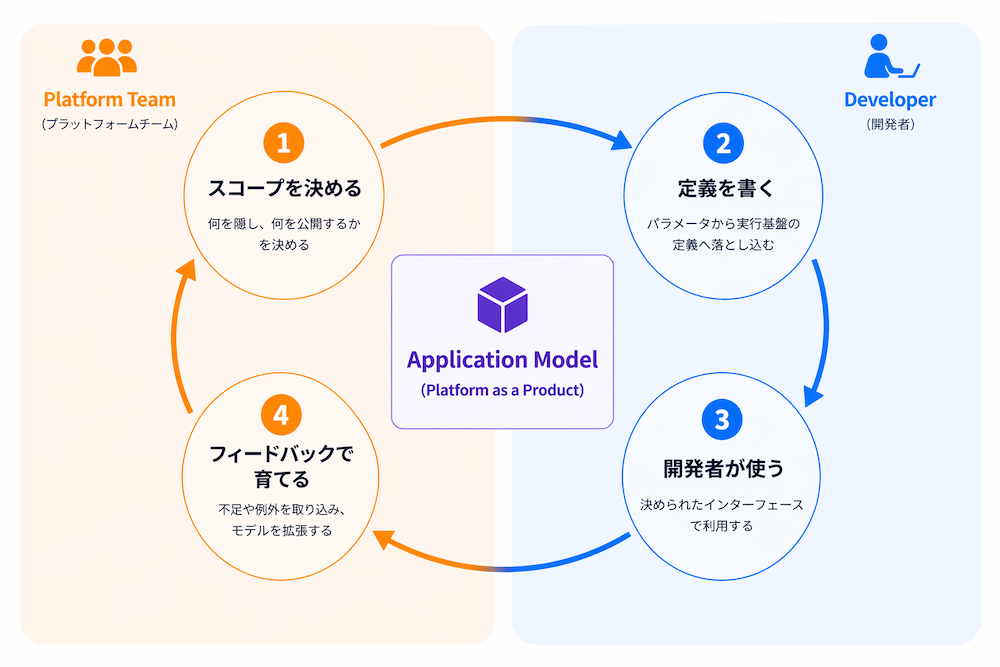
ツールの選択は、このフロー全体のうち主にステップ2「定義を書く」に影響します。次項で、その書き方の設計思想を3つに分類します。
3つの設計思想
ここからは「各ツールがどのような発想で抽象を作っているか」で整理します。見方としては3つです。Helmは既存のKubernetes YAMLをテンプレート化する方式、KubeVelaは「型」を定義して使わせる方式、CrossplaneとKroは組織独自のAPIを作るコンポジション方式です。素のKubernetesは比較のためのベースラインとして後から並べます。なお、Kubernetesを前提としないプラットフォーム非依存のワークロード仕様としてScoreも存在しますが、本稿ではKubernetesネイティブな3つの方式に焦点を当てます。
テンプレート方式(Helm)
既存のKubernetes YAMLをパラメータ化するアプローチです。テンプレートエンジンがリソーステンプレートの穴をパラメータ値で埋めます。
開発者が書くのはvalues.yamlのパラメータ値だけです。ただし、パラメータ名にKubernetesの概念がにじみ出ます。hpa.enabled、ingress.host、resources.limits.cpu。
抽象は薄いですが、テンプレートの中身はただのKubernetes YAMLです。Kubernetes経験者には馴染みやすい方式です。
モデル方式(KubeVela/OAM)
「型」(ComponentDefinition)を定義し、開発者がその型のインスタンスをパラメータ付きで作成するアプローチです。OAMのComponent/Trait分離に着想を得ています。
プラットフォームチームがCUEでDefinitionを書き、開発者はApplication CRを書きます。type: web-apiと書くだけでDeployment+Service+HPA+ConfigMap+ExternalSecretが生成され、serviceTypeの値でprobe挙動が自動で切り替わります。
コンポジション方式(Crossplane, Kro)
Kubernetesに新しいAPI(カスタムリソース)を追加し、裏側のリソースを完全に隠すアプローチです。開発者はkind: WebApplicationを使い、kind: Deploymentを知る必要がありません。
プラットフォームチームがカスタムAPIのフィールドと実リソースのマッピングを定義します。Crossplaneはパッチベース、Kroはテンプレートベースです。開発者の視界からKubernetesの標準API(Deployment、Service等)は消えますが、カスタムAPIのフィールド設計によってはreplicasやportのようなKubernetes由来の概念が残ります。抽象度はプラットフォームチームのAPI設計次第です。
比較表

「サーバーサイド」はKubernetes上でコントローラが常駐し、リソースを継続的にreconcileする方式です。ドリフト検出(手動変更の自動修復)が可能です。「クライアントサイド」はCLIでマニフェストを生成し、applyはkubectlやArgoCDなど別のツールで行う方式です(Helmが該当)。
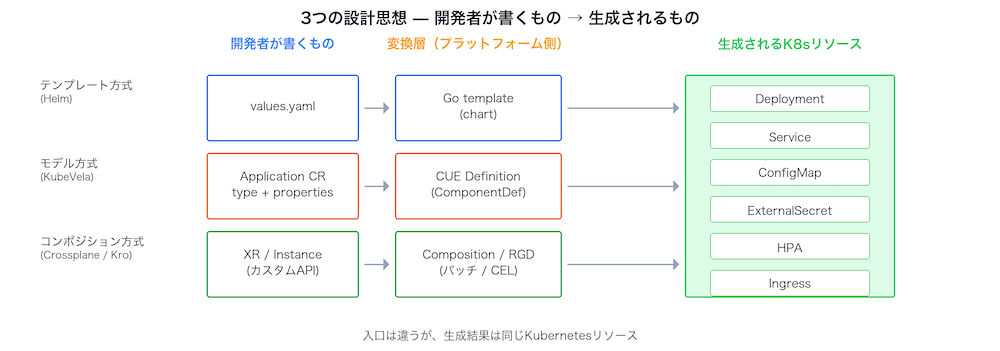
抽象度が高いほど開発者の記述量は減りますが、プラットフォーム側の構築コストは増えます。どの抽象度が正解かは組織の規模と成熟度次第です。これから4つのシナリオで具体的に見ていきます。
リファレンスワークロード: order-api
比較に使うワークロードは、シンプルなWeb APIサーバーです。
- イメージ: nginx:latest(ポート8080)
- 環境変数: APP_ENV、LOG_LEVEL(ConfigMap経由)
- Secret: DB_CREDENTIAL(ExternalSecret経由でAWS Secrets Managerから取得。JSON形式でhost、port、user、passwordを格納)
- オートスケール: CPU使用率80%、2〜10レプリカ
- Ingress: order-api.example.com
SecretはKubernetesのSecretリソースに直接値を書くのではなく、ExternalSecret(external-secrets.io)を使っています。ExternalSecretは外部のシークレットストア(AWS Secrets Manager、HashiCorp Vault等)から値を取得し、Kubernetes Secretを自動生成するoperatorです。
AWS Secrets Managerの場合、1つのSecretに{"host":"db.example.com","port":5432,"user":"app","password":"..."}のようなJSON形式で格納し、ExternalSecretのremoteRef.propertyで個別フィールドを取り出すのが一般的です。開発者はExternalSecretリソースに「どのキーを取得するか」を宣言するだけで、Secret本体は自動的に作られます。実運用でSecretを平文でYAMLに書くことはまずありません。
素のKubernetesで書くとDeployment・Service・ConfigMap・ExternalSecret・HPA・Ingressの6リソースになります。開発者が本当に決めたいのはイメージ名、ポート、環境変数、ドメイン名くらいですが、それを伝えるためにKubernetesの6つのリソース仕様を理解し、ラベルのセレクタを一致させ、リソース間の参照を正しく繋ぐ必要があります。
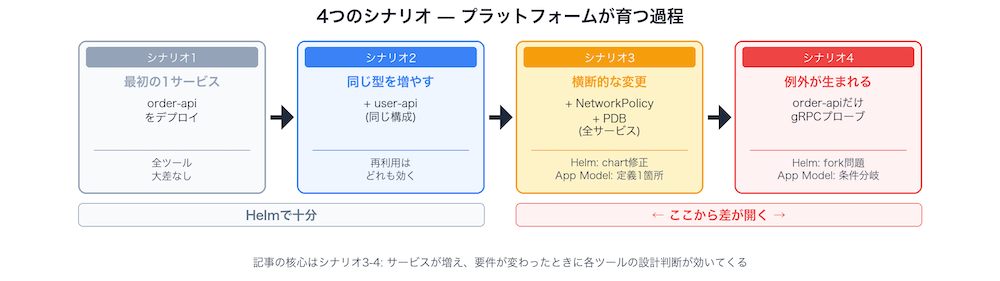
シナリオ1: 最初のサービスをどう定義するか
各ツールでorder-apiをデプロイします。ここで注目してほしいのは「開発者が書くもの」と「プラットフォーム側が用意するもの」の二層構造です。
どのツールも開発者に見せるインターフェース(values.yaml、Application CR、XR等)と、その裏でKubernetesリソースを生成するロジック(Helm template、ComponentDefinition、Composition等)に分かれています。
前回で述べたOAMの「Application層」と「Definition層」の考え方は、OAM以外のツールにも共通する構造です。
この二層の境界をどこに引くか ー何を開発者に見せ、何をプラットフォーム側に隠すかー がツールごとの設計判断の核心です。
Helm
開発者が書くもの ーvalues.yaml(27行):
image: nginx:latest
port: 8080
env:
APP_ENV: production
LOG_LEVEL: info
secret:
DB_CREDENTIAL: "" # AWS Secrets Manager key(JSON: host, port, user, password)
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 500m
memory: 512Mi
hpa:
enabled: true
minReplicas: 2
maxReplicas: 10
cpuTargetPercent: 80
ingress:
enabled: true
host: order-api.example.comhelm install order-api ./chart -f order-api-values.yaml で6リソースが生成されます。Kubernetesの概念がvaluesのキー名としてうっすら見えますが、リソース定義そのものは書いていません。
プラットフォーム側が書くもの ーHelmチャート(templates/配下に6テンプレート)。Deployment templateの例:
# chart/templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Release.Name }}
labels:
app: {{ .Release.Name }}
spec:
selector:
matchLabels:
app: {{ .Release.Name }}
template:
spec:
containers:
- name: {{ .Release.Name }}
image: {{ .Values.image }}
ports:
- containerPort: {{ .Values.port }}
env:
{{- range $key, $value := .Values.env }}
- name: {{ $key }}
valueFrom:
configMapKeyRef:
name: {{ $.Release.Name }}-config
key: {{ $key }}
{{- end }}
resources:
{{- toYaml .Values.resources | nindent 12 }}Go templateで{{ .Values.xxx }}をリソースにマッピングする構造です。valuesに公開されたパラメータだけが開発者から変更可能で、それ以外(ラベル、セレクタ、プローブの有無など)はtemplateに固定されています。
この「公開範囲」の制御がHelmチャートの設計そのものです。
KubeVela
KubeVelaの核心はDefinition層です。ビルトインのwebservice型を使うこともできますが、実運用ではプラットフォームチームがカスタムComponentDefinitionを書くのが前提です。
ここでは、カスタムのweb-api型を定義した上で使います。
開発者が書くもの ーApplication CR(24行):
apiVersion: core.oam.dev/v1beta1
kind: Application
metadata:
name: order-api
spec:
components:
- name: order-api
type: web-api # カスタムComponentDefinitionを参照
properties:
image: nginx:latest
port: 8080
serviceType: http # probeの種類を決める
envVars: # → ConfigMapを自動生成
APP_ENV: production
LOG_LEVEL: info
secrets: # → ExternalSecretを自動生成
DB_CREDENTIAL: order-api/db-credential
traits:
- type: gateway # Ingress生成
properties:
domain: order-api.example.com
existingServiceName: order-api
http:
"/": 8080type: web-apiでカスタムDefinitionを参照し、propertiesでパラメータを渡します。注目すべきは、開発者がConfigMapやExternalSecretのYAMLを一切書いていない点です。envVarsにキーと値を書けばConfigMapが自動生成され、secretsにキーとSecrets Managerパスを書けばExternalSecretが自動生成されます。Deployment、Service、HPAも含め、1つのComponentDefinitionから最大7リソースが生成されます(PDBとNetworkPolicyはシナリオ3で追加)。
プラットフォーム側が書くもの ーComponentDefinitionはYAMLのCRDとして定義し、CUEテンプレートをspec.schematic.cue.templateに埋め込みます。CUEテンプレートはoutput(Deployment)、outputs(その他リソース)、parameter(開発者に公開するパラメータ)の3ブロックで構成されます:
output: {
apiVersion: "apps/v1"
kind: "Deployment"
metadata: name: context.name
spec: {
template: spec: containers: [{
name: context.name
image: parameter.image
ports: [{containerPort: parameter.port}]
// envVars を ConfigMap参照の env に展開
// secrets を Secret参照の env に展開
env: [...]
// serviceType に応じて probe を自動切替
livenessProbe: ...
}]
}
}
outputs: {
service: {}
hpa: {}
// envVars があれば ConfigMap を生成
// secrets があれば ExternalSecret を生成
}
parameter: {
image: string
port: *8080 | int
serviceType: *"http" | "grpc" | "custom"
probePath: *"/healthz" | string
disableProbe: *false | bool
minReplicas: *2 | int
maxReplicas: *10 | int
targetCPU: *80 | int
envVars?: [string]: string
secrets?: [string]: string
}このDefinitionの設計ポイントは4つあります:
- serviceTypeによるprobe自動切替: "http" ならhttpGet、"grpc" ならgRPC probeを自動で設定。開発者はserviceType: grpcと書くだけでprobe方式が変わります(シナリオ4で効いてくる設計)
- envVars/secretsの抽象化: 開発者はenvVars: {APP_ENV: production}と書くだけ。ConfigMapの作成、Deploymentへのenv注入、ExternalSecretの生成はすべてDefinitionが処理します。筆者が所属するAmeba基盤でも同様のパターンを採用しており、ExternalSecretはTraitDefinitionとして実装し、開発者はSecrets Managerパスを書くだけでPod注入まで自動化しています
- リソースの一括生成: 1つのComponentDefinitionからDeployment+Service+HPA+ConfigMap+ExternalSecretが生成されます。PDBとNetworkPolicyはシナリオ3で追加します
- CUEのデフォルト値: *8080 | int のように書くと、開発者が省略した場合のデフォルトが定義されます
実運用では、これにIstio設定、Datadog連携、SecurityGroupPolicy、TopologySpreadConstraintsなどが加わり、数百行規模になります。
Crossplane
Crossplaneのアプローチは「KubernetesにカスタムAPIを追加する」ことです。プラットフォームチームがWebApplicationという独自のリソース型を定義し、開発者はそのAPIを使います。Kubernetesの標準API(Deployment、Service等)は一切触れません。
これを実現するために、Crossplaneは3つの概念を使います:
- XRD(CompositeResourceDefinition): カスタムAPIのスキーマを定義します。「WebApplicationリソースにはimage、port、replicas、ingressというフィールドがある」という型定義です
- Composition: カスタムAPIのフィールドを実際のKubernetesリソースにマッピングするルールです。「imageフィールドの値をDeploymentのspec.template.spec.containers[0].imageに入れる」といったパッチの集合体です
- XR(Composite Resource): 開発者が書くもの。XRDで定義されたカスタムAPIのインスタンスです
開発者が書くもの ーXR(19行):
apiVersion: platform.example.com/v1alpha1
kind: WebApplication
metadata:
name: order-api
spec:
image: nginx:latest
port: 8080
replicas:
min: 2
max: 10
cpuTargetPercent: 80
ingress:
host: order-api.example.com
env:
- name: APP_ENV
value: production
- name: LOG_LEVEL
value: infoapiVersion: platform.example.com/v1alpha1が示すように、開発者はKubernetesの標準APIではなく「組織が定義したAPI」を使います。Deployment、Service、HPAといったKubernetesの概念は一切出てきません。Secret(DB_CREDENTIAL)はComposition内のExternalSecretリソースが自動管理するため、XRに含める必要がありません。
プラットフォーム側が書くもの ーXRD(APIスキーマ定義)+Composition(リソースマッピング)。Compositionの一部:
# composition.yaml(抜粋: Deploymentリソースの定義)
- name: deployment
base:
apiVersion: apps/v1
kind: Deployment
spec:
template:
spec:
containers:
- name: app
ports:
- containerPort: 8080
env:
- name: APP_ENV
valueFrom:
configMapKeyRef:
name: "" # パッチで埋まる
key: APP_ENV
patches:
- type: FromCompositeFieldPath
fromFieldPath: metadata.name
toFieldPath: metadata.name
- type: FromCompositeFieldPath
fromFieldPath: spec.image
toFieldPath: spec.template.spec.containers[0].image
- type: CombineFromComposite
combine:
variables:
- fromFieldPath: metadata.name
strategy: string
string:
fmt: "%s-config"
toFieldPath: spec.template.spec.containers[0].env[0].valueFrom.configMapKeyRef.nameCompositionは「ベースとなるリソース+パッチ」の構造です。baseにKubernetesリソースの雛形を書き、patchesでXRのフィールドをリソースの適切な位置にマッピングします。FromCompositeFieldPathは「XRのこのフィールドを、リソースのこの位置に入れる」という宣言です。CombineFromCompositeは複数のフィールドを組み合わせて値を生成します(例: XR名 + -config → ConfigMap名)。
本稿の例ではComposition単体で227行(XRD含む合計で283行)。開発者の負担を最小化する代わりにプラットフォーム側の設定量が最も重いツールです。ただし、一度Compositionを書けば、開発者は19行のXRだけで同じ構成のサービスをいくつでもデプロイできます。
なお、本稿の例はCrossplane 2.xのnamespaced XRベースです。XRDはscope: Namespacedを持ち、開発者はkind: WebApplicationのXRを直接作成します。本文のCompositionスニペットはパッチ構文の概念を理解しやすくするため簡略化していますが、GitHubリポジトリの実装はPipeline mode(function-patch-and-transform)を採用しています。
Kro
Kroのアプローチは「Kubernetesリソースのグループをカスタムリソースとして定義する」ことです。Crossplaneと目的は似ていますが、やり方が違います。
Crossplaneが「パッチでフィールドをマッピングする」のに対し、Kroは「Kubernetesマニフェストのテンプレートをそのまま書く」方式です。テンプレート内の${schema.spec.name}のようなCEL式がパラメータに置き換わります。
Kroは2つのリソースだけで構成されます:
- ResourceGraphDefinition(RGD): プラットフォーム側が書くもの。生成するKubernetesリソースのテンプレート群と開発者に公開するパラメータスキーマを定義します。Kroコントローラはこのスキーマを読み取り、対応するカスタムリソース(例: kind: WebApplication)をKubernetesに登録します
- Instance: 開発者が書くもの。RGDから自動生成されたCRDのインスタンスです
開発者が書くもの ーInstance(16行):
apiVersion: kro.run/v1alpha1
kind: WebApplication
metadata:
name: order-api
spec:
name: order-api
image: nginx:latest
port: 8080
replicas:
min: 2
max: 10
cpuTargetPercent: 80
ingressHost: order-api.example.com
env: production
logLevel: infoCrossplaneと似た構造ですが、KroはRGDのスキーマ定義からカスタムリソースを自動登録します。Crossplane同様、秘匿値はRGD内のExternalSecretテンプレートが自動管理します。開発者は登録されたカスタムリソースのインスタンスを書くだけで、Kroの存在すら意識する必要がありません。
ただし、Kroは2026年4月時点でAlpha段階(v0.9)であり、本番利用にはAPIの安定性やエコシステムの成熟を見極める必要があります。
プラットフォーム側が書くもの ーRGD。Crossplaneとの最大の違いはKubernetesリソースのテンプレートを直接書く点です:
# resourcegraphdefinition.yaml(抜粋: Deploymentリソース)
- id: deployment
template:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ${schema.spec.name}
spec:
selector:
matchLabels:
app: ${schema.spec.name}
template:
spec:
containers:
- name: app
image: ${schema.spec.image}
ports:
- containerPort: ${schema.spec.port}
env:
- name: APP_ENV
valueFrom:
configMapKeyRef:
name: ${configmap.metadata.name}
key: APP_ENVCrossplaneの「base+パッチ」に対して、Kroは「テンプレート+CEL式」です。KubernetesのDeployment YAMLをほぼそのまま書き、パラメータ化したい部分だけを${...}に置き換える。Kubernetes経験者なら「これは普通のDeploymentだ」とすぐに分かります。
${schema.spec.name}は開発者が書いたInstanceのフィールドを参照し、${configmap.metadata.name}は同じRGD内で定義した別のリソース(ConfigMap)の生成結果を参照しています。リソース間の依存関係をKroが自動的に解決し、正しい順序で生成してくれます。
シナリオ1のまとめ

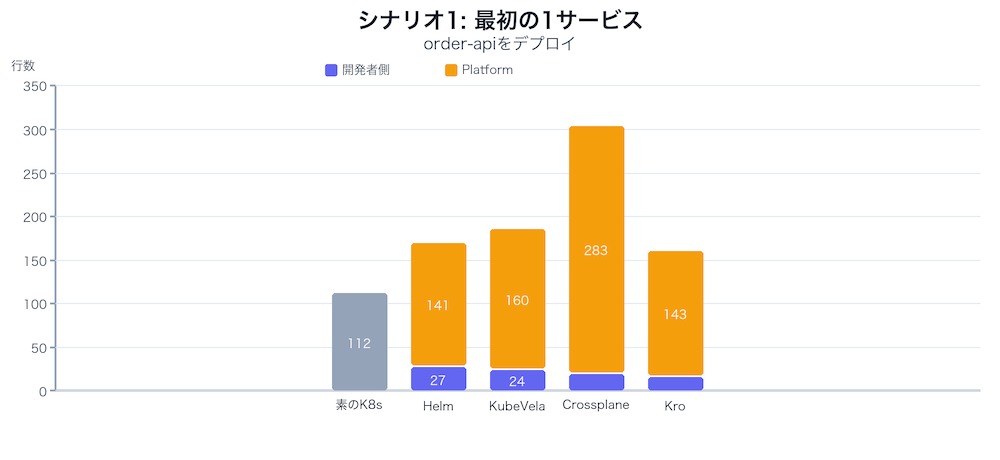
1サービスだけなら、Helmのvalues.yaml(27行)で十分です。Crossplane(19行)やKro(16行)は開発者の記述量が最少ですが、プラットフォーム側の準備が重い。この初期投資が回収されるかどうかは、次のシナリオ以降で見えてきます。
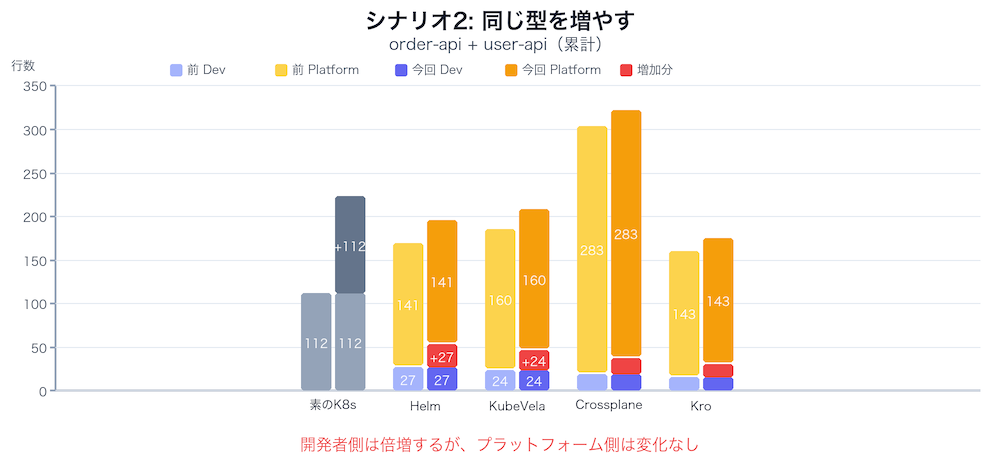
シナリオ2: 同じ型のサービスを増やすとき何が起きるか
order-apiと同じ構成でuser-apiを追加します。イメージ、ドメイン名、DB接続先だけが違います。

どのツールも「定義を再利用して、インスタンスだけ追加する」パターンです。素のKubernetes以外は、プラットフォーム側の作業がゼロ。ここまでは、Helmで十分です。
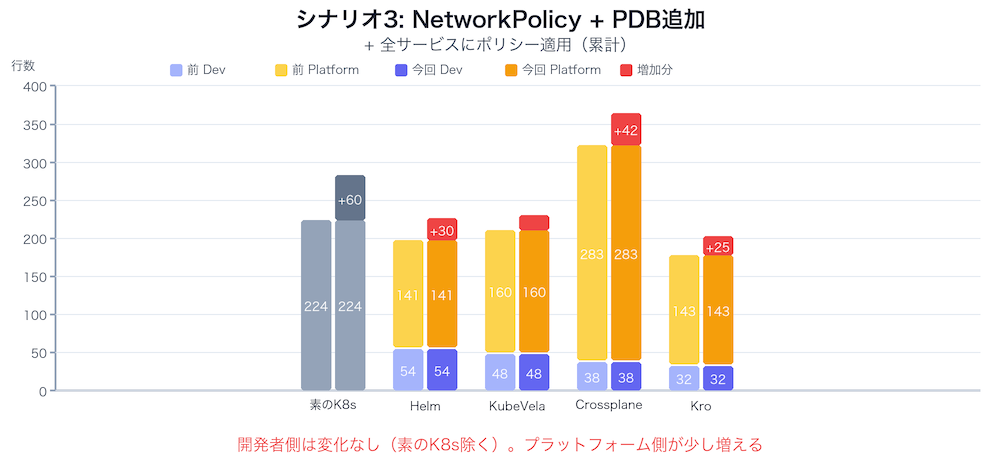
シナリオ3: 全サービスに横断的な変更をどう入れるか
セキュリティチームから「全サービスにNetworkPolicyとPodDisruptionBudgetを追加する」という指令が来ました。
NetworkPolicyはPodへのネットワークアクセスを制御するリソースで、「どこからのトラフィックを許可するか」を定義します。PDB(PodDisruptionBudget)はノードメンテナンス時に「最低何台のPodを維持するか」を保証するリソースです。いずれもアプリケーションの機能には直接関係しませんが、本番環境では必須とされることが多いリソースです。
ここから各ツールの差が明確に分かれます。問いは「この2つのリソースを、既存の全サービスにどう追加するか」です。
素のKubernetes
各サービスのディレクトリにnetworkpolicy.yamlとpdb.yamlを手動で追加します。order-apiとuser-apiの両方に計4ファイルの追加が必要です。サービスが10個あれば20ファイル。漏れなく全サービスに適用する保証は、レビューの網羅性に依存します。
Helm: chartを修正すれば全サービスに反映
chartのtemplates/に2ファイルを追加します。
# chart/templates/networkpolicy.yaml
{{- if .Values.networkPolicy.enabled }}
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: {{ .Release.Name }}
spec:
podSelector:
matchLabels:
app: {{ .Release.Name }}
policyTypes:
- Ingress
ingress:
- from:
- namespaceSelector: {}
ports:
- port: {{ .Values.port }}
protocol: TCP
{{- end }}
# chart/templates/pdb.yaml
{{- if .Values.pdb.enabled }}
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: {{ .Release.Name }}
spec:
minAvailable: {{ .Values.pdb.minAvailable }}
selector:
matchLabels:
app: {{ .Release.Name }}
{{- end }}
# chart/values.yaml に追加
networkPolicy:
enabled: true
pdb:
enabled: true
minAvailable: 1enabled: trueがデフォルトなので、既存の全values.yaml(order-api、user-api)はそのままでポリシーが適用されます。開発者は何もせずにchartをhelm upgradeすれば全サービスに反映されます。
KubeVela: Definition修正で全サービスに反映
ComponentDefinitionのoutputsセクションにNetworkPolicyとPDBを追加するだけです。
// component-webapi.cue の outputs に追加
outputs: {
// ... 既存の service, hpa ...
pdb: {
apiVersion: "policy/v1"
kind: "PodDisruptionBudget"
metadata: name: context.name
spec: {
minAvailable: parameter.minReplicas - 1
selector: matchLabels: app: context.name
}
}
networkpolicy: {
apiVersion: "networking.k8s.io/v1"
kind: "NetworkPolicy"
metadata: name: context.name
spec: {
podSelector: matchLabels: app: context.name
policyTypes: ["Ingress"]
ingress: [{
from: [{namespaceSelector: {}}]
ports: [{port: parameter.port, protocol: "TCP"}]
}]
}
}
}既存のApplication CRは一切変更不要です。Definitionを更新すれば、全Applicationの次回reconcile時にNetworkPolicyが自動生成されます。
Crossplane: Compositionに2リソース追加
CompositionのresourcesセクションにNetworkPolicyとPDBを追加します。
# composition.yaml に追加(抜粋)
- name: networkpolicy
base:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
spec:
podSelector:
matchLabels:
app: ""
policyTypes:
- Ingress
ingress:
- from:
- namespaceSelector: {}
ports:
- port: 8080
protocol: TCP
patches:
- type: FromCompositeFieldPath
fromFieldPath: metadata.name
toFieldPath: spec.podSelector.matchLabels.app既存のXRは一切変更不要。Compositionの1箇所を修正するだけで、全XRに反映されます。
Kro: RGDにテンプレート追加
RGDのresourcesセクションにNetworkPolicyとPDBのテンプレートを追加します。
# resourcegraphdefinition.yaml に追加(抜粋)
- id: networkpolicy
template:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: ${schema.spec.name}
spec:
podSelector:
matchLabels:
app: ${schema.spec.name}
policyTypes:
- Ingress
ingress:
- from:
- namespaceSelector: {}
ports:
- port: ${schema.spec.port}
protocol: TCP既存のInstanceは一切変更不要です。Kroの場合、テンプレートがKubernetesマニフェストそのままなので、NetworkPolicyの仕様を知っていればそのまま書けます。
シナリオ3のまとめ

Helm以降のツールはすべて「プラットフォーム側で1箇所修正 → 全サービスに反映」です。Helmもここまでは問題ありません。次のシナリオで状況が変わります。
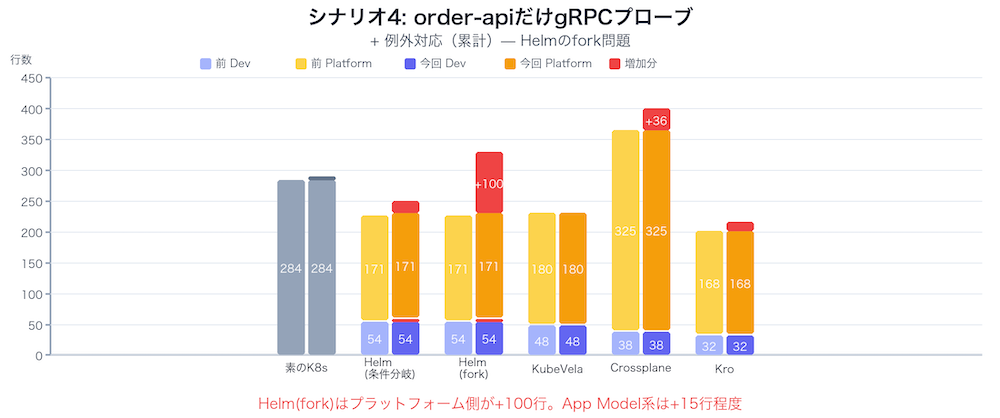
シナリオ4: 1つだけ例外が必要になったらどうするか
order-apiがgRPCサービスに移行し、ヘルスチェックにgRPC Health Checkが必要になりました。user-apiは従来のHTTPのままです。
シナリオ3のNetworkPolicy/PDBは全サービス共通でした。今回は「order-apiだけ」の例外対応です。全サービスに同じ変更を適用するのは比較的簡単ですが、サービスごとに異なる要件を扱うのは別の難しさがあります。
Helm: forkの始まり
現在のchartにはprobe設定のパラメータがありません。対応するには2つの選択肢があります。
選択肢A: chartをforkする
order-api用にchartをコピーし、gRPCプローブを追加します。しかし、forkした瞬間から2つのchartをメンテナンスする必要があります。シナリオ3でNetworkPolicyを追加したとき、元のchartだけでなくfork側にも同じ修正が必要です
選択肢B: chartにprobe設定を追加する
template に条件分岐を入れます:
# chart/templates/deployment.yaml(probes対応版)
{{- if .Values.probes.enabled }}
readinessProbe:
{{- if eq .Values.probes.type "grpc" }}
grpc:
port: {{ .Values.port }}
{{- else }}
httpGet:
path: {{ .Values.probes.httpPath | default "/healthz" }}
port: {{ .Values.port }}
{{- end }}
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
{{- if eq .Values.probes.type "grpc" }}
grpc:
port: {{ .Values.port }}
{{- else }}
httpGet:
path: {{ .Values.probes.httpPath | default "/healthz" }}
port: {{ .Values.port }}
{{- end }}
initialDelaySeconds: 15
periodSeconds: 20
{{- end }}
# order-api の values.yaml に追加
probes:
enabled: true
type: grpcこれでforkは避けられますが、templateの条件分岐が増えます。gRPCプローブ対応だけでDeployment templateに約20行のif/elseが追加されました。
今後「WebSocketサポート」「GPU要件」「Sidecar注入」と例外が増えるたびに、templateは条件分岐だらけになります。あるいはforkが増えるか。どちらに転んでもchartのメンテナンスコストは際限なく増加していきます。
実務で使われる緩和策
Helm自体にも、この問題を軽減するパターンがあります。Library charts(type: library)でヘルパー関数を共通化し、役割ごとにチャートを分割する方法。ArgoCD環境ではPost-renderer+Kustomize overlayでchart本体を変更せず特定サービスに差分を当てるパターン。values.schema.json(またはYAMLで管理しJSON生成する方式)で開発者が書けるキーを厳密に制限するアプローチ。例えば、Loglassの事例(Kubernetes Novice Tokyo #40)ではcommon/base/stateless/stateful等にチャートを分割しcommonライブラリがSecurityContext・NetworkPolicy・Datadog連携を自動適用する設計で、開発者が書くvaluesは約20行に収まっています。
ただし、こうした工夫を重ねても根本的な制約は残ります。Helmの設定は最終的にchart template+values+overlay+schema+CIの複数レイヤーに分散し、「この設定がどのサービスにどう影響するか」の追跡が難しくなります。Definition層の一元管理とは異なる設計哲学であり、それがHelmの強み(透明性、helm templateで手元確認できる即座性)でもあり、弱み(設定の散在)でもあります。
Crossplane: Compositionにoptionalパッチ追加
CrossplaneではXRD(APIスキーマ)にprobeTypeフィールドを追加し、Compositionで「probeTypeが指定されたときだけパッチを適用する」条件付きルールを書きます。
# XR に1行追加するだけ
spec:
probeType: grpc # order-apiだけ追加。user-apiは書かなければデフォルト(なし)
# composition.yaml に追加(抜粋)
- type: FromCompositeFieldPath
fromFieldPath: spec.probeType
toFieldPath: spec.template.spec.containers[0].readinessProbe
transforms:
- type: match
match:
patterns:
- type: literal
literal: "grpc"
result: '{"grpc":{"port":8080}}'
- type: convert
convert:
toType: object
format: json
policy:
fromFieldPath: Optionalpolicy.fromFieldPath: Optionalがポイントです。これにより、probeTypeが指定されていないXR(user-api)ではこのパッチ全体がスキップされます。order-apiだけがprobeType: grpcを書いているので、order-apiだけにgRPCプローブが適用されます。
Kro: RGDにCEL条件分岐
RGDのスキーマにprobeTypeフィールドを追加し、テンプレート内でCEL式の条件分岐を使います。
# RGDスキーマに追加
spec:
probeType: string | default=none # "grpc", "http", "none"
# instance に1行追加
spec:
probeType: grpc # order-apiだけKroの場合、RGDテンプレート内でincludeWhenやCEL条件を使ってプローブの有無を制御します。定義の1箇所を変えるだけで、全InstanceがオプションとしてprobeTypeを使えるようになります。
KubeVela: serviceTypeを変えるだけ
シナリオ1で見たカスタムDefinitionのserviceTypeパラメータがここで効きます。開発者はApplication CRの1行を変えるだけです。
# order-api の properties を変更
properties:
serviceType: grpc # http → grpc に変えるだけDefinitionがserviceType == "grpc"を検出して、自動的にgRPCプローブを設定します。プラットフォーム側の修正は不要。シナリオ1でDefinitionを設計する段階で、将来の例外に備えた拡張ポイント(serviceType)を用意しておいた結果です。
なお、これはKubeVela固有の優位ではありません。CrossplaneのXRDにprobeTypeを最初から含めておけば同じことができます。ツールの差というよりDefinition設計の先見性の差です。
シナリオ4のまとめ

4つのシナリオが示すもの
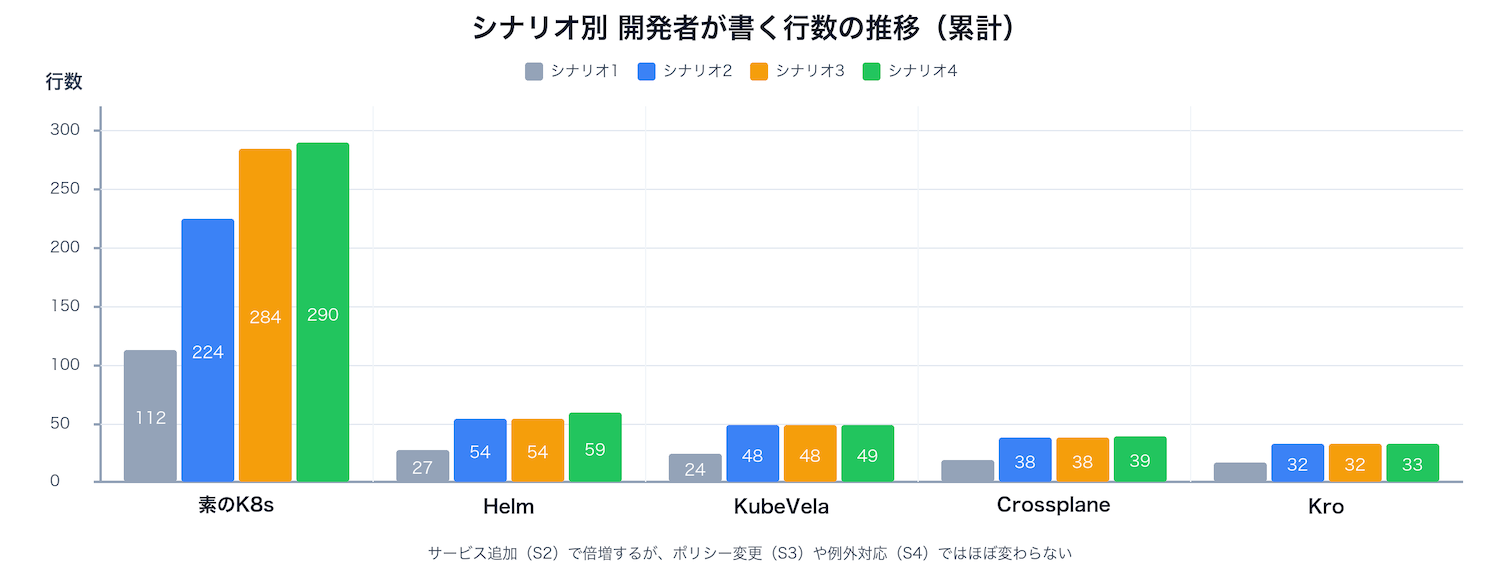
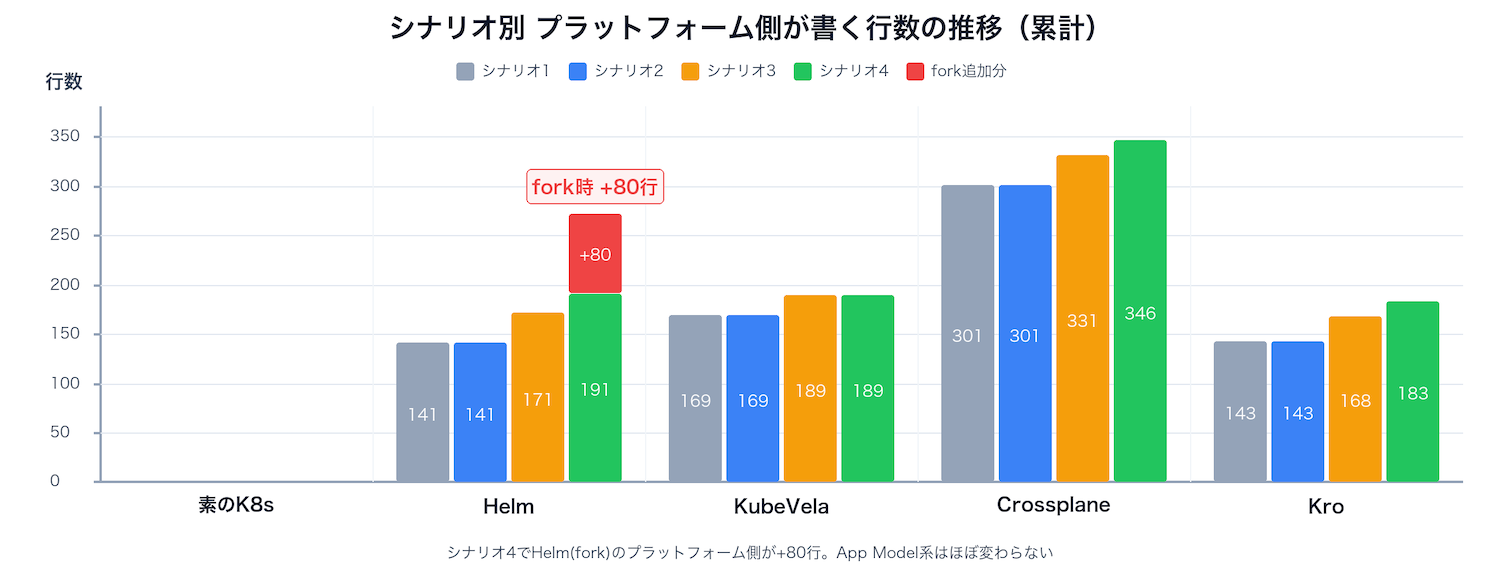
シナリオ3まではHelm含め全ツールが緩やかに増加しています。しかしシナリオ4でforkが発生すると、Helmのメンテナンスコストが一気に跳ね上がります。
シナリオ1〜2では各ツールに大きな差はありませんでした。差が開いたのはシナリオ3(全体ポリシー)とシナリオ4(例外対応)です。Helmの課題はchartの柔軟性がGo templateの表現力に制約されることです。パラメータとして公開されていない設定が必要になったとき、chartをforkするか、templateを複雑化するかの選択を迫られます。サービスの種類とポリシーの変更頻度が増えると、この問題は加速度的に重くなります。
Application Model系のツール(KubeVela、Crossplane、Kro)は、この問題を「Definition層の一元管理」で解決します。定義が1箇所に集約されているため、横断的な変更のコストがサービス数に依存しません。その代わり、Definition層を書くプラットフォームエンジニアのスキルと工数が必要です。CUE(KubeVela)、Composition patches(Crossplane)、CEL(Kro)はいずれも独自の学習コストがあります。
特にKubeVelaは、本稿で扱ったComponent/Traitの枠組みに加えて、Application CRにはspec.policies(配置制御、override)とspec.workflow(承認フロー、カナリアデプロイ等のステップ制御)という追加の抽象層があります。実運用ではこれらを組み合わせることになり、開発者の学習対象がComponent → Trait → Policy → Workflowと4層に膨れ上がります。筆者の経験では、この抽象の重なりがKubeVelaのUXを損なう主要因の1つになっています。「開発者が何を知らなくて済むか」を追求した結果、プラットフォームチーム側が知るべきことが増えすぎるというジレンマです。
いつApplication Modelへの投資が回収されるか。定量的な目安としては「サービス数×ポリシー変更の頻度×例外の種類」が出発点になります。しかし実務では、これに加えてプラットフォームチームの規模(CUEやCompositionを書けるエンジニアが1人なら属人化リスク)と既存Helmチャートからの移行コストも重要な変数です。10サービスでポリシーが四半期ごとに変わり、3種類の例外が存在し、かつプラットフォームチームに2名以上の専任がいるならDefinition層の初期投資は回収される可能性が高いと考えます。逆に3サービスでポリシーが年1回しか変わらないなら、Helmで十分です。
また、本稿の4シナリオはDefinition設計の進化に焦点を当てていますが、実運用ではさらに3つの課題がツール選定に影響します。
- ドリフト検出: サーバーサイドコントローラ(KubeVela/Crossplane/Kro)はreconcileで手動変更を自動修復できますが、Helmはドリフトを検出すらしません
- テナントオンボーディング: 開発チームが自分で新サービスをデプロイするセルフサービス体験は、XRやInstanceのようなnamespace-scoped APIを持つツールが有利です
- Definition破壊的変更: フィールド名変更や廃止が発生したとき、100サービスをどう移行するかは無視できないコストです。これらは第3回以降で掘り下げます
まとめ
Application Modelを評価するとき「1サービスの記述量」だけを見ても意味がありません。プラットフォームが成長する過程 -サービスの追加、ポリシーの適用、例外への対応ー を通じて、初めて各ツールの設計判断の意味が見えてきます。
各ツールの性格を踏まえた選択の目安を示します。Kubernetesリソースだけでなくクラウドインフラも統合管理したいならCrossplane。Kubernetesネイティブに最小限の仕組みでカスタムAPIを作りたいならKro(ただしAlpha段階)。OAMのComponent/Traitモデルとチーム内にCUEの知見があるならKubeVela。いずれも既存のHelmチャートと並行運用できます。ArgoCD/Fluxとの連携については、Helmはクライアントサイドなので従来通り、KubeVela/Crossplane/Kroはサーバーサイドのコントローラなのでreconcileの競合に注意が必要です。
なお、本稿の比較はグリーンフィールド(新規構築)を前提としています。既存のHelm chartからの移行コスト、抽象度が深いツールでのデバッグの難しさ(Compositionのパッチが想定通り動かないとき、CUEのevalが通らないときの調査コスト)は、ツール選定において同等に重要な検討事項です。これらは第3回以降の各ツール深掘りで扱います。
次回はKubeVelaのdeep diveです。OAM Specの唯一の実装として始まったKubeVelaが、フルプラットフォームへ進化する過程でどのような複雑さを抱えたのか。高度なユースケース、設計上の制限、実運用で頻出する悩みを整理しながら、何を得て何を失ったのかを検証します。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者
筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
