| ||||||||||||
| 1 2 3 4 次のページ | ||||||||||||
| はじめに | ||||||||||||
第2回と第3回に渡り、サーバクラスタを使ってデータを分散配置し、全体として大きなデータベースを構築する方法について解説しました。今回は、サーバクラスタを使ってデータベースの二重化、三重化を行う方法について解説します。 データベース全体のコピーを作ったり、そのコピーのことをレプリケーションと呼びます。 | ||||||||||||
| データベースのコピーが必要なわけ | ||||||||||||
データベースのテーブル設計をする上で「データの正規化」が重要だと聞いたことがある人は多いと思います。「データの正規化」で重要なことの1つに「同じデータは複数テーブルで重複させない」という考えがあります。 図1に示すように、「住所」を「顧客テーブル」と「注文テーブル」の2ヶ所に重複させておくと、お客様の住所を変更するアプリケーションは「すべて」「例外なく」この2つのテーブルの情報を「同じ」に保っておかなければならなくなります。 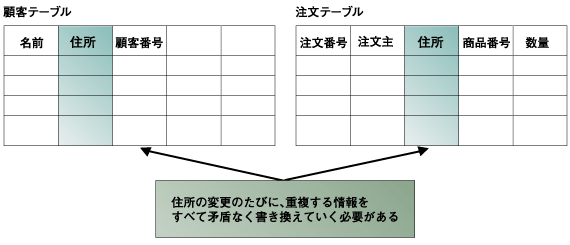 図1:重複のあるデータベース設計 (画像をクリックすると別ウィンドウに拡大図を表示します) このようなことを避けるために、例えば「住所」は「顧客テーブル」だけに格納して、「注文テーブル」にはお客様の「顧客番号」を格納しておき、この顧客番号からお客様の住所を調べるようにします(図2)。 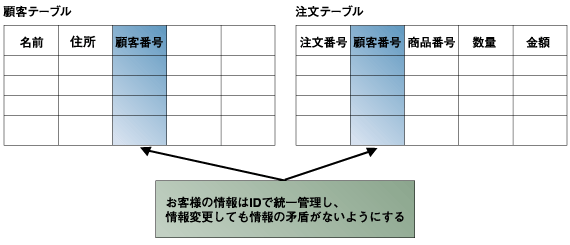 図2:テーブル間で重複する情報をなくす設計 (画像をクリックすると別ウィンドウに拡大図を表示します) 一方「レプリケーション」は、データベースのデータを二重にも三重にもコピーしておく方法です。上記のテーブル設計の原則とは矛盾するようですが、「レプリケーション」はSQL文の処理系の内側で実行されるので、アプリケーションレベルでは見えないのが、「正規化」とは違うところなのです。このようにあえてデータベースのコピーを持っておくことが必要な理由には、次のようなものがあります。
| ||||||||||||
| どちらもデータベースレプリケーションでは重要な機能です。 | ||||||||||||
| 1 2 3 4 次のページ | ||||||||||||
| ||||||||||||
| ||||||||||||
| ||||||||||||
-
人気記事ランキング
-
-
連載


新着記事
「Proxmox VE」とは? 製品群の全体像と仮想化基盤として注目される理由 7月31日 6:30 LFがOSSの脆弱性協調対応イニシアティブ「Akrites」を発足、CRA準備状況レポートは改善どころか悪化、ほか 7月31日 6:20 NVIDIAら37社が「Open Secure AI Alliance」設立――AIエージェントのセキュリティは重みの非公開では守れない 7月30日 6:20 【クラウドネイティブ会議】厳格な統制と開発者体験を両立する、Wiz Baseにおけるゴールデンパスの実践 7月30日 6:00 その「ソーシャルログイン」は大丈夫? OAuth/OIDC実装の3つの落とし穴 7月29日 6:30