画像異常検知ソリューション「gLupe」の裏側
画像異常検知ソリューション「gLupe」の裏側
続いて株式会社システム計画研究所の井上 忠治氏が登壇し、自社製品の製造業向け外観検査ソフトウェア「gLupe(ジールーペ)」を紹介した。ディープラーニングを応用した高性能エンジンを使用し、ルールベースや画像処理などの従来手法では検出が困難だった不良品の検出を実現した。また、わずか数十枚の正常データで学習可能な独自技術により、製造現場へスピーディーに導入できる。

次にgLupeのデモンストレーションに移り、30枚の正例データ(良品の画像)で学習モデルを作成した。CPUでの学習だったので少し時間がかかったが、それでも1分程度で学習が終了した。CUDA対応のマシンでは数秒程度で終わるそうだ。
このような画像データの異常検知をディープラーニングで行う場合、一般的に正例データを数千枚〜数万枚、負例データも同様に数千枚〜数万枚必要とされている。それだけのデータから学習すると数十時間、長ければ数日要する場合もある。gLupeは数十枚の正常データだけ良いので、学習データの収集コストを大幅に減らすことができる。さらに、学習時間が短いことで速やかに評価できるのも特徴だ。
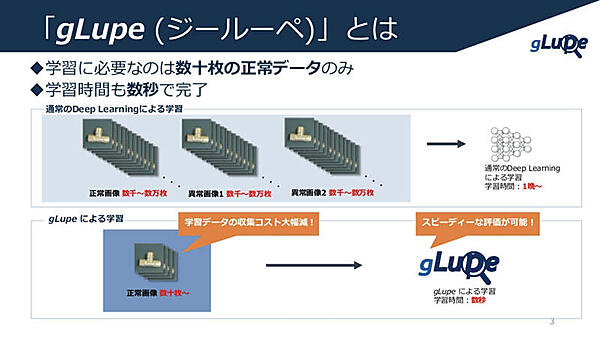
汚れがある異常データを3枚、学習に使っていない正常データを2枚の計5枚でモデルの評価を行った。1ピクセルごとに異常度を0~1の範囲で持っており、下のスライドバーで閾値を調整する。今回は0.59に設定したので、それを超えた部分が赤く表示される。正常データはどこも赤く表示されず、異常データは汚れたところだけ赤く表示された。

gLupeにはデモンストレーションで使用した学習・評価用アプリケーションに加え、エクスポートした結果から推論するSDKが用意されている。株式会社システム計画研究所はgLupeとソフトウェア開発技術の提供だけでなく、gLupe(開発環境)と開発サポートだけの提供も行っている。井上氏は「gLupeで開発できる人を増やしたいので、今悩んでいる課題に活用してほしい」と来場者に呼びかけた。
これまで全数目視で検査していた工程を少しでも自動化したいという要望が多い中で、前述した通りgLupeは画像処理ベースの手法ではうまくいかなかった検査を自動化できる。これにより、人件費の削減、人手不足の解消、検査員の教育コスト削減などの効果が期待できる。昨今のAI / ディープラーニングブームのおかげで、これまで半ば諦めていた課題の自動化への期待が高まっており、普通にアプローチしても解決できない難しい問題が持ち込まれてくることが多いという。gLupeに限らず、アルゴリズムの特徴を理解した上で最適な提案・アプローチをしていくことが重要だと述べた。
ここで、gLupeのアルゴリズムの話に移った。入力は画像のみを想定していて、当たり前だが画像に情報として残っていないものは検知できない。検出したい異常がしっかり写るように撮影できているかがポイントになる。gLupeはCNNを応用しているためそれなりに柔軟性はあるが、やはり学習データのバリエーションは最小限に抑えたい。データ数でバリエーションをカバーするのは現実的ではなく、もし大量のデータが集まったとしてもデータクレンジングやアノテーションする手間を考えれば、カメラの位置やパラメータなどを固定して撮影する方が効率的だという。また、入力する画像の解像度が大きすぎる場合は分割する、不鮮明な画像は精鋭化フィルタをかけるといったように、状況に応じて前処理を行うことも重要だと述べた。
以上のようにgLupeの特徴をおさえた上で活用すれば、従来は自動化困難だった検査項目を自動化できる可能性がある。さらに、少量の学習データを短時間で学習できるので、試行錯誤のサイクルを素早く効率的に回すことができると強みをアピールした。
開発中の新機能として、異常データの学習と異常タイプ分類を紹介した。異常パターンが一定で正常パターンに多くのバリエーションがある場合、異常データを学習して多少自由に撮影された画像の異常も検知できる。目視で異常タイプを容易に分類できるものは、異常タイプごとに数十枚のデータで学習して分類できる。さらに、Microsoft Azureを使って学習と推論をクラウド上で行えるようにする取り組みを進めることを明らかにした。

ALBERTにおける異常検知ケーススタディ
最後に登壇したのは、株式会社ALBERTの安達 章浩氏。同社の事業内容を中心に、異常検知の事例と知見を紹介した。「分析力をコアとするデジタルソリューションカンパニー」を事業コンセプトに、機械学習やAIを用いたアルゴリズムを提供している。アルゴリズムの設計からシステムへの組み込みまで一気通貫して行えるのが強みだと語った。

2005年に創業してから毎年200を超えるプロジェクトを遂行している。様々な事業ドメインの課題をこなしており、未経験のプロジェクトはほとんどないという。今回は画像解析や異常検知といったアナリティクス案件の分析手法を見ていく。
異常検知は他の大多数のデータとは振る舞いが異なるデータを検知する技術のことだと説明し、クレジットカードの不正使用検知、システムの故障予知、異常行動検知など様々な分野でこの技術が用いられていると述べた。機械学習による異常検知の手法は大きく分けると、統計モデルに基づくもの(ホテリング理論等)とデータ間の距離に基づくもの(k近傍法やlof法等)の2つに分類できる。
主観に左右されない異常データを見つけるための基準が必要で、統計モデルを用いて客観的に評価できるようにしたのがホテリング理論だ。ホテリング理論に限られたことではないが、正規分布を仮定していることがミソだという。正規分布のデータは少なく、特にビッグデータでは皆無といっても過言ではない。ホテリング理論は古い理論で今となってはほとんど使われていないが、異常検知の考え方を学ぶには良い例だと説明した。
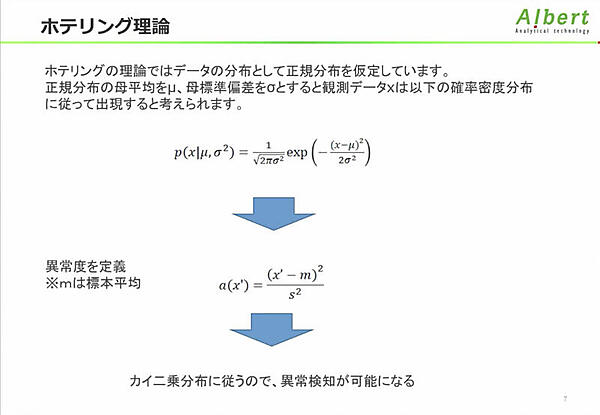
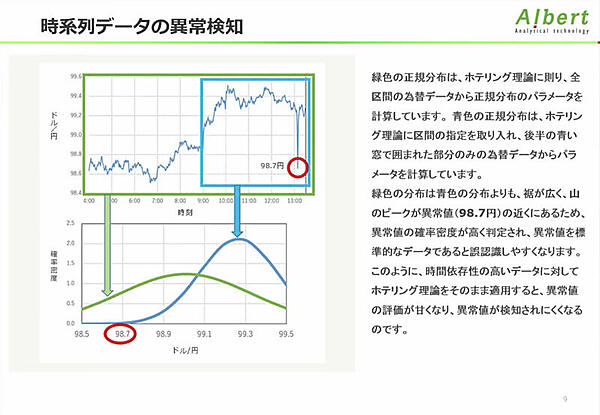
ホテリング理論においてデータは平均値、分散のパラメータが固定の正規分布に従うと仮定している。時系列データのパラメータは動的に変化するため、異常値の評価が甘くなる。全区間の為替データにホテリング理論を適用した例をみてみると、ドル/円が急激に落ち込んでいる部分を異常として検知できない。時間依存性の高いデータに対しては、動的な基準を更新していくモデルが必要だと述べ、時系列データにおける異常検知でよく使われる手法の紹介に移った。
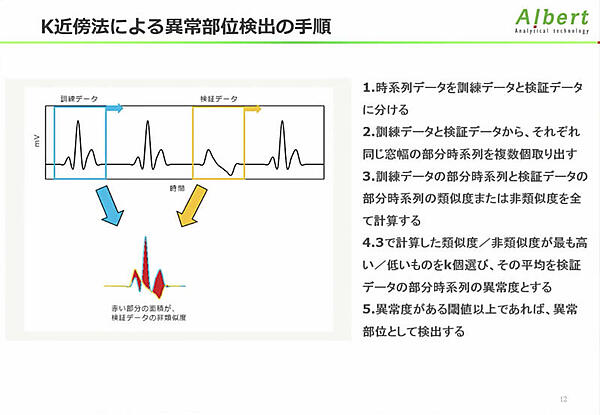
異常部位検出は異常が起きている部分時系列を検出する手法だ。一般的にはk近傍法を用いて部分時系列が異常かどうか評価する。例として心電図のデータを示した。訓練データと検証データで差分の面積計算をイメージするとわかりやすいだろう。波形が異なれば面積が異なるので、計算した差分がある閾値を超えた場合、異常部位として検出する。
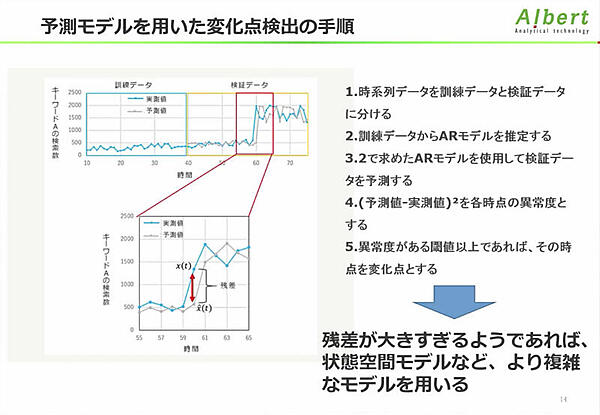
変化点検出は、先ほどの為替データのように急激に変化した点を検出する手法だ。基本的に自己回帰モデル(AR)や自己回帰移動平均モデル(ARMA)などの予測モデルを使い、モデルの予測値と実測値の残差平方を異常度としてみる。予測モデルが正しくなければ、あらゆる点で乖離を起こして変化点を検出できないので、予測モデルの正確さが重要だ。
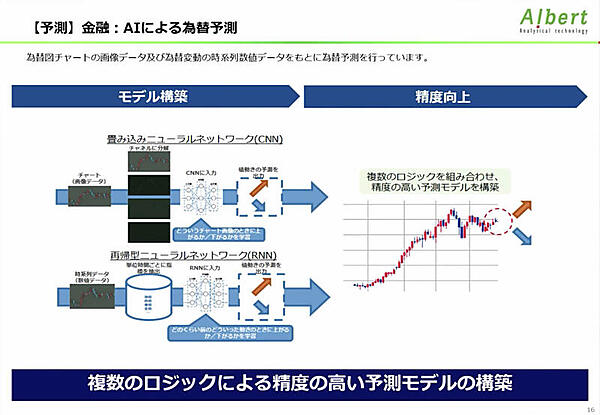
ここで話題は、同社が展開するディープラーニングのビジネス応用支援サービスの紹介に移る。AIによる為替予想では、為替チャートの画像データと為替変動時の時系列数値データを元に為替予測を行う。畳み込みニューラルネットワーク(CNN)と再帰型ニューラルネットワーク(RNN)を組み合わせたアンサンブルモデルで高精度の予測モデルを構築することも可能だと語った。
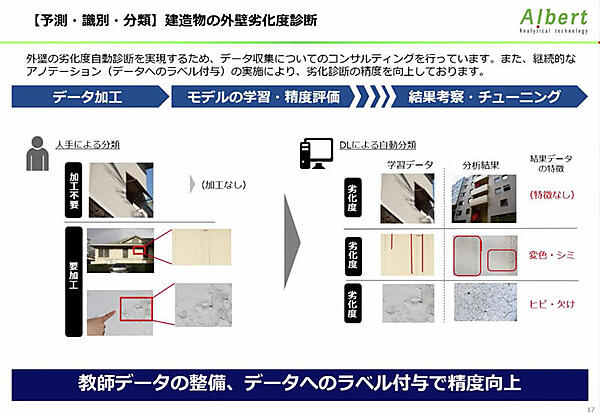
建造物の外壁劣化度は画像データを用いる。診断前のセッションでも触れた通り、撮り方の標準化が絶対的な条件だ。例えば傷を指で差している画像は、指が異常だと判断されかねない。しっかりとしたデータがあれば、高い精度が期待できるという。
UNIXの不正コマンド検知は、サーバに対するコマンドの順序をみて不正処理を検知する。これは隠れマルコフモデル(HMM)で高い精度を実現し、検知自動検知システム化に貢献した。ディープラーニング以外にも異常検知モデル構築のお手伝いができると述べ、セッションを締めくくった。

Deep Learning Labはわずか6ヶ月で会員数が1700人を突破。昨今はディープラーニングブームということもあり、非常に勢いがあるコミュニティだ。日本全国で12回実施されるコミュニティイベント、エンジニア向け課題解決ナイト、業種ごとの分科会活動が予定されている。興味がある方はDeep Learning Labの公式サイトをチェックしてほしい。

- この記事のキーワード
この記事をシェアしてください
関連記事
バックナンバー
この記事の筆者

筆者の人気記事
Deep Learning Lab初のエンジニア向けイベント「異常検知ナイト」レポート
2018年5月15日 16:00
Azure+クラウド型電子カルテにおけるリソース利用効率の課題と改善への道すじ
2019年6月13日 6:00
SIの労働生産性を高めるIaCとは?ITエンジニアのためのコミュニティ「IaC活用研究会」キックオフイベントレポート
2018年4月12日 18:40
話題のDockerの魅力とは? OSSインフラナイター vol.1 レポート
2017年7月14日 0:15
ITエンジニア必見の夏の祭典「July Tech Festa 2018」レポート
2018年10月25日 6:00
「FFXV」に活かされたAIとは?「Pokémon GO」に続くARゲームの登場も間近か…日々進化するゲーム業界のAI・ARに迫る
2017年12月5日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
