ITエンジニア必見の夏の祭典「July Tech Festa 2018」レポート
7月に開催されたJuly Tech Festa 2018の基調講演と招待講演のレポートを紹介する。
2018年10月25日 6:00
7月29日「July Tech Festa 2018」が開催され、猛暑日ながら活気を見せた。「最高のITエンジニアリングを身につける!」をスローガンとして掲げ、変化が絶えないITトレンドの情報共有の場となることを目的としたイベントだ。このレポートでは、基本講演と招待講演の内容をお届けする。
Preferred Networksの機械学習クラスタを支える技術
基本講演のスピーカーは、株式会社Preferred Networks(以下、PFN)の大村伸吾氏だ。まず、同社の紹介からスタートした。同社のミッションは「IoT時代に向けた新しいコンピュータを創造する」と「あらゆるモノに知能をもたせ分散知能を実現する」の2つで、IoTと分散機械学習とを掛け合わせた領域(交通システムや産業用ロボット、バイオヘルスケアなど)に注力している。

株式会社Preferred Networksエンジニアの大村伸吾氏
さらに大村氏は、具体的な取り組みを3点紹介した。1つ目はピッキング自動化だ。乱雑に置かれた部品をつかむ行為は人間には容易だが、現在のロボットで実現するのは難しい。そこで深層学習の結果を元に、ピッキング精度を向上させた実験である。
2つ目は自動運転のデモンストレーション。人間が運転するクルマとエージェントが運転する車は、最初のうちはぶつかってしまうが、強化学習によって最終的にはぶつからないようにエージェントが運転する。
そして最後の3つ目が、自然言語によるロボット制御だ。自然言語はボイスコマンドではなく、日常の意思疎通で使われる言語であり、例えば「茶色のふわふわしているものを右下の箱に動かして」といった概念的表現を理解して、動作する。
このような深層学習を支援しているのがChainerだ。Chainerは、同社が開発を主導している深層学習向けオープンソースソフトウェアライブラリである。NumPyのインタフェースでPythonにデータをインプットできるだけでなく、これをGPU上で高速に実行できるCuPyも利用できる。また、他のフレームワークは事前にニューラルネットワークの構造を定義しておいてから実行する「Define-and-Run」という概念であるのに対し、Chainerはプログラムを実行しながらニューラルネットワークを構築して学習を進める「Define-By-Run」という概念であり、動的構造が直感的かつ容易に実現できるのが特徴だという。

Chainerの特徴
Chainerには、ChainerMN(分散深層学習)、ChainerRL(深層強化学習)、ChainerCV(画像認識アルゴリズム・データセットラッパー)の追加パッケージが用意されている。本セッションで解説されたChainerMNは、NVIDIAのNCCL(NVIDIA Collective Communications Library)やCUDA-Aware MPIなどの技術で高速に実行でき、Chainerの柔軟性を損なわずに動的なネットワークで分散学習することができる。また、既存のコードを少し書き換えるだけで使えるというメリットもある。そして肝心な性能についても、以下のスライドを見ればわかるように、GPU数に比例して高速化でき、なおかつ精度も保っている。

ChainerMNの性能
PFNでは、MN-1と呼ばれる機械学習クラスタを運用している。構成はGPU(NVIDIA Tesla P100:RAM 12GBモデルとRAM 16GBモデルが混在)を8台搭載したサーバをInfiniBandを用いて16台接続してグループを形成し、このグループ8セットをトップのInfiniBandに接続している。その性能は折り紙つきで、LINPACK BenchmarkでTop 500リストのIndustry領域で国内1位に認定されたり、ImageNetの学習速度で世界最速を記録したりしている。
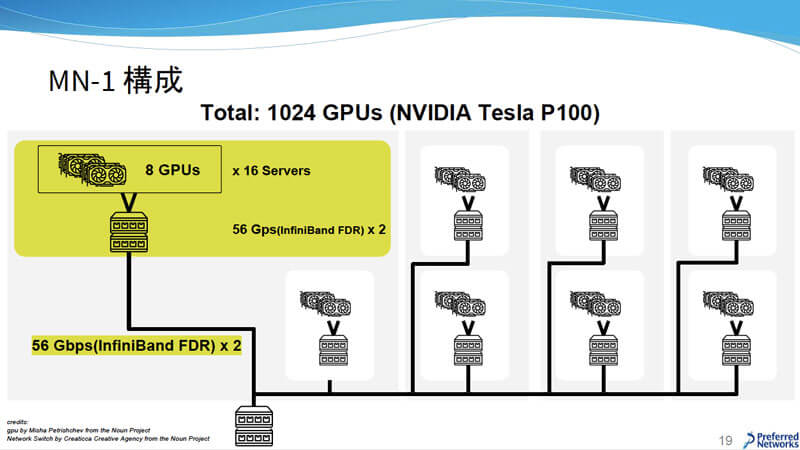
MN-1の構成
PFNがこのような自社クラスタを重視する理由は、計算力こそが競争力の源であり「大量の計算機を使って誰にも成し遂げられなかったことをしたい」という強い想いがあるからだという。2017年5月頃、NIPS論文提出の締め切り直前に大手クラウドサービスのGPUが枯渇したニュースを取り上げ、日々の研究で日常的に16GPU、32GPUの大規模な学習ができる環境を自社で保有することの重要さを説明した。
ChainerMNを最大限に活用するには、高速な通信環境が望ましい。先ほど紹介したMN-1のインターコネクトで使われているInfiniBandは、クラウドで自由に使える技術ではない。さらに、クラスタ調達からアルゴリズムまで様々な技術のバックグラウンドを持つメンバーが集結することが、新しいものを生み出すことに繋がるという。
PFNの社内クラスタサービスは、オンプレミスだけでなくクラウドも活用している。例えばAWSではPrivate Docker Registry「HARBOR」と継続的インテグレーションツール「Jenkins」が使えるようになっているし、Microsoft Azureではbot経由でインスタンスがオンデマンドに立ち上げられるようになっている。自社クラスタのMN-1は、ストレージに分散ファイルシステムの「GlusterFS」と「HDFS」、コンテナには「Docker」、コンテナオーケストレーションシステムには「Apache Mesos」と「Kubernetes」、その上に内製ジョブ実行ツールが用意されている。そしてこの内製ジョブ実行ツールが、本セッションのメインテーマである。
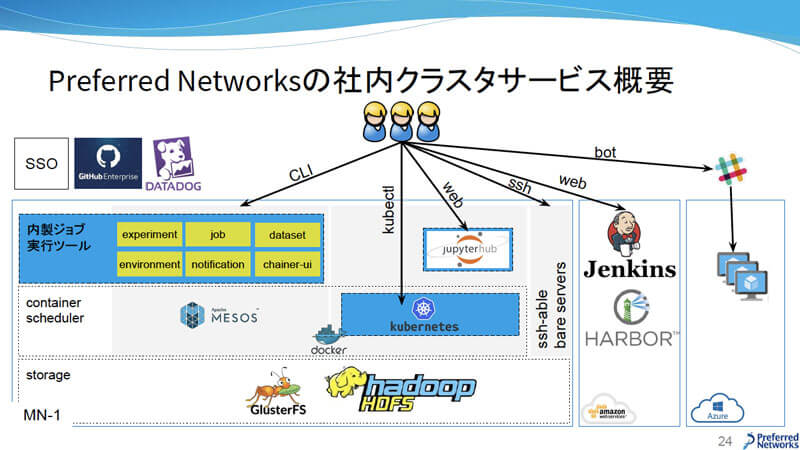
PFNの社内クラスタサービス概要
PFNには多種多様な研究者とエンジニアが在籍しており、彼らのリテラシーレベルも様々だ。機械学習のツールを開発する際には、拡張性があって様々なユースケースに対応できるプラットフォームの構築が理想ではあるのだが、PFNでは各々のリテラシーレベルで使いやすいツールをいくつか用意している。
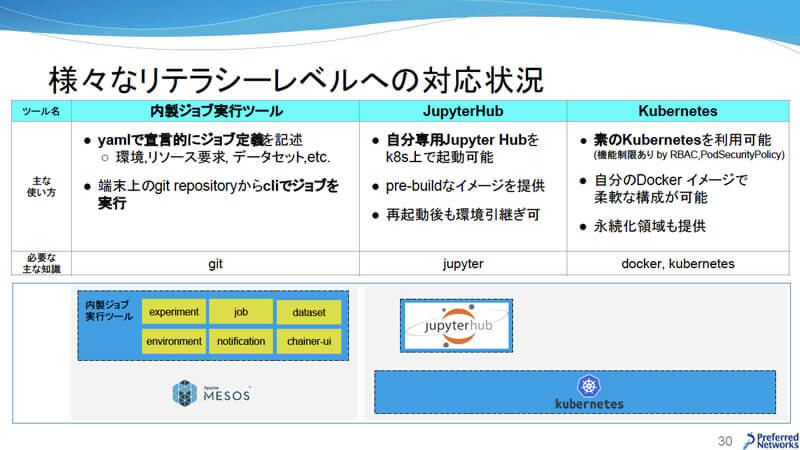
様々なリテラシーレベルへの対応状況
一般的な機械学習のワークフローとPFNの機械学習のワークフローを比較してみると、スケーラブルな深層学習/機械学習を行うため、下の図における中段にフォーカスしていることがわかる。上段はデータセットの管理機能のみを提供している。前述のように、様々なリテラシーの社員が在籍していることから、要求も様々であることが理由だという。下段はモデルをサービスとして展開することが少ないため、プラットフォームとしてはサポートしていない。
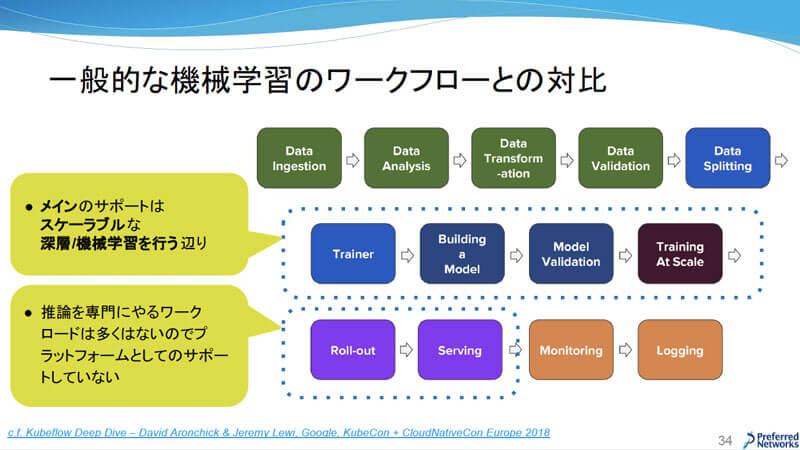
一般的な機械学習のワークフローとの対比
続いて話題はジョブの再実行性に移った。ローレイヤーから見てみると、CPUのマルチスレッドにおけるタスク実行順序は制御できない。さらに、GPU内での重み付けの計算は速度を優先するため再現性は保証されていない。しかし、ニューラルネットワークとデータセットはメタデータとして保存しておき、フレームワークはDockerイメージを使うことで非決定性の要因を排除できる。再現性までは担保できないが、再実行性は担保できるというわけだ。

PFNのジョブツールでは再実行性(Repeatability)を提供
次に、GPUをクラスタで利用する方法が紹介された。MesosはログをAPIサーバ経由でユーザに見せたいという要件がある。ジョブ作成の要求でMesos ContainerizerがMesos Containerを立ち上げるが、そこで直接nvidia-dockerを動かさず、ジョブ実行ツールのヘルパプロセスがnvidia-dockerを動かしている。Mesos Containerの上で使用するGPUは、Linuxカーネル機能であるcgroupで制御している。
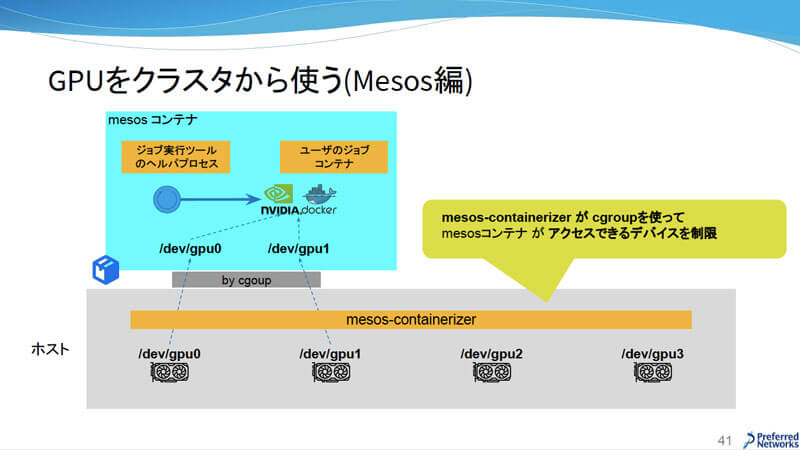
GPUをクラスタから使う(Mesos編)
一方Kubernetesは、Mesosと違った構成になっている。各ノードにPodの起動や管理を行うエージェントのkubeletがいて、nvidia/k8s-device-pluginのプロセスがGPUのリソースを検出して、コンテナに割り当て可能なGPUのdevice idをやり取りしている。
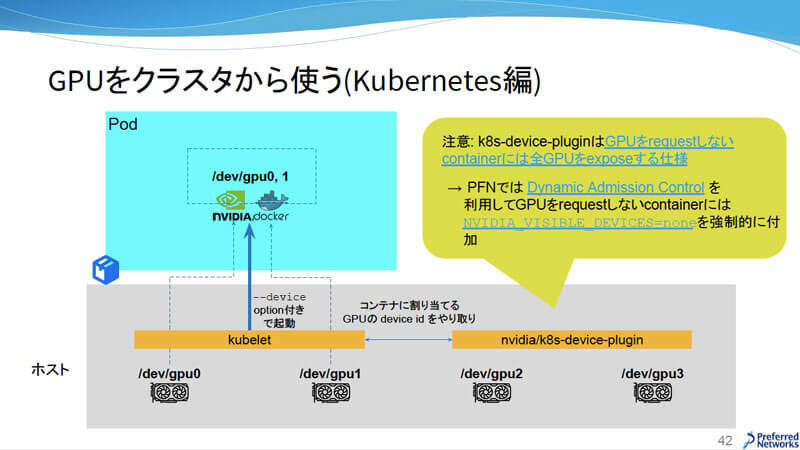
GPUをクラスタから使う(Kubernetes編)
InfiniBandからクラスタを利用する場合は、Mesos ContainerizerがInfiniBandのデバイスを見せてくれるので、ジョブ実行ツールのヘルパプロセスが「--device option」付きでユーザのジョブコンテナを起動する。
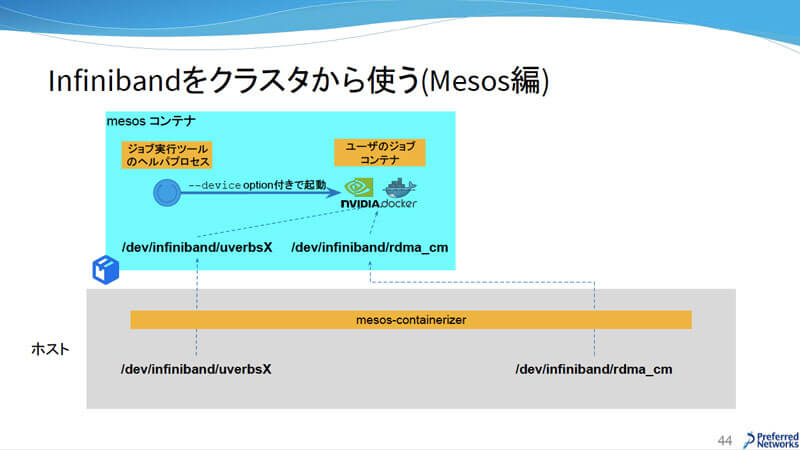
InfiniBandをクラスタから使う(Mesos編)
Kubernetesでは、無制限でスケジュールできる計算リソースは未サポートとなっている。そこで、ホストのInfiniBandデバイスファイルに複数のdevice idを割り振って、どのコンテナでもスケジュールできる自作のdevice pluginを稼働させて、InfiniBandからクラスタを利用している。
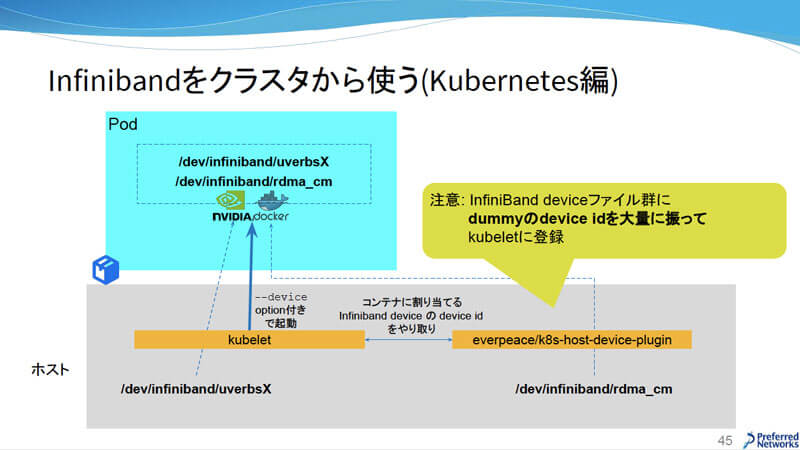
InfiniBandをクラスタから使う(Kubernetes編)
続いて、クラスタ利用・運用効率の要件について解説した。MesosもKubernetesもノードの空きを見つけてジョブを配置する。しかし、配置の仕方によっては後から大きなジョブが来た時に入らない場合がある。そこで、Mesosは独自アルゴリズム、KubernetesはMostResourceRequestedを利用して効率の良い柔軟なスケジューリングを目指している。また、ラックに閉じてコンテナを配置したい、搭載メモリでGPUを指定したいなどの配置制約要求には、ノードとジョブにラベルを付けることで配置制約を指定できるという。
効率の良さと柔軟性だけでなく、公平性も求められている。というのも、他の人のジョブがずっと走っていて自分のジョブが走らないという状況にならないようにするためだ。現在は試行錯誤中で、まだうまく出来ていないとのことだが、スロットルを適用して実行中のGPU数を制限し、必要に応じて上限緩和を実施するなどの取り組みをしているそうだ。

効率よく柔軟なスケジューリング
分散学習ジョブを実行する際、複数のコンテナを一気に配置したいが、スケジューラはコンテナごとに配置するので、デッドロックが発生する可能性がある。そこで、分散学習ジョブを構成するコンテナをまとめてスケジュールし、デッドロックを回避するのがギャングスケジューリングである。Mesosでは独自に実装しており、KubernetesはKubernetes Incubator Projectのkube-arbitratorを適用する予定だという。

ギャングスケジューリング
効率よく柔軟にスケジューリングする話題で出ていたオンラインビンパッキング問題だが、どうしても配置できないケースがある。この場合は、ジョブに優先度を設定してプリエンプションするのが現実解で、公平性にも寄与する。ここで課題となるのがリエントラントだ。プリエンプションされた瞬間の状態で復帰して学習再開するのが理想だが、現状はエポック終了後に保存されるモデルスナップショットを読み込んで学習再開させる形となっている。
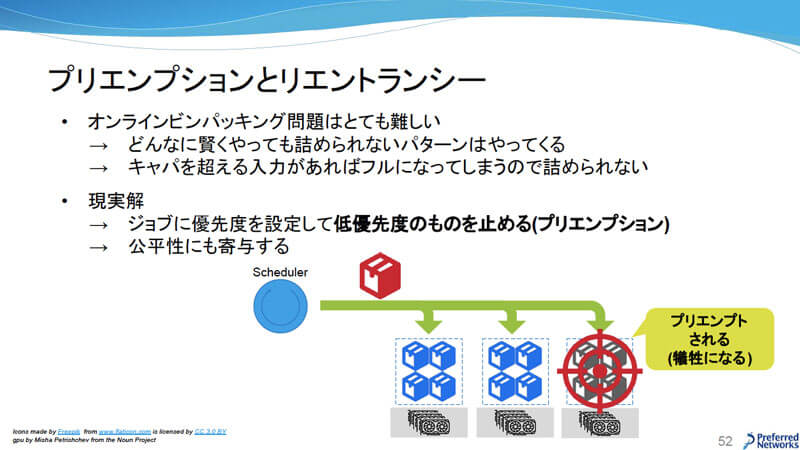
プリエンプションとリエントランシー
大村氏は最後に、将来に向けての展望を4つ紹介した。まず1つ目は、より効率的・柔軟・公平なスケジューラに関するものだ。現在はMesosとKubernetesのサーバは別々で、Mesos側で空いているリソースをKubernetesが使うことはできないし、逆もまた然りだ。そこで、2つのタスクスケジューラをKubernetesに統合してさらなる効率化を図る予定だという。InfiniBandについては、現在アイソレーションしていないが、適切にアイソレーションして適切な帯域を確保できるようにしたいと述べていた。
前述したオンラインビンパッキング問題は、なるべくプリエンプションが発生しないようにジョブを配置できるアルゴリズムの研究を進めるだけでなく、スケジューラに機械学習・強化学習を活用する研究にもチャレンジしたいという。例えば曜日や時間帯によってジョブに傾向があるとすれば、それに特化したスケジューリングを行うことができるのではないか、というわけだ。
さらに、ノード内/クラスタ全体のハードウェアトポロジーを考慮した配置も目指しているそうだ。具体的には、低速なCPU間のバスを介するよりも隣り合うGPUの方が高速であることや、RAMへのアクセス時にコンテンション(競合)が起こらないようスケジューラが考慮して配置する。
2つ目はHybrid Cloudの積極的な活用。現在はオンプレミスのMN-1を使っていることは紹介した通りだが、MN-1に空きがなくジョブが載せられない時は、クラウドを使ってリソース不足を解消する取り組みを検討しているという。
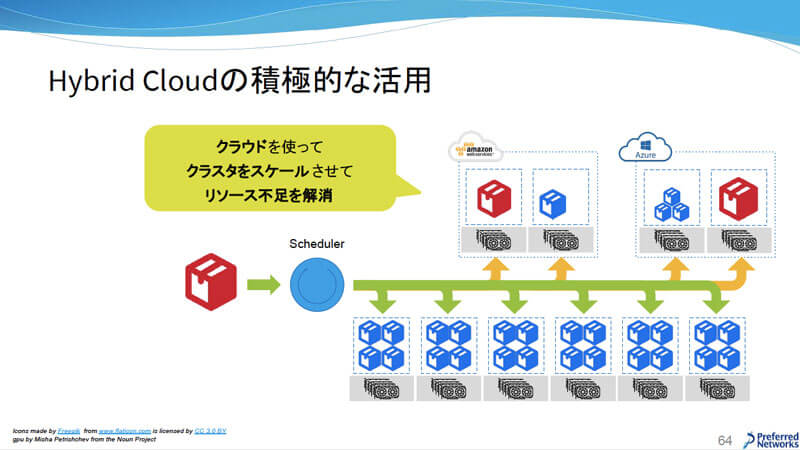
Hybrid Cloudの積極的な活用
3つ目は日常的にグランドチャレンジを行うこと。クラスタが通常運転中にグランドチャレンジのジョブが来たら実行中のジョブを全てプリエンプションし、グランドチャレンジ終了後にプリエンプションしたジョブを再開できる体制を構築したいと述べた。
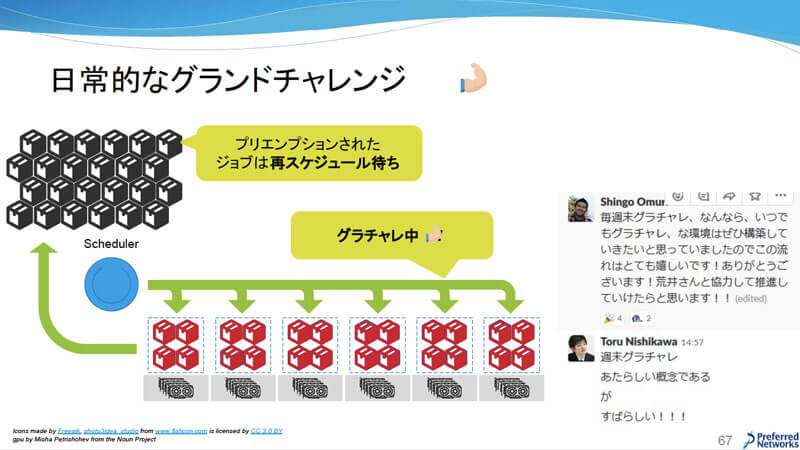
日常的なグランドチャレンジ
そして最後の4つ目が、OSS貢献への加速だ。冒頭で紹介したジョブ内製ツールは、外部に出してこなかった。しかし、開発を開始した約2年半前と状況が大きく変わっており、効率的で柔軟な機械学習クラスタは世界共通の課題となっている。そこで、OSSを活用するだけでなく、積極的に貢献していきたいと展望を語った。
機械学習の計算基盤技術は様々なOSSが登場してきたが、まだまだ発展途上である。現在は並列計算(スーパーコンピュータ)と分散システム(クラウド)の合流点にいて、性質が異なるこの2つをどのようにマージしていくかが重要な課題だ。また、研究・開発のボトルネックは一番貴重な資源、すなわち人間の創造性であるべきで、計算資源にボトルネックがあってはいけない。最強の計算資源で人間の創造性を全開にしたいという想いで、機械学習クラスタのサービスを開発していると述べた。
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
Deep Learning Lab初のエンジニア向けイベント「異常検知ナイト」レポート
2018年5月15日 16:00
Azure+クラウド型電子カルテにおけるリソース利用効率の課題と改善への道すじ
2019年6月13日 6:00
SIの労働生産性を高めるIaCとは?ITエンジニアのためのコミュニティ「IaC活用研究会」キックオフイベントレポート
2018年4月12日 18:40
話題のDockerの魅力とは? OSSインフラナイター vol.1 レポート
2017年7月14日 0:15
ITエンジニア必見の夏の祭典「July Tech Festa 2018」レポート
2018年10月25日 6:00
「FFXV」に活かされたAIとは?「Pokémon GO」に続くARゲームの登場も間近か…日々進化するゲーム業界のAI・ARに迫る
2017年12月5日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
