データベースの性能を向上させるには
連載第2回目となる今回は、データベース性能を向上させるための「スケールアップ型アプローチ」について、ハードウェアとソフトウェア両面から解説します。
2024年3月13日 6:30
はじめに
前回、はデータベースの性能の基本的な考え方について解説しました。今回は、データベースの性能を向上させるためにはどうすれば良いのかについて解説します。
データベース性能向上の方法
前回で解説したように、データベースの性能を左右する(律速する、と言ったりします)のは、ストレージからのデータの読み込み処理と、検索・集計処理です。何かの処理が遅い、すなわちボトルネックになっていると、データベースの性能は劣化します(図1)。

図1:データベースの検索・集計処理でボトルネックになる要素
ボトルネックの解消には、単純に性能を向上させて必要な性能を与える方法と、ボトルネックにならないように処理を変える方法があります。前者は主にハードウェア的なアプローチに、後者はソフトウェア的なアプローチとなります。
ハードウェア的な
スケールアップ型アプローチ
ハードウェア的な性能向上にも、データベースサーバーが動作しているマシンの性能を向上させる「スケールアップ型のアプローチ」と、データベースサーバーの台数を増やす「スケールアウト型のアプローチ」があります。ただし、後者はいわゆるクラスタリングをソフトウェア的に行う必要があるため、ハードウェアとソフトウェアの複合的なアプローチでもあると言えるでしょう。ここではスケールアップ型のアプローチである「ストレージ」「CPU」「メモリ」の性能向上について解説します(図2)。

図2:1台のマシンのハードウェアを強化するスケールアップ型
ストレージ性能の向上
最も起きやすいボトルネックが「ストレージの読み込み処理が遅い」というものです。これまではコストや容量の問題からストレージはHDDが使われることがほとんどでしたが、SSDの低価格化や大容量化したため、データベース用のストレージにSSDが採用されることが増えてきました。これにより、以前ほどストレージそのものがボトルネックになることは減ってきました。
それでも、ビッグデータのような大容量データを高速に読み込むには、きちんと性能設計を行ってハードウェアを選定する必要があります。例えば、サーバー用のSSDでは、低速で安価なSATA接続のSSDと、高速で高価なSAS接続のSSD、さらに高速なNVMe接続のSSDが用意されています。ストレージの単体性能を向上させるだけでなく、RAIDコントローラーを介してRAID 0(実際にはRAID 1+0)のような性能向上を図るRAID構成を取る場合もあります。
CPU性能の向上
CPUの性能は動作クロック数とコア数によって決まります。動作クロック数は若干頭打ちですが、コア数は増え続けている傾向にあります。コア数が増えると、同時に並列処理するデータベース検索・集計処理の数を増やすことができます。検索・集計処理を複数のコアで実行するパラレルクエリなどの技術もあります。CPU性能を向上させるのは、ユーザー数の多いシステムなどには有効なアプローチです。
メモリ性能の向上
メモリの性能は読み書き性能などの違いもありますが、最も影響するのはメモリ容量です。メモリはストレージから読み込んだデータを配置して検索処理を行うバッファメモリや、ソートなどの集計処理を行うワーキングメモリとして使用されます。メモリ容量が増えれば、ストレージからの読み込み回数を減らしたり、大規模なデータの集計処理を高速に行うことができます。ビッグデータ基盤では、すべてのデータをメモリ上に配置してしまう「インメモリデータベース」などのソリューションもあるように、メモリ容量を増やすのも有効な性能向上の手段です。
ソフトウェア的な性能向上のためのアプローチ
ソフトウェア的な性能向上はハードウェアを変更しないで行えるため、運用中に性能が不足してきたような場合に採れる有効なアプローチです。ただし、万能薬というわけでもないので、できるだけ設計や開発の段階で性能要件を確認し、テストを行っておくと良い方法です。
インデックスによる性能向上
「インデックス」は、本で言えば目次や索引のようなもので、必要となるデータがどこにあるのかを素早く見つけることができる方式です。インデックスを使わないとデータの検索は全部のデータを検査する全件検索になるため、インデックスが有効に働くと大幅な検索性能の向上が見込めます(図3)。
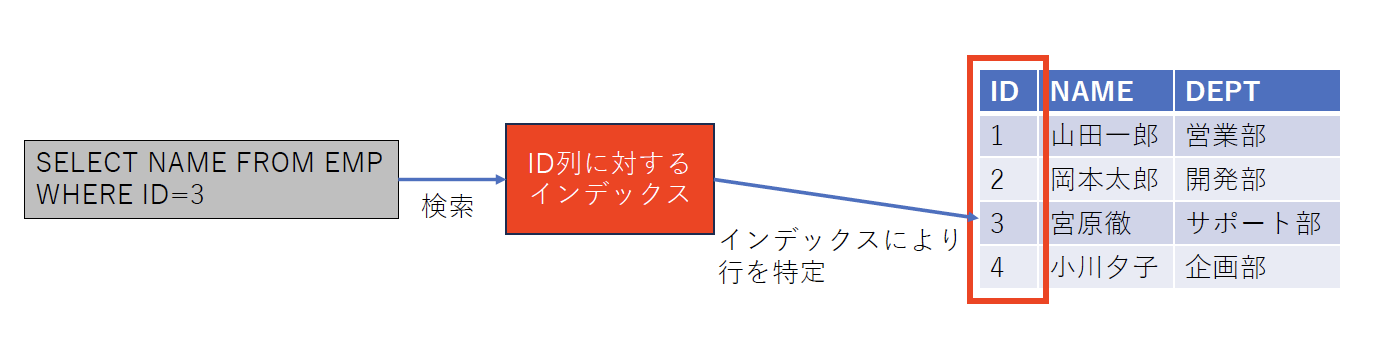
図3:インデックスの動作概念
インデックスの弱点
一見有用に見えるインデックスですが、万能というわけではありません。いくつかの弱点もあります。
・インデックス対象となる列の値のばらつき
インデックスは検索条件の対象となる列に作成します。この列を「キー(列)」と呼びます。キーが取り得る値のばらつき(カーディナリティ)が低いと、対象となるデータが多くなりすぎてしまうため、インデックスの意味がなくなってしまいます。 例えば、コインの裏か表かのような取り得る値が2つしかないものは「カーディナリティが低い」ため、インデックスを作成するよりも全件検索した方が早いということになります。
・データの更新が多いとインデックス再作成が頻繁に必要
インデックスはデータが更新される度に作り直しが必要となります。データ更新が多いと、その都度インデックスの再作成や再構築が必要になります。インデックスの対象となるキーはできるだけ更新されない設計にすることが望ましいでしょう。
パーティショニングによる性能向上
「パーティショニング」は、表のうちのある列の値を使って表の中を分割(パーティショニング)する方式です(図4)。例えば、売上表を売り上げた日付の月で月ごとにパーティショニングしておけば、月次の集計が容易になります。

図4:パーティショニングの動作概念
列指向データベースを利用する性能向上
一般的なRDBMSは更新と検索の両方を行う、いわゆるOLTP(Online Transaction Processing)を主な目的としているため、ビッグデータ処理のような検索重視の処理を行うには内部構造的に向いていません。RDBMSをそのまま使うために、事前に検索だけのために使う「集計表」のようなものを作成しておく手法などもありますが、検索に特化させるのであれば別のソフトウェアを使う手法も考えられます。その際によく利用されるのが「列指向データベース」です。
一般的なRDBはデータを行単位で扱う「行指向データベース」となっており、特定の列だけデータを読み出す場合でも、関係ない列の値も読み出すことになります。これに対して、列指向データベースでは取り扱う必要のある列だけを格納するので、読み出すデータ量が少なくなるなどのメリットがあり、検索・集計処理を高速化できます。
スケールアウト型のアプローチ
マシンの性能を向上させたり、インデックスなどのソフトウェア的な高速化手法ではなく、データベースサーバーのマシンを複数台用意して分散処理を行わせるスケールアウト型のアプローチもよく利用される高速化の手法です(図5)。
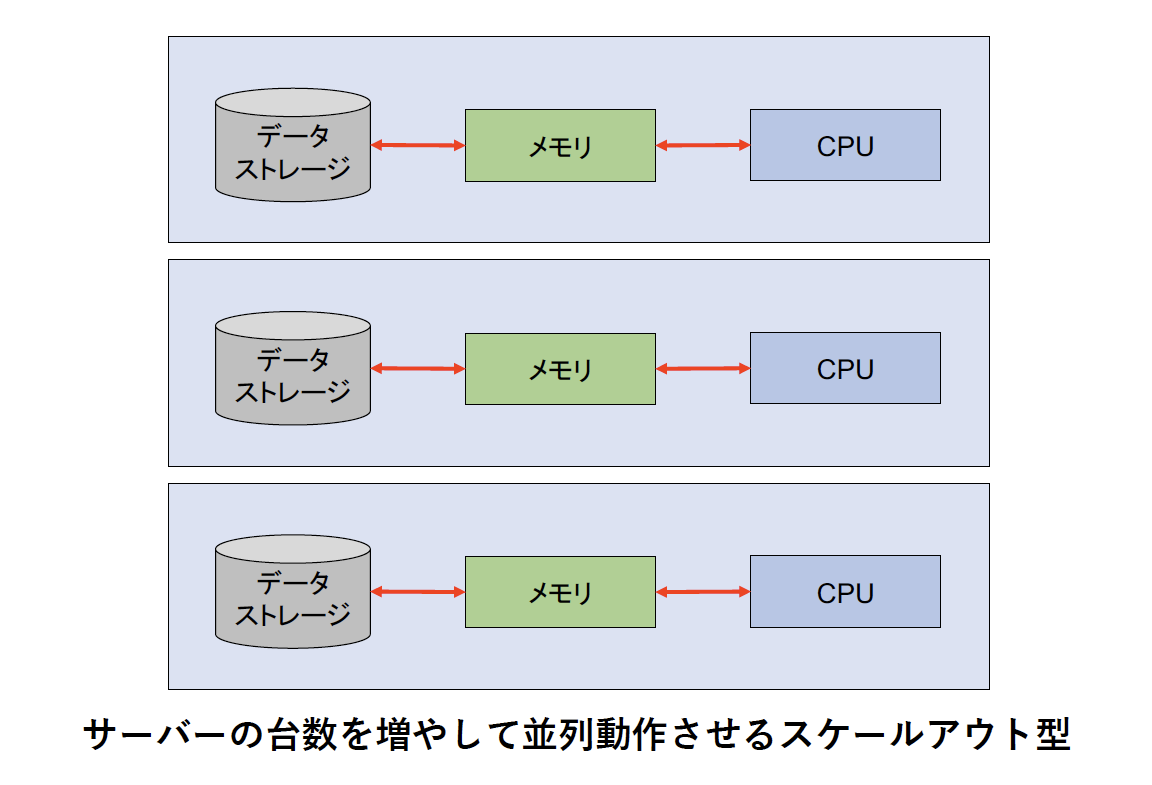
図5:サーバーの台数を増やして並列動作させるスケールアウト型
1つの検索集計処理を複数の処理に分割し、クラスターを構成する各ノードに処理を割り当てて実行させます。1台のマシンでの性能に上限があるような検索・集計処理を高速化することができるので、より大規模なビッグデータ基盤の構築にはよく用いられるアプローチです。
おわりに
今回は、データベースの性能を向上させるには、スケールアップやスケールアウトなどのシステムのアーキテクチャ設計によるものと、インデックスやパーティショニングなどのデータベースそのものの機能によるものがあることを解説しました。
データベースの性能が出ないとき、クラウドであればインスタンスを変更してCPUやメモリを増やすスケールアップで安易に対処しようとしがちですが、インスタンス変更はその分コストアップとなります。まずはなぜ性能が出ないのか、ボトルネックはなんなのかを把握し、適切な対処が必要です。インデックスが有効に働かず、フルスキャンが多発しているのが性能劣化の原因であることも多いので、きちんと見極める必要があるでしょう。
次回は、GPUを活用したデータベース高速化ソリューションである「PG-Strom」が行っている高速化手法について解説します。
この記事をシェアしてください
関連記事
GPUを活用してデータベースを爆速化する「PG-Strom」の仕組み
2024年4月17日 6:30
ベンチマークで「PG-Strom」のクエリパフォーマンスを確認してみよう
2024年5月21日 6:30
Apache Kuduのシステム構成と内部アーキテクチャ
2019年4月17日 6:30
HBase導入時の検討項目と推奨構成、および設計ノウハウ
2017年6月8日 0:15
PostgreSQL 9.6をエンタープライズで使う性能や方法を検証 〜PGECons活動成果発表会開催
2017年6月13日 10:11
分散型データストアApache Kuduの特徴とユースケース
2019年3月29日 6:30
バックナンバー
この記事の筆者

筆者の人気記事
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
