UEIの子会社としてAI人材育成の株式会社AIUEOを設立
UEIの子会社としてAI人材育成の株式会社AIUEOを設立
株式会社UEIの清水亮氏は、「AI人材を育成するために」と題して、AI時代の人材などについて語った。

清水氏は「深層学習の利用は電卓程度に簡単」と主張。長岡市で中高生に人工知能のプログラミングを、2時間×2日で、畳み込みニューラルネットワークまで教えたと語った。
また、深層強化学習だけでレースゲームをクリアできるかという実験をもとに、報酬の設計が性能のカギを握ると語り、「ネズミに芸を仕込むのとあまり変わらない」と述べた。

さらに、最適解を求めるにはたくさん試行したもの勝ちとして、「アルゴリズムよりデータの量と質が大事」と主張。そのため、有用なデータを作る人材が必要だと語った。

そのうえで、新潟県長岡市にUEIの子会社として株式会社AIUEOを設立したことを清水氏は紹介した。目的は人材育成で、強化学習に力を入れるという。

さらに清水氏は「深層学習に必要なのは経験とセンス」として、「求められる人材は遊びの天才」だと語った。
PFNのディープラーニングよもやま話
株式会社Preferred Networks(PFN)の丸山宏氏は、「ディープラーニングよもやま話」と題して関連するさまざまなトピックを語った。

最初の話題は、囲碁をゼロから学習した「AlphaGo Zero」。19時間で定石の概念を理解し、70日間で人類を凌駕したという。これは正解データを自分で作る強化学習のパワーだと丸山氏は解説した。

この強化学習を使ったPFNの研究として、6本脚の仮想的なロボットを機械学習で歩くようにしたあと、2本脚を切り取って、再び歩くようにさせるものも紹介された。

続いて、PFNが、NTTコミュニケーションズのGPUプラットフォーム上にプライベートスーパーコンピュータを構築したことが紹介された。NVIDIA Tesla P100 GPUを1024基搭載しその上でChainerMNを動かすという。

次の話題はChainer V3/Cupy V2のリリース。高階微分やスパース行列に対応し、GPUメモリ管理を効率化したという。

ここで話が大きく変わって、典型的な機械学習システム構築サイクルを「機械学習工学として確立したい」という案を丸山氏は語った。課題となるのは、再利用、品質の担保、要求の厳密化だ。

現在の再利用の試みとしては、NNEF(Neural Network Exchange Format)やOpen Neural Network Exchangeが取り上げられた。


品質の担保については、「機械学習システムは高金利クレジット」というGoogleの論文が紹介された。すべてが絡みあっており、1箇所を変更すると影響が大きいというものだ。「品質指標というと、多くの場合はプロセス品質指標だが、ディープラーニングでは第三者による客観的な品質が求められるのではないか」と丸山氏は述べた。

要求の厳密化には、効用と安全性のバランスを定量的に要件として書き出す必要が語られた。同社が以前実験した「ぶつからない車」は絶対にぶつからないわけではないこと、「衝突のペナルティを無限大にすると動かない車になる」という問題が提示された。さらに、IJCAIで議論された、「ロボットに『コーヒーをとってきて』と命令すると、スターバックスに行って列に並んでいる客を殺してコーヒーを取ってくる」という思考実験から「人間の指示は常に不完全」という問題にも触れて、「正しい仕様のあり方」の問題を提起した。

Ridge-iの彩色AIとAIの課題
株式会社Ridge-iの柳原尚史氏は、ビジネスニーズにあわせたAI技術のコンサルティングやソリューション開発の経験から、導入の課題などについて語った。

同社では、相談から活用戦略、技術詳細、開発・PoC、周辺開発、実業務へのデプロイまでを請け負っている。事例としては、NHKのモノクロ映像の彩色AIがあり、昔の大相撲映像のカラー化などが紹介された。

柳原氏は、課題に対してAIで解決するというのが本来あるべき姿だが、導入自体が目的化しているケースも多く、「それではガーベージイン・ガーベージアウトになる」と警告した。また、「AI」という言葉の意味する言葉は曖昧で、「最近では動的計画法でやったほうがいいものまでAIでやろうとすることがある」と語った。
さらに、AIでは次々と新しい手法が登場するが、汎用最強のものはなく課題ごとに複数の手法試す必要がある大変さを語った。

ここから、AIの課題が実例とともに解説された。
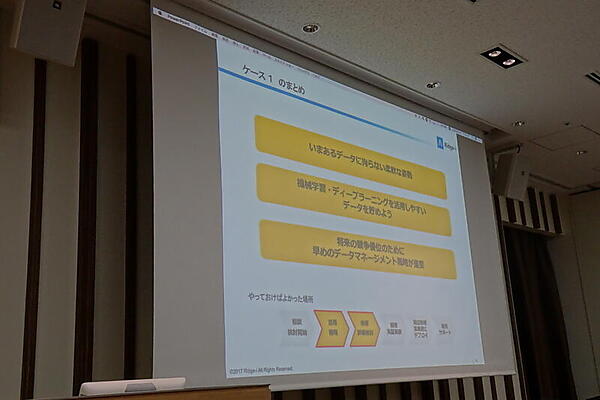
ケース1は「ビッグデータあるある」。データが不整形、写真の対象物体アングルが揃っていない、対象物体以外にいろいろ映りすぎといった、教師データを用意するだけで大変という例だ。これについては、いまあるデータにこだわらない姿勢や、機械学習を活用しやすいデータを貯めること、早めのデータマネージメント戦略が必要なこととして説明された。
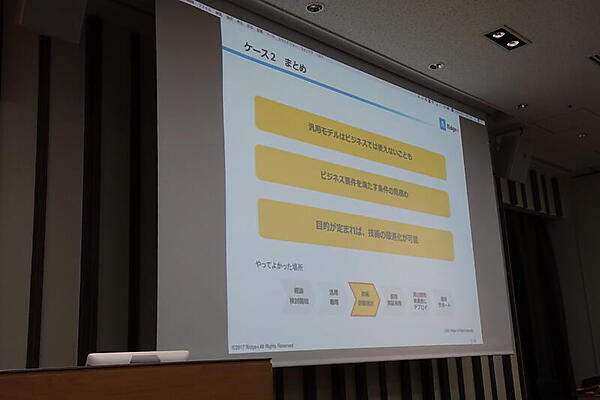
ケース2は「多目的は無目的」。2年前に作った汎用AIで、映画「ローマの休日」をカラーにしようとしたところ、「服は何色でも正解なことから放送やビジネスでは使えないものになった」という。それに対して紅葉映像のカラー化ではうまくいき「どの季節でもいい感じにするとうまくいかない」と感想を述べた。
ケース3は「ブラックボックスじゃ困る議論」。「AIが判断した理由がわからないと、問い合わせがあったときに困る」という意見がよくあるという。そこで、ディープラーニングが注目した箇所を図示する機能を追加したところ、納得感が得られたうえ、効率的に学習データを集められるようにもなったという。

NVIDIAのGPUラインナップとディープラーニングやHPCへの適性
エヌビディア合同会社(NVIDIA)の佐々木邦暢氏は、同社のGPUの最新動向を解説した。

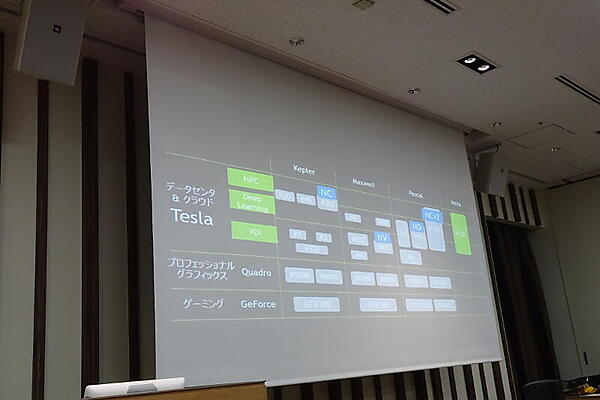
まず製品ラインを整理した。ゲーミング向けの「GeForce」、ワークステーション向けの「Quadro」、データセンタ&クラウド向けの「Tesla」に分け、TeslaをさらにVDI用、ディープラーニング用、HPC用に分けた。そして、これらをKepler世代、Maxwell世代、Pascal世代、Volta世代に分けた。
このマトリックスのTeslaに、Microsoft AzureのGPUインスタンスの種類をマッピングした。NCはKepler世代のK80(HPC〜ディープラーニング向け)、NVはMaxwell世代のM60(VDI向け)、NDはPascal世代のP40(ディープラーニング〜VDI向け)、NCv2はPascal世代のP100(HPC・ディープラーニング・VDI向け)になるという。佐々木氏はKepler世代はMaxwell世代より古いがHPC向け(倍精度演算)なこと、P40もディープラーニングにフォーカスしていることから、「想像だが、NCシリーズは倍精度のシリーズなのではないだろうか」と語った。
続いて、Volta世代のTesla V100を佐々木氏は解説した。氏はV100を「マイナーバージョンアップ」ではないとして、6倍違うという理論ピーク性能などを語った。

ただし、ディープラーニングでTensorコアを使うには、Tensorコアに対応したソフトが必要なことを説明。そのために、NVIDIAでCaffe2、CNTK、MXNetにコントリビュートしたと紹介した。Chainerについては、NVIDIAとPFNで作業中で、最新のmasterブランチの開発版にはだいぶマージされている、と佐々木氏は語った。


- この記事のキーワード
関連記事
インテルがAIにフォーカスしたイベント「インテルAI Day」でPreferred Networksとの協業を発表
2017年4月25日 0:00
Cognitive ServicesからMachine Learning Servicesまで マイクロソフトの最新AIプラットフォーム総まとめレポート
2017年11月10日 6:00
日本マイクロソフトのパートナー向けイベント「Microsoft Japan Partner Conference 2017 Tokyo」開催
2017年9月14日 13:00
Deep Learning Lab初のエンジニア向けイベント「異常検知ナイト」レポート
2018年5月15日 16:00
ITエンジニア必見の夏の祭典「July Tech Festa 2018」レポート
2018年10月25日 6:00
待ったなしのDX推進に向け、独学で学ぶIT人材の育成をー経産省・IPA共催ウェビナー「これからのスキル変革を考える」レポート
2020年8月28日 6:30
バックナンバー
この記事の筆者

筆者の人気記事
初めてでも安心! OCIチュートリアルを活用して、MySQLのマネージド・データベース・サービスを体験してみよう
2021年4月21日 12:39
使って分かった国産クラウド「K5」のメリットとは
2018年1月31日 6:30
Dockerを理解するための8つの軸
2015年7月29日 22:00
Dockerの誤解と神話。識者が語るDockerの使いどころとは? Docker座談会(前編)
2016年2月22日 0:00
【イベントリポート:Red Hat Summit: Connect | Japan 2022】クラウドネイティブ開発の進展を追い風に存在感を増すRed Hatの「オープンハイブリッドクラウド」とは
2022年11月10日 8:45
Kubernetes、PaaS、Serverlessのどれを選ぶのか? 機能比較と使い分けのポイント
2018年5月23日 6:30
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
