KubeCon+CloudNativeCon Europe 2026開催。併設のカンファレンスからAIに特化したセッションを紹介
KubeCon+CloudNativeCon Europe 2026が3月に開催された。併催のカンファレンスからAIに特化したセッションを紹介する。
6月5日 6:00
オープンソースにおけるヨーロッパ最大のテクニカルカンファレンス、KubeCon+CloudNativeCon Europe 2026が、2026年3月23日から26日までオランダのアムステルダムで開催された。4日間の会期のうち、初日は複数のミニカンファレンスが併催されるが、今回筆者は「Cloud Native AI + KubeFlow Day」を選んで参加した。その中からAIワークロードの分散スケジューリングを行うllm-dに関するセッションと、このミニカンファレンスのスポンサーとなったベンチャー企業のセッションをまとめて紹介する。
llm-dに関するセッション

冒頭の挨拶で紹介された生成AI向けのCNCFプロジェクト。サンドボックスとしてホストされているものもある
カンファレンスの最初に登壇したRed HatのYuan Tang氏とBroadcomのRajas Kakodkar氏は、CNCFのプロジェクトとして生成AIに関係するものを紹介。分散スケジューラーであるllm-dやVolcanoなどが挙げられ、両者がこのミニカンファレンスのターゲットとなっていることを示している。

ミニカンファレンスだが2トラックでセッションを進行するスケジュール
ミニカンファレンスでありながら、2つの会議室で並行的に進行されるほどにセッション数が多いことにこのカンファレンスに対する興味の大きさを感じることができた。

分散型で推論を実行するFederated llm-dのセッション
最初に紹介するのはIBM ResearchのシニアエンジニアとElotlのCEOが解説するllm-dに関するセッションだ。

llm-dの概要を解説
llm-dは2026年3月24日に投稿されたCNCFのブログで、サンドボックスプロジェクトとしてホストされることが発表されたソフトウェアだ。
●参考:Welcome llm-d to the CNCF: Evolving Kubernetes into SOTA AI infrastructure
このブログでも解説されているように、llm-dはKServeとvLLMの中間に位置するソフトウェアで、AIに適したトラフィック制御、Kubernetesに適応したオーケストレーション、推論実行の分散処理などを管理する機能を持っている。これまではモデルの学習に関してGPUの最適な利用が大きなテーマになっていたが、大規模言語モデルの開発が少数の特化したベンダーによって先鋭化するに従って、生成AIのユーザーであるエンタープライズ企業ではいかに推論を効率化するか、高速化するかという点に興味が移ってきていると言える。その流れの中、クラウドネイティブなシステムのデファクトスタンダードであるKubernetesで、機械学習だけではなく推論実行をサポートするオープンソースソフトウェアが多数出現している。llm-dもその一つで、このセッションではllm-dが推論ジョブを分散させる機能について解説している。
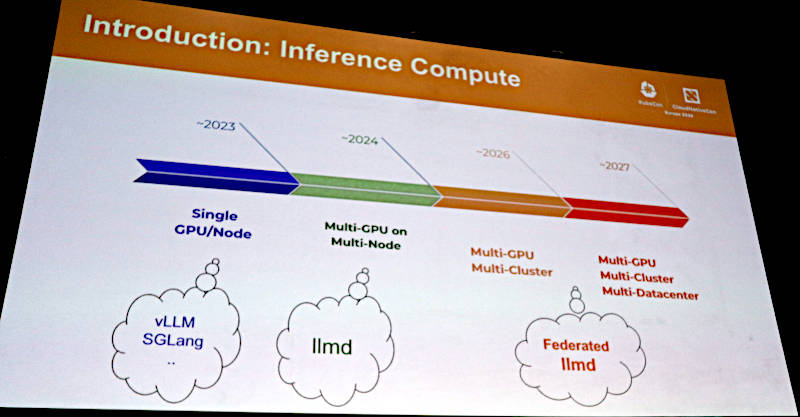
推論の実行環境の変化について解説。シングルGPUからマルチクラスター、マルチデータセンターに移行
このスライドではこれまで単一のGPUで実行されてきた推論ジョブが、複数のGPUサーバーを使って実行されるように変化していると説明。そのためにはクラスターやデータセンターをまたいでジョブを実行、制御する仕組みが求められるようになったことを説明し、それがFederated llm-dであると解説した。

Federated lm-dのコンポーネントを解説
推論ジョブを分散処理するためにはさまざまなコンポーネントが必要になるとして、Ciliumによるクラスターメッシュ、Inference Pool、KubernetesのGateway APIによるHTTPRoute、そしてNovaと呼ばれるスケジューラーが紹介されている。
ここからはElotlのCEOであるMadhuri Yechuri氏が解説を行った。
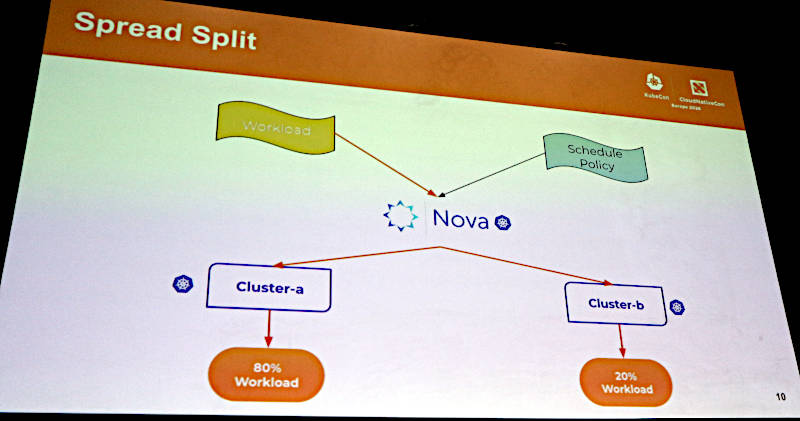
Novaによる推論ジョブのスケジューリングを解説
この例では、スケジューリングのポリシーに従って2つのクラスターにジョブが8:2の割合で分散されていることが示されている。デモは動画を使って行われた。デモとして使われた動画はElotlの公式動画で確認ができる。
●参考:Federated llmd
この動画には音声がなく、使い方としてはプレゼンテーションの中で補足するというスタイルのためややわかりにくいが、2つのクラスターにジョブが割り振られていることがコマンドとGUIによって確認できるという内容だ。

動画によるデモを見せながらllm-dがジョブを分散させるようすを解説
このセッションで見せた内容を振り返り紹介。クラスターを緩く連携させる方法で実現されていること、オブザーバビリティについてはCilium Hubble、Cilium Tetragonによって実装されていることを説明。

将来計画についてのスライド
最後にFederated llm-dの将来計画について解説。よりタイトに結合されたクラスターで実装すること、ポリシーに応じたトラフィック制御などが予定されているようだ。セッション終了後にMadhuri Yechuri氏にNovaというスケジューラーについてOpenStackのNovaと同じソフトウェアか? という質問を行ったところ、OpenStackのNovaとは関係がなく、同じ名称のオープンソースプロジェクトがあることは知っていたが、社内の開発チームでOpenStackを知っているエンジニアがいなかったところからNovaと命名してしまったという回答を得た。「これに関しては私のミスね」と笑いながら答えてくれた。
複数のスポンサーによるプレゼンテーション
このセッションの後にスポンサーであるSpectro Cloud、Vultr、NEBIUSからのプレゼンテーションが行われた。

Spectro Cloudのプレゼンテーション。
ここではGPUクラスターにKubernetes、KServeなどを使ったクラウドサービスを提供していることが解説されている。Spectro Cloudについては2023年のKubeCon EuropeでエッジにおけるKubernetesの実装に関してインタビューを行っているので参考にして欲しい。
●参考:エッジでKubernetesを実装する新しいプラットフォームをIntelとSpectro Cloudが紹介
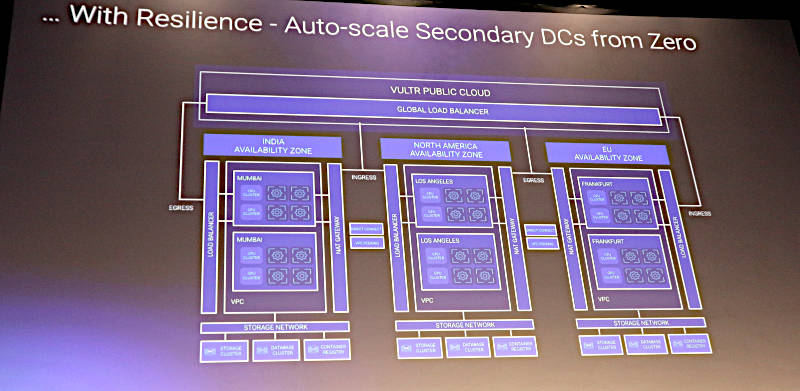
VultrもGPUクラスターをグローバルに展開するサービスを紹介
VultrもクラウドサービスとしてGPUを使ったAI実行がグローバルに展開できることを特徴として紹介。
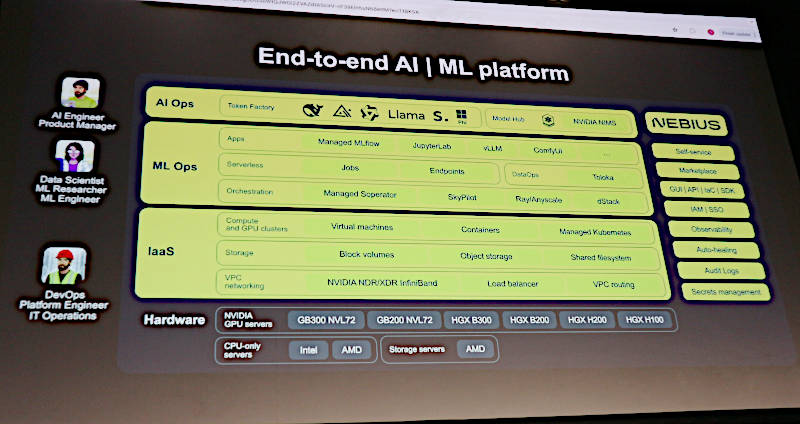
NEBIUSのNVIDIAサーバーを使ったクラウドサービスを紹介
NEBIUSもSpectro Cloud、Vultrと同様にGPUサーバーをクラウドサービスとして利用可能であることを訴求していた。
人工知能のコアの部分ではなく、いかにこれまでと異なるワークロードをクラウドネイティブに実装するか? という視点でKServe、llm-d、vLLM、Volcano、KAITOと言ったプロジェクトが解説されていたのは、AIのデファクトスタンダードプラットフォームを自称するKubernetesのカンファレンスらしい内容だったと言える。また新興のベンダーが競い合ってGPUサーバーをサービスとして提供するビジネスに乗り出しているのは、GPU自体の調達が難しいことに加えて企業側の需要が高まっていることの証拠だろう。ヨーロッパのソブリン(デジタル主権)に関する規制なども注目されていることを感じたセッションとなった。
- この記事のキーワード
この記事をシェアしてください
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
