SIGGRAPH Asia 2025、Wayveの合成データによる強化学習に関するキーノートを紹介
SIGGRAPH Asia 2025からWayveの合成データによる強化学習に関するキーノートを紹介。
4月13日 6:00
SIGGRAPH Asia 2025で行われた合成データを使った生成AIモデルのトレーニングに関するキーノートセッションを紹介する。
Wayveはケンブリッジ大学のPhDの学生だった2人のエンジニアによって2017年にロンドンで創業された自動運転のためのソフトウェアを開発するベンチャーだ。今回のキーノートはWayveのチーフサイエンティスト、Jamie Shotton氏による自動運転のための学習に必要なデータをどうやって用意するのか? という問いに答える内容となった。
これも「低空域ドローンがどうしてSIGGRAPH Asiaのセッションとして採用されるのか?」という問いと似ており、自動運転のための学習データを実車による実験の中で獲得するのではなくコンピュータ上に生成された3次元の世界モデルに車体を置いて様々な条件を再現してシミュレーションすることで学習を効率的に行うことが必要というのがShotton氏の主張である。
この3次元の世界モデルを実現するための手段としてNeRF(Neural Radiance Fields)や3DGS(3D Gaussian Splatting)を使うという部分にコンピュータグラフィックスが大いに利用されることでSIGGRAPHにおいては大いに関係のある内容であるということだろう。
車体が置かれる世界をコンピュータ上に再現し、そこに天候や障害物などを再現して故意に事故を起こすことで現実には再現することが難しい状況に対する対応を学習させることが目的だ。これによってゼロショット問題(AIが何も学習していない状態で適切な回答を生成する課題)に対応すると同時に学習の効率を高めるというのがWayveの方法論である。
●公式サイト:Wayve

セッションのタイトルである「Worlds we make:The Rise in Synthetic Data in AI」でほぼ言いたいことは伝わるが、日本語で要約すると「私たちが作る世界:生成AIにおける合成データの利用の拡大」に関する内容ということになる。

このスライドではコンピュータグラフィックスが機械学習と重ね合わさることで機械学習は実体のあるAI、身体性AI(Embodied AI)に進化し、さらに実体のあるAIが合成データを利用することでさらに進化が進むという内容が解説されている。
そこでShotton氏が過去を振り返る例として挙げたのはMicrosoftのKinectだ。これは2009年にMicrosoftが発表した当時はProject Natalと命名されたプロジェクトで、その後XBoxのモーションキャプチャーのデバイス、Kinectとして商品化された。

このプロジェクトが発表された当時に求められた要件にはどんな体形でもキャプチャーできること、キャリブレーションが不要であること、XBox 360で動くこと、2010年のクリスマスシーズンまでに出荷することなどが挙げられており、当時でも野心的なプロジェクトであったことが分かる。

その要件をクリアするために人体のイメージデータから手や脚などの部位の判定と関節の特定からスケルトンモデルへの変換などが必要であったことを解説した。
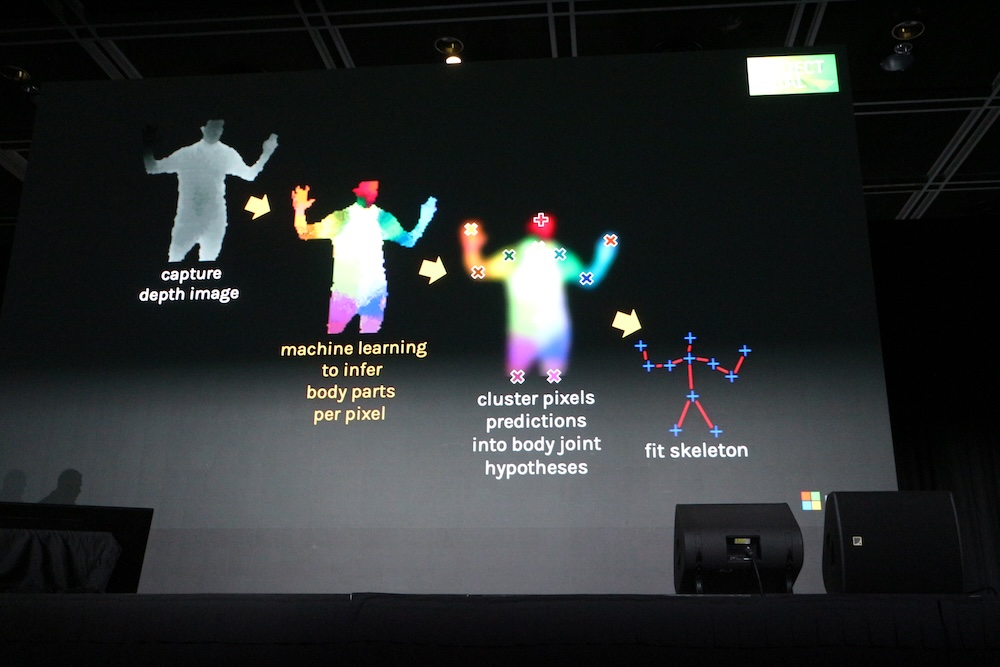
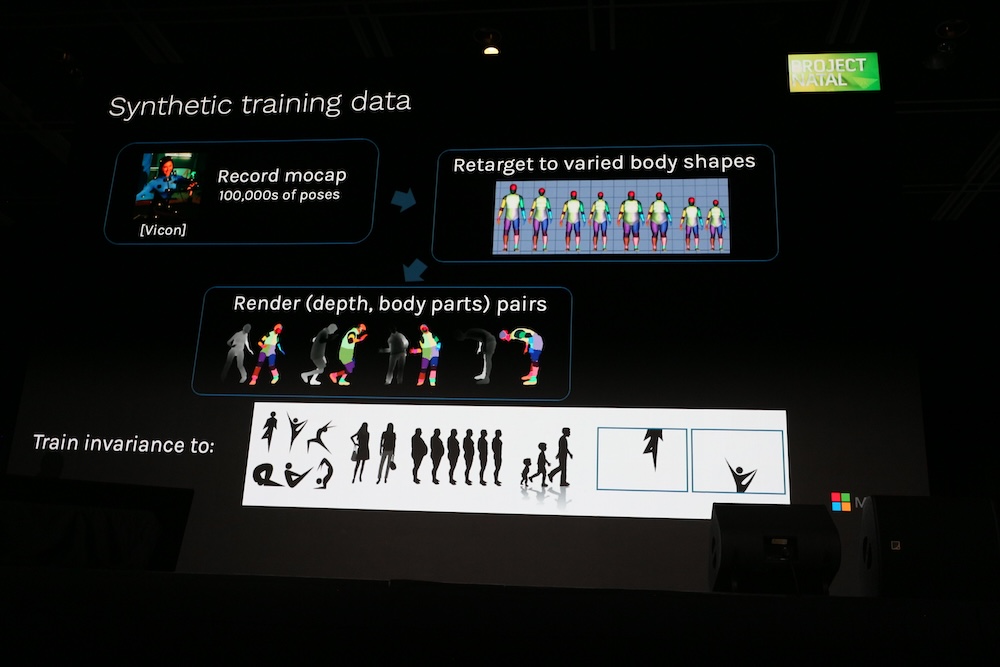
その際に多くの体形を学習する必要があり、そこに合成データが活用されたことを説明した。
ここで深度を持ったイメージデータから3次元のモデルに変換されるまでの流れを紹介している。

Kinectでの経験をShotton氏的に解釈すると「機械学習がコンシューマー向けの製品に使われ、成功したこと、深度センサーが一般的になったこと、合成データによる学習が必須だったこと」が、Project Natalにおいては重要だったことである。つまり実データだけでは学習の速度が上がらないが実データを合成することで大量の学習データを作成でき、それが機械学習プロジェクトにおいては必須だというメッセージである。

2000年代初頭から多くの研究によってシミュレーションを機械学習に応用する論文が多数公開されていることも紹介し、ここから導き出された結論を紹介した。

ここではシミュレーションに必要なリアリズムが合成データによって実現できるようになったこと、実データとは異なり、属性を示すラベルを作成する手間がないこと、スケールさせるためのコストが低いことなどを挙げた。その結果、Wayveは自動運転のために合成データを使うようになったということだろう。
そしてWHOのデータを示して路上での死亡事故は年間135万人にも上り、交通事故が5歳から29歳の死亡要因として最も多いこと、歩行者、自転車やバイクのライダーが死亡者の約半分を占めていることなどを挙げ、これを自動車側の視点で避けるためにはどうしたら良いのか? を解説した。

歩行者に車輛の重さと移動スピードの乗算されたパワーで車輛が衝突することで結果として死亡してしまうのであれば、自動車がどうやって歩行者や自転車などを避けるのか? は大きな課題だ。自動運転をニューラルネットワークと合成データを使う研究も紹介し、ここからWayveの自動運転システムの解説に移った。
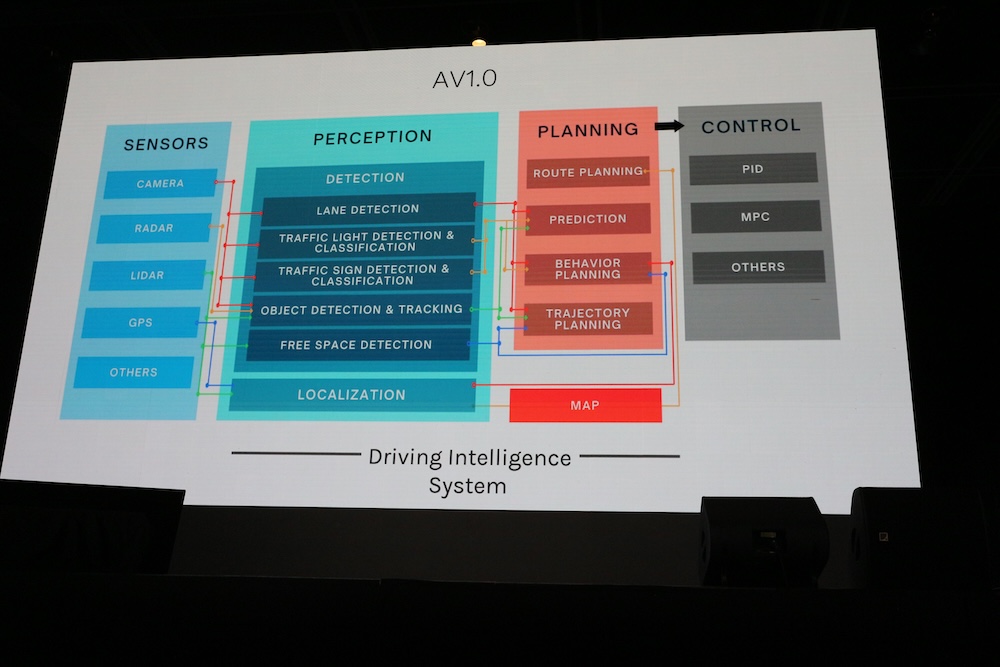
ここでは1つ前のモデル、AV1.0のシステムダイアグラムを紹介。このバージョンでは認知(Perception)と計画(Planning)が分離されており、処理が遅く、実装のコストも高く、スケールしない設計だったと説明。

そこから機械学習に移行するポイントとして近代的なAIの要素を解説。ここではデータセット、シミュレーション、強化学習などが挙げられている。

そして、ここまでの結論として自動運転は身体性AIを実現できるか? という問題であることを解説した。

そして、そこから自動運転システムの次バージョン、AV2.0を紹介。ここではセンサーから受け取ったデータをベースにして機械学習を行い、車輛の制御に繋がるというシステムになっている。1.0では認知と計画が別のステップになっていた部分をニューラルネットに置き換えて一体化したということだろう。
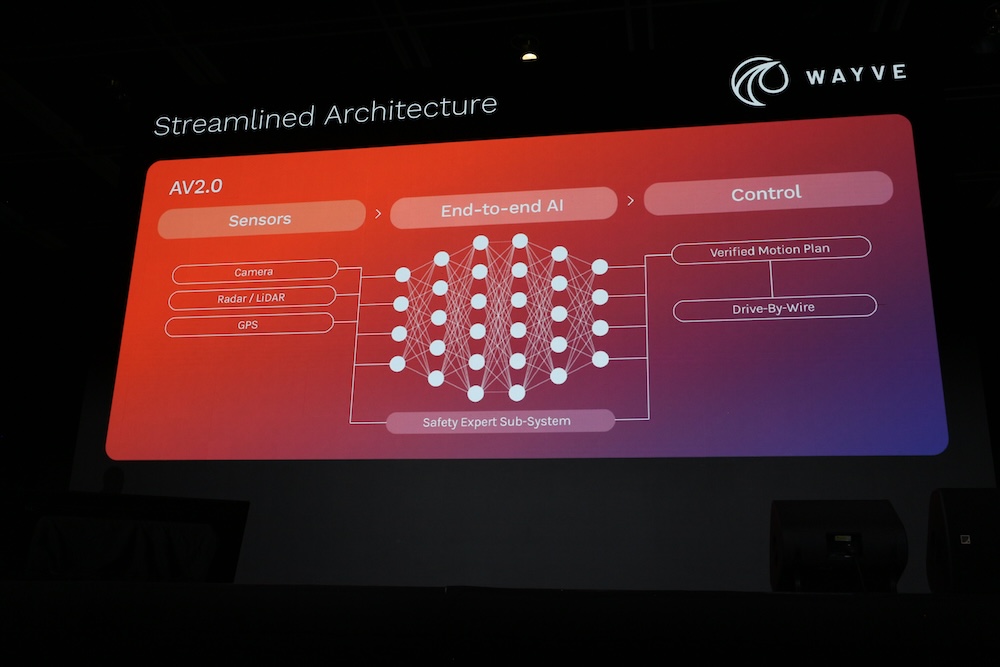
興味深いのは安全性に関する部分はサブシステムとしてガードレイル的に制御をオーバーライドするような仕組みになっていることだろう。
機械学習によるシステムに置き換えたことでイギリスとアメリカのように車道が右左違う場合でも素早く対応することが可能になったことも説明した。
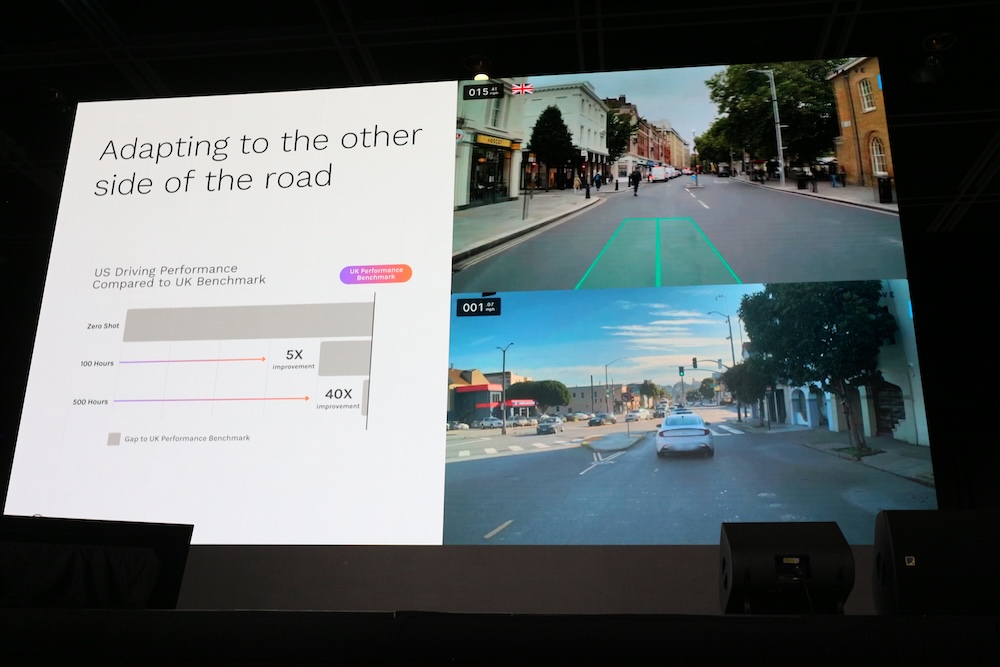
このスライドではゼロショットの場合は多くの間違いを起こすが、訓練の時間を多く積むことで左右の違いがベンチマークに対して成果が大きく改善したことを示している。
Wayveは日本の道路データでも試験を行っていることを示し、2025年12月10日に発表された日産とWayveの提携も紹介。これは日産の次世代の自動運転システムにWayveのテクノロジーを応用していくことを発表したものになる。

●参考:日産とWayve、次世代運転支援技術の量産車への搭載に向けた協業契約を締結
ここで身体性AIがスケールするシステムとして完成に近付いてることを説明した。シンプルなアーキテクチャーと地理データの応用などがポイントとして挙げられているが、AV2.0によってシンプルになった機械学習システムがポイントだろう。
次のスライドでは、身体性AIに関する問題提起としてリアルなデータを使った学習の課題を紹介。

遅く高価となってしまうこと、再現性が低いこと、極端な例がすくないこと、危険な状況を発見できないことなどを挙げた。
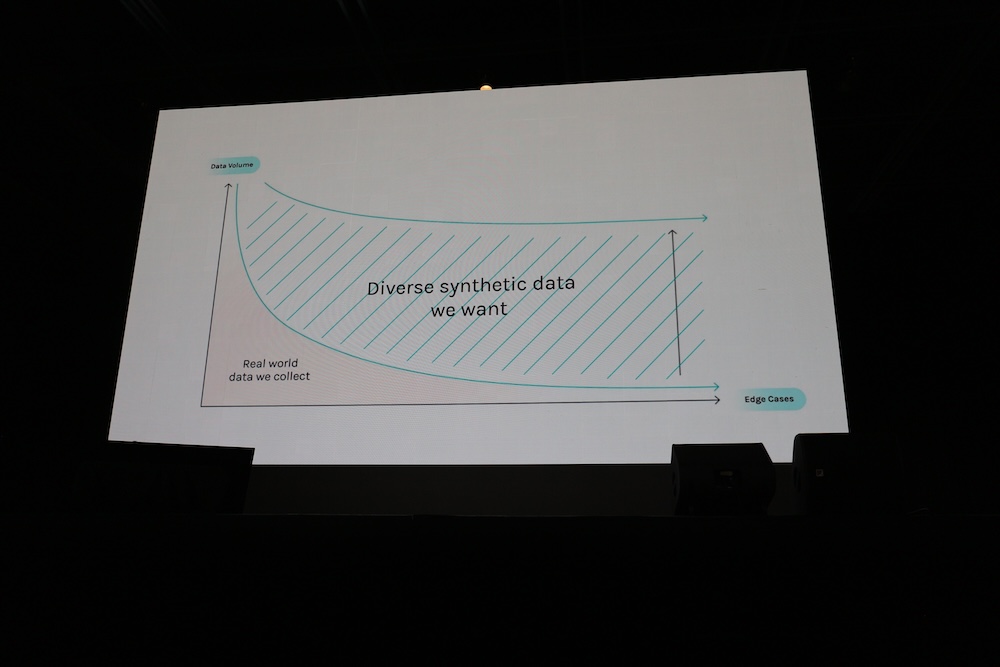
このグラフではリアルな実走データだけでは危険で複雑な要因がからむ状況を作りえないことを説明している。
それでは、それをどうやって解決するのか? を整理したのが次のスライドだ。

どのモードでもリアリティがあること、様々な状況を作り得ること、物理の作法に従ったシミュレーション、動的に状況を変化させられること、制御が容易であることなどが挙げられている。右上にある「GT labels less important」はGround Truth(GT)つまり現実世界における物体の属性情報はここではあまり重要ではないことを敢えて挙げていると思われる。

ここで紹介されたWayveのInfinity Simulatorでは道路と日照、天候などを高いリアリティを持った3次元コンピュータグラフィックスで実現しているとして、リアルな実走データに劣らない品質とダイナミックな状況変化を実現できることを主張している。
ここで強化学習のシンプルな解説を行い、環境を観察し、行動を起こした結果の評価をリワードとして与えることでより良い結果を収束していくことを語った。AV1.0の「認知と計画」を強化学習の「観察~行動~リワード」のループで置き換えたことを意味していると思われる。
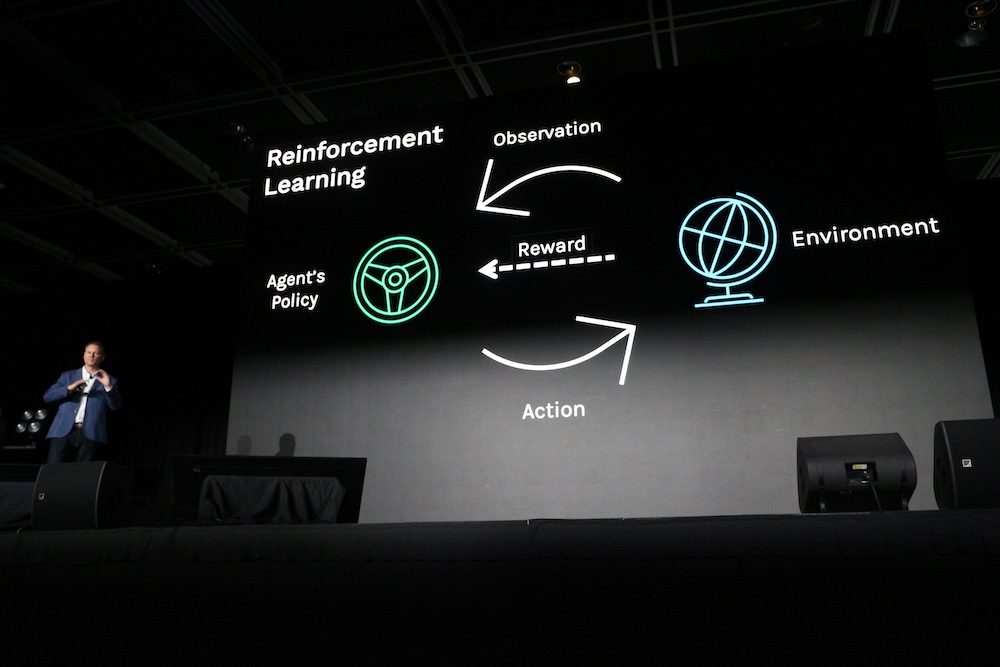
そしてWayveのシミュレーションでは仮想の道路において様々なエージェントを使って状況を作成し、強化学習を行っていることを紹介。

また、リアリティを追及した3次元モデルを作成するためにNeRF(Neural Radiance Fields)や3D Gaussian Splatting(3DGS)を使っていることも紹介。ここでやっとSIGGRAPHらしい単語が出てきたと言える。

ただし世界を構築するモデルについてはGAIA-1からGAIA-2へと進化していることを紹介。自動運転のシステムが1.0から2.0に進化したことと同様に常に改善が行われていることの意思表明といったところだろうか。
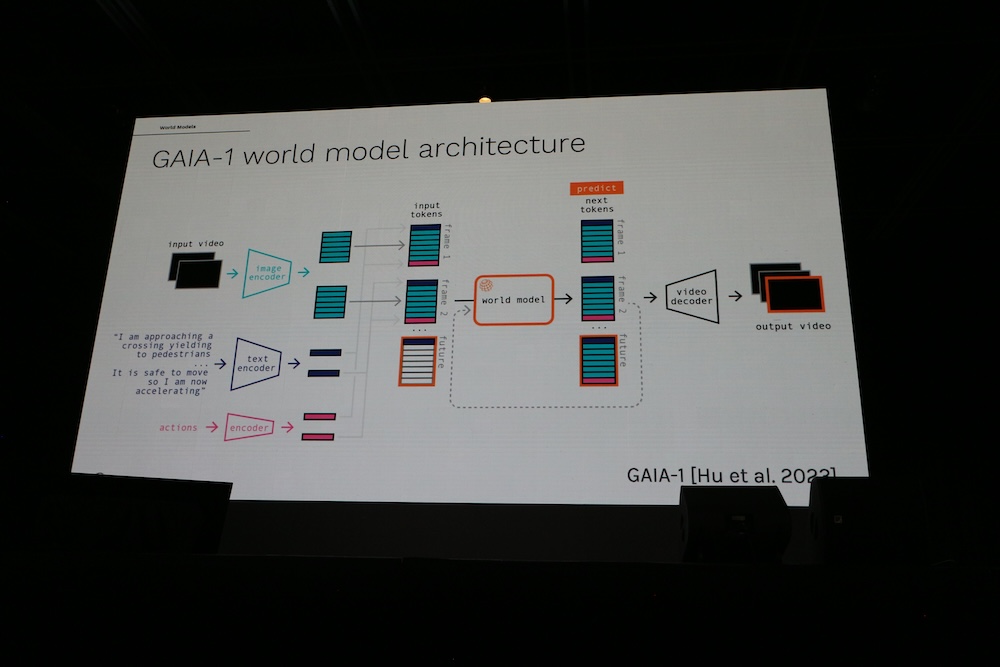


GAIA-2に関しては下記、arxivの論文を参照されたい。
●参考:GAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving
GAIA-2によるシミュレーションでは歩道の再現もかなり高いリアリティで行われていることが紹介された。これは日本の道路のシミュレーションであるが、歩道にある看板の文字が意味不明であるものの降雨時の歩道の状況をシミュレーションするという目的には沿っていることが分かる。

そして生成AIによる世界モデルこそが自動運転のシミュレーションモデルとして最適であることを解説。

最後に結論として合成データが実体を持ったAIにとっては重要、そのための世界モデルを生成AIで作ることが必要、観察と行動を改善するためのリワードをどうやって設計するのか? に大きな将来性があることを解説してセッションを終えた。

実体のあるAIにとって合成データが重要な役割を果たすことをKinectの経験から紐解き、最後はよりリアリスティックな世界を生成AIを使って生成することがシミュレーションにおいては要点であることを解説したが、先行するWaymoのLiDARを使った自動運転システムとの違いなどは特に解説されることなく自社の宣伝が主だったことが残念だった。自動運転そのものではなくリアルな実験データよりも合成データが重要であることに念を押した形になったが、研究者ではなく企業内のサイエンティストとしてはこれが精一杯ということだろう。
この記事をシェアしてください
関連記事
SIGGRAPH Asiaに参加した北大の小川教授にインタビュー。暗黙知をAIに実装する試みとは?
4月20日 6:30
AAAI-26のInvited Talkから、Sony AIのPeter Stone氏のセッションを紹介
4月15日 6:00
GPUをフル活用するためのカンファレンスGTC 2019、サンノゼで開催
2019年4月16日 6:00
KubeCon China 2024、GPUの故障を検知するOSSを解説するセッションを紹介
2024年11月27日 8:06
Community Over Code Asia 2025からByteDanceが開発したTRAEを紹介
2025年11月6日 6:00
エッジコンピューティングのFastlyの共同創業者にインタビュー。生成AIを高速化する仕組みを解説
2025年7月18日 6:00
バックナンバー
この記事の筆者

筆者の人気記事
SASEのCato Networks、CEOによるセミナーとインタビューを紹介
2020年4月16日 6:00
Rustのエコシステムの拡がりを感じるデスクトップアプリのためのツールキットTauriを紹介
2022年12月16日 6:00
Zabbix式オープンソースの秘密に迫る
2025年1月31日 6:00
WebAssemblyとRustが作るサーバーレスの未来
2020年4月21日 6:00
三菱電機が設立したOSPOのメンバーにインタビュー。「インナーソース」を戦略的に使う背景とは?
2025年10月3日 6:00
エンタープライズLinuxを目指すSUSE、Red Hatとの違いを強調
2015年2月3日 19:00
Think ITでは、技術情報が詰まったメールマガジン「Think IT Weekly」の配信サービスを提供しています。メルマガ会員登録を済ませれば、メルマガだけでなく、さまざまな限定特典を入手できるようになります。
